스테이블 디퓨전을 사용해 인공지능 이미지를 생성하다보면 마음에 안드는 이미지도 많이 생성되기 마련입니다. 전체적으로 구도가 마음에 안든다면 버려야겠지만, 얼굴이나 옷 색깔과 같이 일부분만 마음에 안들 경우에는 인페인트 기능을 사용해 그 부분만 새로 그릴 수 있습니다.
이 글의 목차는 아래와 같습니다.
- 소프트웨어 설정
- 인페인트 기본 예제
- 인페인트의 원리
- 인페인트 매개변수 설정
- 인페인트 전용 모델
- 콘트롤넷 인페인트
- 자동 인페인트
- SDXL 모델의 인페인트
- ComfyUI에서의 인페인트
소프트웨어 설정
이 글에서는 스테이블 디퓨전 용 AUTOMATIC1111 웹UI를 사용합니다. 원래 Mac에서도 사용할 수 있고, 구글 Colab에도 설치할 수 있지만, 저는 윈도에서 설치하는 방법만 정리했습니다. 스테이블 디퓨전에 대해서 좀 더 알고 싶으시다면 스테이블 디퓨전에 관한 기본적인 이론 부터 읽어보시는 것이 좋습니다.
인페인트 기본 예제
먼저 txt2img를 통해 기본이 되는 이미지를 생성해 보겠습니다. 이러한 프롬프트를 작성하기 위한 방법은 이 글을 읽어 보시기 바랍니다.
모델: Realistic Vision v5.1
프롬프트: full body, audrey hepburn, black hair, 18 years old, 1940’s, photoshoot, Fujifilm XT3 Viltrox, posing, instagram, happy smile, stand up, ultra detailed, sharp focus, elegant, jewels, urban background, rim lighting, short beige dress, beige kitten-heels, black gloves, pearl tiara, pearls necklace, brilliant pearl earrings, hdr, high contrast, sunlight, , shadows, skin pore, pretty, beautiful, feminine, loving, in love, adorable , fashion, chic, excellence, leg, dress
부정적 프롬프트: ugly, deformed, nsfw, disfigured
CFG 척도: 7
이미지 크기: 512x768
여러가지 이미지를 생성했는데, 그중에서 얼굴이 별로 마음에 안드는 것을 하나 선택했습니다.

이 이미지는 얼굴의 크기가 작아서 균형이 맞지 않는 단점이 있습니다. 다행히도 인페인트를 사용하면 이를 수정할 수 있습니다. 생성된 이미지 아래에 있는 버튼 중 팔렛트 모양의 버튼을 누르면 이 이미지와 프롬프트 등이 모두 img2img->inpainting 탭으로 전달됩니다.

페인트브러시 도구를 사용해서 얼굴에 마스크를 그립니다.
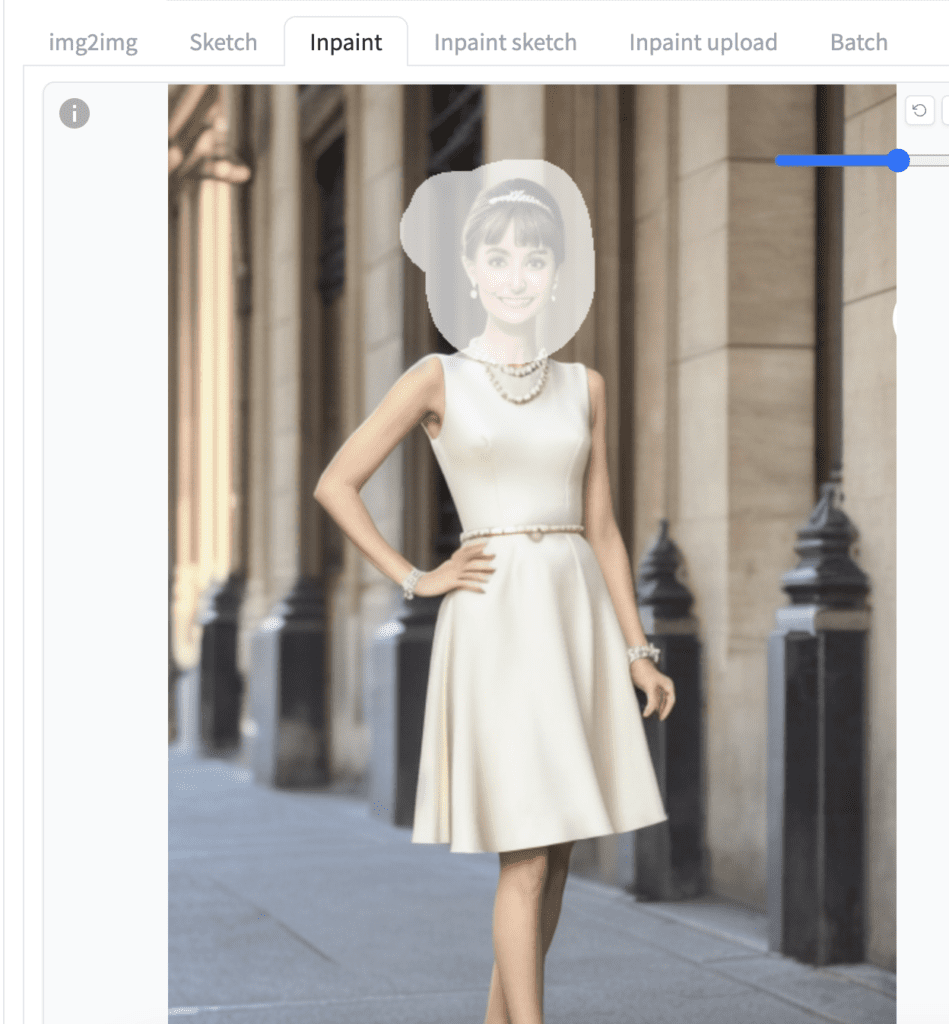
기본 설정을 그대로 사용해도 대부분 문제가 없습니다만, 다음과 같은 사항을 다시한번 확인해 보세요.
- inpaint area - Only masked : 마스크 칠한 부분만 변경됩니다.
- Batch size - 4 : 한번 실행할 때마다 4장의 이미지가 생성됩니다.
- Denoising Strength - 0.75 : 인페인트에서 가장 중요한 매개변수로서, 높은 값을 줄 수록 이미지가 많이 변경됩니다.
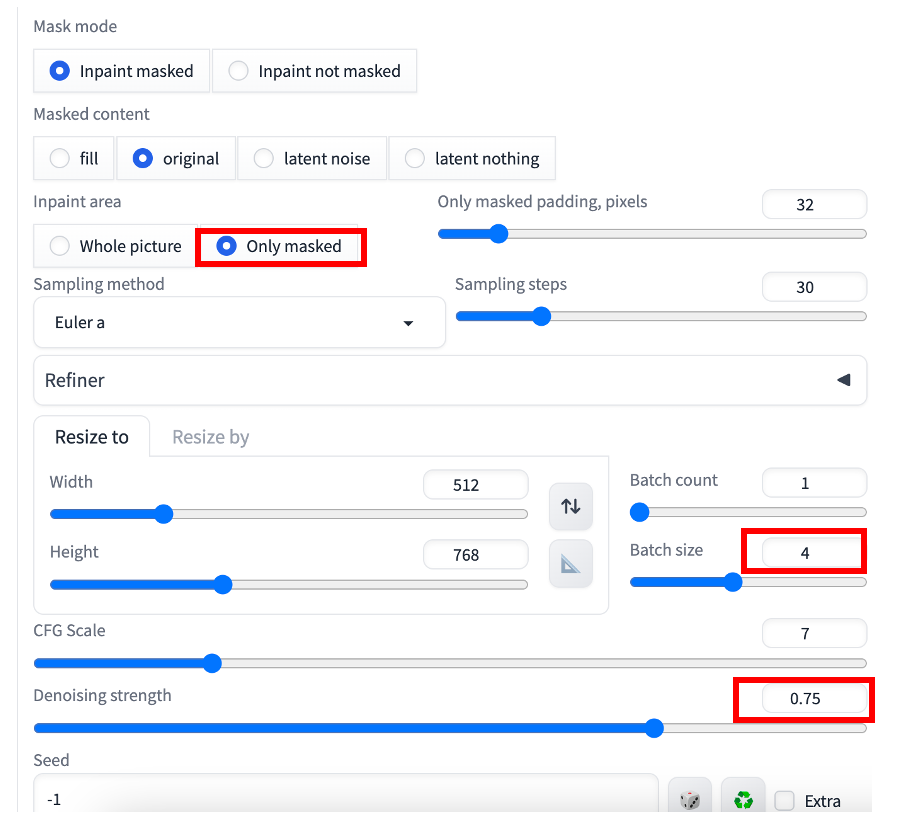
이제 [Generate] 버튼을 누르면, 마스크를 칠한 부분만 바뀌고, 나머지는 바뀌지 않은 이미지가 생성됩니다. 아래는 그중 하나입니다.

인페인트의 원리
인페인트는 기본적으로 img2img와 비슷합니다. img2img는 입력한 이미지에 무작위 잡음을 추가함으로써, 입력한 이미지를 기반으로 새로운 이미지를 생성합니다. 이때 인페인트는 입력한 이미지 전체가 아닌, 마스크로 지정한 영역에만 잡음을 추가해서 이미지를 새로 그린다는 점만 다릅니다.
인페인트 매개변수 설정
잡음제거 강도(Denoising Strenght)
잡음제거 강도는 인페인트에서 가장 중요한 매개변수로서, 인페인트 마스크 영영을 얼마나 변경시킬지를 결정합니다. 간단히 말해, 높은 값으로 넣을 수록 변경되지 않는 부분과의 일관성이 낮아집니다. 즉, 변경되지 않는 부분과 동떨어질 확률이 높아지게 됩니다. (단, 나중에 제어할 방법이 있습니다) 너무 낮은 값을 넣으면 흐린 영상이 생성됩니다. 처음에는 0.5 정도로 설정하는 것이 좋습니다.
 |
 |
| 원 이미지 | 0.1 |
 |
 |
| 0.5 | 0.9 |
인페인트 영역 - Whole picture(이미지 전체) 와 Only masked(마스크된 부분만)
Stable Diffusion v1.5 모델을 사용할 경우 얼굴이 제대로 표현되지 않는 경우가 많은데, 그 이유가 무엇일까요? 얼굴이 너무 작기 때문입니다. Stable Diffusion v1의 경우 학습에 사용된 이미지가 512x512인데, 이 크기에서 얼굴만이 확대된 이미지가 아닌 전신이 포함된 이미지에서는 얼굴이 잘 표현되지 않기 때문입니다. 즉, 원래 학습데이터에서 얼굴이 잘 표현되지 않기 때문에 생성된 이미지도 얼굴이 잘 표현되지 않는 것입니다. 스테이블 디퓨전 모델은 잘못이 없어요! ㅎㅎ
Only Masked 옵션을 사용하면 이 문제를 해결할 수 있습니다. 즉, 마스크된 영역만을 512x512 에 맞도록 확대시켜서 새로 그린 후, 다시 원래의 크기로 되돌리는 방식이기 때문입니다. 위에서 설명한 것처럼, 얼굴을 클로즈업(Close-up)된 이미지의 경우, 얼굴이 정상적으로 표현된 이미지로 학습되기 때문입니다.
반면 Whole picture(이미지 전체) 옵션을 사용하는 경우, 이와 같이 확대-> 재쟁성 -> 축소하는 과정이 없기 때문에 잘못된 얼굴을 고쳐주지 못하게 됩니다.
이상에서 볼 수 있는 것처럼 얼굴이나 신체 일부가 잘못된 이미지를 수정하는 경우 "Only masked" 옵션을 사용해야 합니다. 이때, 이미지 일부분만 추출해서 이미지를 재생성하기 때문에 전체적인 일관성은 떨어질 수 밖에 없습니다. 그러므로 이미지 전체의 일관성이 더 중요할 경우에는 "Whole picture" 옵션을 사용해야 합니다. ("Wholte picture" 옵션을 사용할 경우 얼굴을 수정해주지 못합니다.
 |
 |
 |
| 원 이미지 | "Whole picture" | "Only Masked" |
배경에 문제가 있을 경우에는 "Only masked" 옵션 대신 " Whole picture" 옵션을 적용해야 합니다.
 |
 |
 |
| 인페인트 마스크 | "Only Masked" | "Whole picture" |
Masked content (마스크 영역 내용)
이 옵션은 마스크로 지정한 영역의 이미지를 어떻게 처리할 지를 지정합니다.

- original : 원래 이미지를 그대로 사용합니다.
- fill : 마스크 영역의 색상 평균으로 대체합니다.
- latent noise : 원 이미지는 없애고 완전한 잡음으로 대체합니다.
- latent nothing : 원 이미지도, 잡음도 아니고, 모든 픽셀의 값을 0으로 대체합니다.
대부분의 경우, Original을 사용하는 게 가장 좋은 결과를 얻을 수 있습니다. fill을 사용하면 분위기를 비슷하지만, 완전히 다른 이미지가 생성되므로 시험해보는 것도 좋고요. 반면, latent noise 와 latent nothing을 사용하면 대부분의 경우 엉망이 되어 버립니다.
 |
 |
| original | fill |
 |
 |
| latent noise | latent nothing |
프롬프트
멋진 이미지를 발견했는데 인물이나 소품만 다른 것으로 바꾸고 싶을 경우가 있나요? 이런 경우에도 인페인트를 사용하면 처리할 수 있습니다. 아래의 이미지는 위에 있는 프롬프트에서 "audrey hapburn"을 "Ana de Armas, (emma watson:0.5), Liza Soberano"로 바꾼 예입니다. 이와 같이 유명인의 이름을 적절하게 사용하면 이미지를 여러개 생성할 때도 비슷한 얼굴을 얻을 수 있습니다.

인페인트 전용 모델
스테이블 디퓨전 모델 중에는 인페인트용으로 특별히 제작된 모델이 존재합니다. 이것이 인페인트 모델입니다. 인페인트 모델은 일반 스테이블 디퓨전 모델과는 달리, 마스크, 마스크 이미지 등을 지정하기 위한 UNET 채널이 5개 더 존재한다는 차이가 있습니다.
그러나 일반적으로 일부분만 새로 그리고자 할 경우에는 별도로 인페인트 모델을 사용할 필요가 없습니다. 인페인트 모델은 넓은 영역을 인페인트할 때 사용하는 모델입니다. 그런데, 인페인트 모델을 사용할 경우, 원래 스타일이 완전히 달라질 수 있기 때문에, 원래 생성할 때 사용했던 모델과 동일한 계통의 인페인트 모델을 사용하는 것이 좋습니다.
예를 들어, 이미지를 생성한 모델이 아래와 같을 경우
인페인트는 아래의 모델을 사용하는 것이 좋습니다.
특히 인페인트 모델을 사용하면 잡음 제거 강도(Denoising Strength)를 높일 경우에도, 이미지 전체적인 일관성이 높아집니다. 아래는 위의 이미지 중 아랫부분만 새로 생성한 이미지로서, 왼쪽은 일반 모델을, 오른쪽은 인페인트 모델을 사용하였을 경우입니다.
 |
 |
| 원래 모델로 인페인트한 결과 | 인페인트 전용 모델로 인페인트한 결과 |
인페인트 전용 모델 사용시 오류
인페인트 전용 모델을 사용시 아래와 같은 오류 메시지를 만날 수 있습니다.
“RuntimeError: Sizes of tensors must match except in dimension 1. Expected size 1 but got size 2 for tensor number 1 in the list.”
이 경우, Settings -> Optimization에 들어가서 Set Negative Guidance minimum sigma 를 0 으로 변경하면 해결될 수 있습니다.
콘트롤넷 인페인트
지금까지는 기본적인 인페인트 기능에 대해 설명드렸습니다. 여기에서는 인페인트를 적용하면서 ControlNet을 사용하는 방법을 알아보겠습니다.
콘트롤넷은 스테이블 디퓨전에서 필수적인 도구입니다. 주어진 이미지로부터 외곽선이나 자세 등을 복사할 수 있습니다. 인페인트의 경우에는 원래 이미지를 콘트롤넷의 참조용 이미지로 활용할 수 있습니다.
참고로, 아래 내용은 스테이블 디퓨전 v1에만 해당됩니다. (SDXL에서는 사용할 수 없습니다)
Tile Resample
콘트롤넷 Tile 을 사용하면 잡음제거 강도를 크게 한 상태에서도 원래의 이미지를 잘 따르는 이미지를 생성할 수 있습니다.
콘트롤넷 Tile 을 사용하려면, img2img 탭에서 ControlNet 영역으로 이동해 아래와 같이 설정합니다.
- Enable: Yes
- Control Type: Tile/Blur
- Preprocessor: tile_resample
- Model: control_xxx_sd15_tile
- ControlNet: 1 (결함이 보이면 값을 낮춥니다)
주의할 점은 ControlNet Tile을 사용할 경우 인페인트 전용 모델을 사용해서는 안된다는 것입니다. 인페인트 전용 모델은 이 용도로 학습되지 않았기 때문입니다.
downsampling rate는 필요에 따라 설정하면 됩니다. 이 값을 높이면, 제어 이미지를 흐리게 만들어서 생성되는 이미지가 좀더 많이 변경되는 효과가 발생합니다.

잡음제거 강도(Denoising Strength)를 1로 올린 상태에서도 아래에서 볼 수 있는 것처럼 얼굴은 변경되면서도 헤어스타일과 같은 세밀한 부분은 그대로 유지됨을 알 수 있습니다.
 |
 |
 |
| 원 이미지 | ControlNet Tile을 적용한 인페인트 | ControlNet Tile을 적용한 인페인트 (프롬프트 변경) |
Canny
Canny 는 이미지의 외곽선을 추출합니다. 즉, ControlNet Canny를 사용하면, 원 이미지의 외곽선을 따르는 이미지를 생성합니다.
인페인트의 경우, 위에서 설명한 tile resample과 비슷한 역할을 하지만, 색은 보존하지 않습니다. Canny 전처리기를 사용하면 인페인트되는 영역의 외곽선을 추출하게 됩니다.
ControlNet 설정방법은 위의 예제와 동일하게 설정하되, 전처리기는 Canny로, 모델은 control_xxxx_sd15_canny 로 바꿔주면 됩니다.
- Enable: Yes
- Control Type: Tile/Blur
- Preprocessor: Canny
- Model: control_xxx_sd15_canny
- ControlNet: 1 (결함이 보이면 값을 낮춥니다)
아래는 이와 같이 설정한 상태에서 프롬프트중 "black hair"를 "pink hair"로 일부 변경해서 생성한 결과입니다.

Inpaint_only
위에서 인페인트 전용 모델을 사용할 경우, 잡음제거 강도를 올려도 전체적인 일관성이 유지된다고 말씀드렸습니다. ControlNet Inpaint를 사용해도 이와 비슷한 효과를 얻을 수 있습니다. 설정은 아래와 같습니다.
- Enable: Yes
- Control Type: Tile/Blur
- Preprocessor: inpaint_only
- Model: control_xxx_sd15_inpaint
- ControlNet: 1 (결함이 보이면 값을 낮춥니다)
아래는 잡음제거 강도(Denoising Strength)를 1로 두고 생성한 이미지입니다. 보시는 것처럼 옷은 완전히 바뀌었지만, 전체적인 일관성은 그대로 유지됨을 알 수 있습니다.
 |
 |
자동 인페인트
인페인트를 직접해보시면 느끼셨겠지만, 얼굴을 수정하기 위한 방법으로서 인페인트를 사용할 경우, 상당히 기계적인 반복작업임을 알 수 있습니다. 생성된 이미지를 Inpaint로 보내고, 얼굴에 마스크를 씌운 다음, 잡음제거강도를 0.5로 두고 [Generate]버튼을 누르는 작업을 반복하게 되는 거죠.
이 과정을 자동으로 처리할 수 있습니다. 바로 After Detailer 확장을 사용하는 것입니다. ADetailer 에서 only masked 옵션을 적용하면 자동적으로 얼굴을 감지해서 수정해 줍니다. 손을 수정해 주는 옵션도 있고요. 대부분 기본 설정을 그대로 적용해도 잘 동작합니다.
SDXL 모델의 인페인트
이상에서 아시겠지만, 인페인트 기능은 대부분 얼굴이나 손발 등이 잘못 그려졌을 때 수정하기 위한 목적으로 많이 사용합니다. 특히 SD v1.4 또는 v1.5 기본 모델을 사용할 경우, 얼굴이 이상하거나, 손발이 중복되어 나타나거나 손가락 수가 6개가 되는 등의 오류가 많이 발생하기 때문에, 인페인트 기능이 매우 중요했습니다.
그런데 SDXL 모델로 이미지를 생성해보면 아시겠지만, 이러한 결함이 거의 발생하지 않습니다. 그래서 인페인트를 사용할 일이 그다지 많지 않습니다. 아직까지 SDXL에서 지원되지 않는 것들이 많아서 SD1.5와 SDXL을 함께 사용하는 경우가 많지만, 나중에는 특수한 목적... 그러니까 좋은 이미지이지만 다른 형태로 바꾸고 싶은 경우에만 사용하는 용도로 바뀔 것으로 예상됩니다.
ComfyUI에서의 인페인트
ComfyUI에서도 당연히 인페인트를 사용할 수 있습니다. 여기를 읽어보시면 됩니다. 다만, AUTOMATIC1111 보다 인페인트 기능은 약합니다. 특히 ComfyUI내에서 마스크를 그리는 방법이 없어서 외부 프로그램을 사용해야하고, 기타 세부적인 설정도 AUTOMATIC1111보다 약한 것 같습니다. 그냥 참고만 하세요.
이상입니다. 이 글은 stable-diffusion-art.com의 Inpainting: A Complete Guide를 번역하고, 일부 추가해서 작성한 글입니다. 예전에 써 둔 인페인트 가이드 글도 있으니 참고하세요.
민, 푸른하늘
===
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기