
요즘 Stable Diffusion 커뮤니티의 핫한 주제는 Video-to-Video입니다. 그 가운데에는 AnimateDiff 가 있죠. 저도 몇번 생성해봤지만, 아직도 잘 모르는 게 많아, 천천히 알아보려는 중입니다. 이 글은 AnimateDiff for AUTOMATIC1111에 이어 두번째 글로 https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved 를 번역한 글입니다.
- 개요
- 모델 설정
- 기능
- 기본 사용법 및 노드
- Multival 노드
- AnimateDiff Keyframe
- Context Options와 View Options
- [Sample Settings] 노드
- Iteration 옵션
- 잡음 레이어
개요
ComfyUI를 위한 AnimateDiff 가 보다 잘 통합되었으며, AnimateDiff 밖에서도 사용할 수 있는 고급 샘플링 옵션인 Evolved Sampling이 추가되었습니다. Animate의 핵심적인 동작 원리에 대한 자세한 내용은 AnimateDiff 저장소의 README와 Wiki를 참조하라.
AnimateDiff 워크플로는 아래의 몇가지 커스톰 노드들을 활용하고 있다.
- ComfyUI_FizzNodes - BatchPromptSchedule 노드를 사용한 프롬프트 트래블 기능을 위함. @FizzleDorf
- ComfyUI-Advanced-ControlNet - Context Option과 함께 ControlNet을 장동시키고, ControlNet 입력에 의해 영향을 받는 잠상를 제어하기 위한 목적임. @Kosinkadink (이 저장소 주인장)
- ComfyUI_VideoHelperSuite - 비디오 불러오기, 이미지를 합쳐서 비디오로 만들기 기타 붙이기/분리하기/복제하기/선택하기/숫자세기 등과 같은 여러가지 이미지/잠상 관련 작업. @AustinMorz 및 @Kosinkadink 가 관리
- comfyui_controlnet_aus - 기본 ComfyUI에는 존재하지 않는 ControlNet 전처리기. @Fannovel16
- ComfyUI_IPAadapter_plus - IPAdapter 지원. @cubiq(matt3o)
모델 설정
- 모션 모듈을 다운로드 받는다. 최소한 1개는 필요하다. 다른 모듈을 사용하면 다른 결과가 생성된다.
- 원 모델 mm_sd_v14, mm_sd_v15, mm_sd_v15_v2, v3_sd15_mm : HuggingFace / GoogleDrive / Civitai
- mm_sd_v14를 안정적으로 미세조정한 mm-Stabilized_mid 와 mm-Stabilized-high @manshoety Huggingface
- 고해상도 미세조정, temporaldiff-v10animatediff @CiaraRowles: Huggingface
- FP16/safetensor 버전 @continue-revolution (저장공간 줄지만 VRAM은 동일한 양 사용. ComfyUI가 기본으로 모델을 fp16으로 불러오기 때문: HuggingFace
- 모델을 아래의 폴더중 하나에 넣는다(필요하면 모델 이름을 변경할 수 있다).
- ComfyUI/custom_nodes/ComfyUI-AnimateDiff-Evolved/models
- ComfyUI/models/animatediff_models
- 선택적으로 mm_sd_v15_v2와 같은 v2 기반의 모션 모듈의 움직임에 영향을 주는 모션 LoRA를 사용할 수 있다.
- GoogleDrive / HuggingFace / Civitai
- 모션 LoRA는 아래의 폴더중 하나에 넣는다(필요하면 모델명을 변경할 수 있다).
- ComfyUI/custom_nods/ComfyUI-AnimateDiff-Evolved/motion-lora
- ComfyUI/models/animatediff_motion_lora
- 일반 이미지 생성에 문제가 없다면, AnimateDiff 생성도 문제가 없을 것이다. Latent Upscale, ControlNet 중첩 등도 문제 없다. ContolNet의 조건부여를 애니메이션 일부에만 적용하는 것도 문제없다. 어떤 것이 가능할 지 시험해보면 놀랄 것이다. 워크플로가 포함된 샘플이 아래에 있으니 참고하라.
참고: ComfyUI의 extra_model_paths.yaml 파일을 활용하면, 모델이나 모션 loRA의 위치를 다른 곳으로 바꿀 수 있다. 모션 모듈 폴더의 id 는 "animatediff_models"이고, 모션 LoRA 폴더의 id는 "animatediff_motion_lora"이다.
기능
- 거의 대부분의 바닐라 comfyUI 노드 및 커스톰 KSampler 노드와 호환됨
- ControlNet, SparseCtrl, IPAdapter를 지원
- 전체 UNet에 걸쳐 콘텍스트 윈도를 이동시켜서 (Context Options) 및/또는 모션 모듈 내에서(View Options) 무한한 길이의 애니메이션 지원
- 샘플링 프로세스의 여러 지점에서 Context Option을 변경하도록 스케줄링 가능
- FreeInit 과 FreeNoise 지원(FreeInit는 iteration ots아래에 있고, FreeNoise는 SamplingSetting의 noise_type 드롭다운에 있음)
- 원래의 AnimateDiff 저장소에 있는 모션 LoRA를 섞어서 사용할 수 있음.
주의 : 원 LoRA는 mm_sd_v15_v2, mm-p_0.5.pth, mm-p_0.75.pth와 같은 v2 기반 모션 모듈에서만 작동한다.- 갱신 : v2 한계가 없는 새로운 모션 LoRA를 AnimateDiff-MotionDirector 저장소를 통해 학습시킬 수 있게 되었다. AnimateDiff 용도로 MotionDirector를 구현해준 ExponentialML에게 감사를 전한다.
- ComfyUI_FizzNodes의 BatchPromptSchedule을 사용한 프롬프트 트래블
- 스케일(scale)과 효과(effect) 다중 입력을 통해, 이동량과 모션 모듈이 생성에 미치는 영향을 제어
- float, float list, mask 등이 가능
- Noise Types, Noise Layer 및 Sample Settings의 seed_overide/seed_offset/batch_offset 그리고 관련 노드를 통해 맞춤식 잡음 스케줄링 지원
- AnimateDiff v1/v2/v3 모델 지원
- Gen2 노드를 통해 다중 모션 모듈 지원
- (SDXL 모션 모듈 아치로서) HotShotXL 지원, hsxl_temporal_layers.safetensors.
- 참고 : beta_schedule을 autoselect 또는 linear(HotShotXL/기본)로 사용해야 하며, context_length 또는 (context를 사용하지 않을 경우) 총 프레임을 위한 sweetspot은 8 프레임이며, SDXL 체크포인트를 사용해야 한다.
- AnimateDiff-SDXL 지원. 현재 베타 버전이 나와 있음. AnimateDiff에 있는 추가 정보를 참조하라.
- 참고 : beta_schedule을 autoselect 또는 linear(HotShotXL/기본) 로 사용해야 하며, context_length 또는 (context를 사용하지 않을 경우) 총 프레임을 위한 sweetspot은 8 프레임이며, SDXL 체크포인트를 사용해야 한다.
- AnimateLCM 지원
- 참고 : beta_schedule을 autoselect 또는 lcm 또는 lcm[100_ots] 으로 사용해야 한다. 완전히 LCM과 사용하려면 적절한 LCM LoRA를 사용해야 하고, [KSampler] 노드에서 "lcm" 샘플러를 사용해야 하고, CFG를 1~2로 낮추어야 한다. 아울러 LCM은 빨르게 수렴하므로 샘플링 단계를 최소 4 단계로 낮추어야 한다. 단계를 올리면 디테일이 증가한다.
- AnimateDiff Keyframes를 사용하면 샘플링 프로세스의 여러 점에서 스케일(scale)과 효과(effect)를 변경가능
- fp8 지원: 최신의 ComfyUI와 torch >=2.1 이 필요함(VRAM 사용량을 줄이지만 결과물은 달라짐)
- Mac M1/M2/M3 지원
- Gen2를 사용해 [Context Options]과 [Samle Settings] 노드를 AnimateDiff 외부에서도 사용가능. [Evolved Sampling]노드 사용.
향후 추가 예정 기능
- 마스크 지정 가능한 모션 LoRA
- 마스크 지정 가능한 SD LoRQA(아마도 마스크 가능한 SD 모델 포함)
- PIA 지원
- 앞으로 AnimateDiff 관련해 나오는 것 모두
기본 사용법 및 노드
AnimateDiff/Evolved 샘플링에 사용할 수 있는 노드는 크게 두가지 종류가 있다. Gen1 과 Gen2이다. Gen1/Gen2라고 명시된 것 이외의 다른 노드들은 Gen1 및 Gen2모두와 함께 사용할 수 있다.
Gen1과 Gen2는 완전히 동일한 결과물을 생성한다(뒷단의 코드는 동일). 차이는 모델을 사용하는 방법이다. 개략적으로, Gen1은 기본 AnimateDiff 기능을 사용하는 간단한 방법이며, Gen2는 Evolved 샘플링 노드로 부터 모델 불러오기와 적용을 분리하였다. 즉 실용적으로, Gen2의 Evolved 샘플링 노드는 모션 모듈 없이도 사용가능하며, AnimateDiff 없이도 [Context Options]와 [Sample Settings]를 사용할 수 있다는 뜻이다.
| ① Gen1 ① | ② Gen2 ② |
| - All-in-One 노드 - 여러 Gen1 노드에서 동일한 모델을 불러오면, RAM을 중복으로 사용하게 됨 |
- 모델 불러오기와 적용, Evolved 샘플링을 분리함 - Evolved 샘플링 기능을 보전하면서도 모션 모듈을 사용하지 않을 수 있음 - [Apply AnimateDiff Model(Adv.)] 노드에 여러개의 모션 모듈을 적용가능 |
 |
 |
 |
 |
[AnimateDiff Loader ① ]

- 위젯
- model_name - 불러와서 샘플링 프로세스 동안 적용되는 AnimateDiff(AD) 모델. 어떤 모션 모델은 SD1.5에 사용되며, 어떤 것은 SDXL에 사용된다.
- beta_schedule - 선택된 beta_schedule은 SD모델에 적용된다. "autoselect"를 사용하면 선택된 모션 모델에 대해 추천하는 beta_schedule을 자동으로 선택한다. Gen2의 경우 모션모델을 선택하지 않으면 use_existing을 사용한다.
- 입력 슬롯
- model(필수) - 스테이블 디퓨전 모델
- context_options(선택) - context opts 서브메뉴에 있는 [Context Options] 노드 - AnimateDiff 모델의 sweetspot을 되돌릴 필요가 있을 때 사용하는 것이 좋다.

- motion_lora(선택) - v2 기반 모델의 경우, 모션 LoRA를 사용하면 움직임을 제어할 수 있다. 공식 모션 LoRA의 숫자는 많지 않다. 아마도 곧 커뮤니티 멤버들과 함께 v2기반 모델이 아닌 모션 LORA를 생성하는 학습코드를 생성할 수 있을 것이다.
- ad_settings(선택)??? - 모션 모델을 불러올 때 수정하여, Positional Encoder(PE) 를 조정해 모델의 sweetspot을 확장하거나, 전체 모션을 수정할 수 있도록 한다.
- ad_keyframes(선택)??? - "scale_multival" 과 "effect_multival" 입력을 샘플링 단계에 걸쳐 스케줄링을 허용함
- sample_settings(선택)??? - [Sample Settings]노드와 연결. FreeNoise(moise_type), FreeInit(iter_ops), 공통 시드, 잡음 레이어 등과 같은 맞춤형 샘플링 옵션을 적용하는 데 사용함. Gen2의 경우엔 모션 모듈 없이도 사용가능

- scale_multival(선택)??? - "Multival" 입력(기본은 1.0)을 사용. 예전엔 motion_scale이라고 하였는데, 모델로 생성되는 움직임의 양에 영향을 주었다. Multival 노드를 사용하면서, float/float list/mask 를 허용하여 다른 스케일로 적용할 수 있도록 하였다. 여러 프레임 뿐 만 아니라, 프레임의 각 부분에도 적용가능하다.
- effect_multival(선택)??? - "Multival" 입력(기본은 1.0)을 사용. 샘플링 프로세스에 대한 모션 모델의 영향을 결정한다. 0.0 은 AnimateDiff의 영향이 없는 일반 스테이블 디퓨전 출력과 동등하다. Multival 노드를 사용하면서, float/float list/mask 를 허용하여 다른 스케일로 적용할 수 있도록 하였다. 여러 프레임 뿐 만 아니라, 프레임의 각 부분에도 적용가능하다.
- 출력 슬롯
- MODEL - Evolved 샘플링/AnimateDiff가 적용된 SD 모델 출력
Gen1 과 Gen2의 비교
아래에서 보는 것처럼, 여러개로 분리가 되었을 뿐, Gen1과 Gen2는 동일하다. 출력 슬롯에 MOTION_MODEL과 M_MODELS가 있다.

Gen2 와 Gen2 (Adv.) 비교
아래 3개의 항목이 추가되었다.

- prev_m_models(선택) - 현재의 모션 모델과 함께 사용할, 이전에 적용된 모션 모델
- start_percent(선택) - 연결된 모션 모델이 언제 효과를 발휘할 지 결정(모든 ad_keyframe을 덮어씀)
- end_percent(선택) - 연결된 모션 모델이 언제 효과를 멈출 지 결정(모든 ad_keyframe을 덮어씀)
Multival 노드
Multival 입력을 위해 이들 노드들은 float/float list/mask를 입력으로 사용할 수 있다. [Scaled Mask]는 마스트의 어둡거나 밝은 영역을, 값이 어떤 것에 해당하는지 조정할 수 있다.

- mask_optional - float값을 위한 마스크 - 검은색은 0.0, 하얀색은 1.0을 의미한다. 이 값을 float_val와 곱한다.
- float_val - 곱셈 지수

- mask - float 값에 대한 마스크
- min_float_val : 최소값
- max_float_val : 최대값
- scaling : "absolute"의 경우, 검은색이 min_float_val 로 되며, 흰색은 max_float_val이 된다. "relative"의 경우, 마스크에서 가장 어두운 부분이 min_float_val 로 되며, 마스크에서 가장 밝은 부분이 max_float_val이 된다
AnimateDiff Keyframe
scale_multival 과 effect_multival 에 대한 (timesteps에 대한) 스케줄링을 가능하게 한다.
스케줄을 결정하는 세팅은 start_percent와 guarantee_steps 등 두가지이다. 여러 keyframe의 start_percent가 동일할 경우, 연결된 순서대로 수행되며, gurantee_steps만큼 실행된 후, 다음 노드로 이동된다.

- 입력 슬롯
- prev_ad_keyframes(선택) : 스케줄 생성을 위해 연결된 키프레임
- scale_multival(선택) : 이 키프레임을 위해 사용되는 scale 값
- effect_multival (선택) : 이 키프레임을 위해 사용되는 effect 값
- start_percent : 이 프레임 사용을 시작하기 위한 timestep의 비율. 여러 keyframe의 start_percent가 동일할 경우, 연결된 순서대로 수행되며, gurantee_steps만큼 지속된다.
- guarantee_steps : 해당 키프레임이 사용되는 최소 단계수. 0으로 설정하면 현재 timestep에 더 잘맞는 다른 키 프레임이 없을 때에만 이 키프레임이 사용된다.
- inherit_missing : "True"로 설정할 경우, scale_multival 또는 effect_multival 입력이 없는 것은 이전 키프레임 값을 따르게 된다. 이전 키프레임도 입력이 없다면 마지막 상속받은 값이 사용된다.
콘텍스트 옵션(Context Options)과 뷰 옵션(View Options)
이 노드들은 애니메이션 길이를 연장하여 AnimateDiff 모델(대부분 16프레임)과 HotshotXL 모델(8 프레임)의 sweetspot 한계를 회피하는데 사용된다.
콘텍스트 옵션은 주 SD 디퓨전, 콘트롤넷, IPAdapter 등을 포함하여 애니메이션의 일부를 한번에 디퓨전하는 방식으로 작동하여, VRM 사용량을 context_length 잠상와 동등하도록 효과적으로 제한한다.
뷰 옵션은 이와 반대로, 모션 모델에서 보이는 잠상를 분할하여 작동한다. 이렇게 하면 VRAM 사용량이 줄지는 않지만, 일반적으로 Context Option 보다 더 안정적이고 빠르다. 잠상가 전체 SD Unet을 통과할 필요가 없기 때문이다.
콘텍스트 옵션과 뷰 옵션을 결합하여 두가지 장점을 모두 얻을 수 있다. context_length를 길게하면 더 많은 VRAM을 사용하는대신 안정적인 출력을 얻을 수 있다. (context_length는 GPU에서 동시에 수행되는 SD 샘플링의 양을 결정한다) VRAM이 충분하다면 View Only Context 옵션을 사용하여, 뷰 옵션만 사용하여(자동적으로 context_length는 전체 잠상와 동일하게 설정함), VRAM을 많이 사용하는 대신 속도를 올릴 수 있다.
콘텍스트/뷰 옵션에는 표준(Standard)와 루프(Looped) 등 두가지 옵션이 있다. 표준(Standard)옵션은 출력에서 루프를 생성하지 않는다. 루프(Looped)옵션은 이름 그대로 결과물에서 루프가 발생한다(시점과 종점이 동일). 코딩 재작업 이전에는 루프형 콘텍스트 옵션만 가능하였다.
루프형 출력을 원치않는다면 먼저 Standard Static을 사용하는 것을 추천한다.
아래의 애니에밍션에서 초록색은 Context, 발간색은 뷰 옵션을 나타낸다. 초록색은 VRAM에 불러진(샘플링되는) 잠상의 양이며, 빨간색은 한번에 모션 모델을 통과하는 잠상의 양이다.
콘텍스트 옵션 Standard Static

(잠상 수 64, context_length: 16, context_overlap: 4, 총 단계; 20

- context_length : 한번에 디퓨전되는 잠상의 양
- context_overlap : 인근 윈도간의 최소 공통 잠상의 양
- fuse_method : 윈도의 결과를 평균하는 방법
- use_on_equal_length : True이면 잠상가 context_length와 동일할 때에도 콘텍스트가 사용되도록 허용함
- start_percent : 여러 콘텍스트 옵션이 연결되었을 경우 스케줄링을 허용함
- guarantee_steps : 콘텍스트의 스케줄링시, 사용되는 샘플링 단계 콘텍스트의 최소량을 결정한다.
- prev_context : 콘텍스트 연결에 사용
- view_opts : context_length 가 view length보다 클경우, 각 context 윈도내에 view option이 사용되도록 허용함
------ ((엄청나게 많으나 생략한다) ----
[Sample Settings] 노드
[Sample Settings] 노드는 대부분의 KSampler 노드에서 노출되는 것 이상의 샘플링 프로세스의 변경할 수 있다. 기본 값을 사용하면 아무런 효과가 없으므로, 어떠한 행동도 일으키지 않고 안전하게 붙일 수 있다.
FreeNoise를 사용하려면, noise_type 드롭다운에서 "FreeNoise"를 선택한다. FreeNoise는 성능을 전혀 떨어뜨리지 않는다. FreeInit을 사용하려면, iteration_opts에 [FreeInit Iteration Options] 노드를 부착한다.
참고: FreeInit는 이름과는 달리 "iteration" 시간동안 잠상 리샘플링 방식으로 작동한다. 즉, iteration=2를 사용하면 샘플링 시간은 정확하게 2배로 늘어나게 된다. 샘플링이 두번 이루어지기 때문이다.
동일한 이름(또는 매우 유사한 이름)의 입력이 있는 잡음 레이어는 [Sample Settings]의 입력과 동일한 의도로 작동된다. - 아래의 입력을 참조하라.
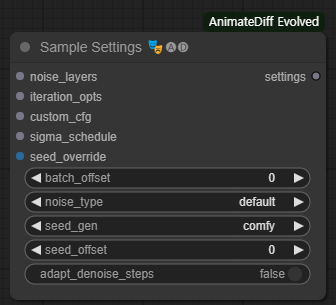
- noise_layers(선택) : 최초의 잡음에 추가 또는 변경하기 위한, 사용자 지정이 가능하고 중첩이 가능한 잡음.
- iteration_opts(선택) : 샘플링을 연속적으로 반복할지 여부(및 방법)을 결정하는 옵션. FreeInit 를 확인하려면 이것이 사용방법이다????
- seed_override(선택) : KSampler에 전해진 씨드 대신, 씨드로 사용되는 단일 정수. 또는 배치에 있는 각각의 잠상에 대해 개별 시드를 지정하기 위한 정수 리스트 (예: FizzNodes의 BatchedValueSchedule과 비슷)
- batch_offset : 0이 아니면, 처음 잠상이 실제로 batch_offset_n번째 잠상인 것처럼, 잡음을 상쇄하여 모든 잡음을 이동시킨다.??
- noise_type : 생성할 잡음 유형.
- default : 평상시처럼 모든 잠상에 대해 다른 잡음 생성
- constant : 모든 잠상에 대해 완전히 동일한 잡음을 생성(seed에 기반함).
- empty : 모든 잠상에 대해 잡음을 생성하지 않음(잡음이 꺼진 것 처럼)
- repeated_context: 모든 context_length(또는 view_length)만큼 잠상의 양 잡음을 반복한다. 긴 생성을 안정화시키지만, 매우 뚜렸한 반복이 발생한다.
- FreeNoise : 모든 context_length(또는 view_length)만큼 잠상의 양 잡음을 반복하지만, 안정화를 달성하면서도 콘텍스트/뷰 간의 중첩 잡음은 섞어서 덜 두드러지게 하는 방식으로 잡음을 반복한다.
- seed_gen : ComfyUI 및 AUTOMATIC111 잡음 생성방식을 선택. 어느것이 나은 것은 없고(잡음 분포는 동일함), 그냥 다른 것 뿐이다.
- Comfy : 제공된 씨드를 기반으로 모든 잠상 배치 텐서에 대해 한꺼번에 잡음이 생성된다.
- auto1111 : 각 잠상별로 개별적으로 잡음이 생성된다. 각 잠상은 씨드 오프셋이 +1 증가된다(첫번째 잠상은 씨드를 사용하고, 두번째 잠상은 씨드+1 을 사용 등등)
- seed_offset : 0이 아니면, 현재의 씨드에 더하여 예측가능하게 변경시킨다.
- adpat_denoise_steps : "True"일 경우, 잡음제거 강도 입력이 있는 KSampler가 AUTOMATIC111의 기본 옵션처럼 전체 단계를 자동으로 축소시킨다.
- True: 낮은 잡음 강도때 단계가 줄어든다. 즉 잡음제거 강도가 0.6이고 20 단계라면 총 10 단계가 수행되지만, 시그마가 선택되어 0.5 잡음제거강도를 달성한다? 대신 단계가 주는 만큼 품질이 낮아진다.
- False : 기본처럼 작동한다. 잡음제거강도 0.5 이고 20단계라면 총 20단계가 수행된다.
Iteration 옵션
이 옵션을 사용하면 여러 KSampler를 묶지 않고도 동일한 잠상을 다시 샘플링시킬 수 있다. 또한 FreeInit와 같은 기능을 구현하는 특별한 반복 행동도 허용한다.
기본 반복 옵션
기존 반복의 결과를 새로운 반복에 넣는 방식으로, 간단히 KSampler를 재수행한다. 기본 iteration=1 에서는 이 노드가 없는 것과 동일하다.

- iterations : KSamper가 수행될 총 횟수
- iter_batch_offset : 각각의 이어지는 반복에 적용되는 batch_offset
- iter_seed_offset : 각각의 이ㅇ지는 반복에 적용되는 seed_offset
FreeInit 반복 옵션
AnimateDiff가 기존 비디오(잠상간의 시간적 일관성이 있음)의 잠상에 대해 학습되어서, 무작위 초기 잡음이 아닌, 기존 잠상에 잡음을 더하는 방식이므로, 잡음있는 잠상에 저주파 데이터가 남아 있다는 아이디어인 FreeInit을 구현한다. FreeInit는 기존 비디오의 저주파 잡음에 무작위로 생성된 고주파 잡음을 더하여 후속 반복을 실행한다. 각 반속은 전체 샘플이며, 2회 반복은 1회 반복 또는 iteration_opts가 연결되지 않는 경우에 비해 실행시간이 2배 걸린다.
apply_to_1st_iter 가 "False"일 경우, nosing/low-freq/high-freq 조합은 첫 반복에서는 일어나지 않는다. 처음에는 결합할만큼 유용한 잠상이 전해지지 않는다는 가정으로서, 따라서 최소 2번의 반복이 있어야 FreeInit가 효과가 있다.
저주파 잡음을 얻는데 사용할 잠상 세트가 존재할 경우, apply_to_1st_iter를 "True"로 적용해도 무방하다. 이 경우 iteration=1 인경우에도 FreeInit가 효과가 있다.
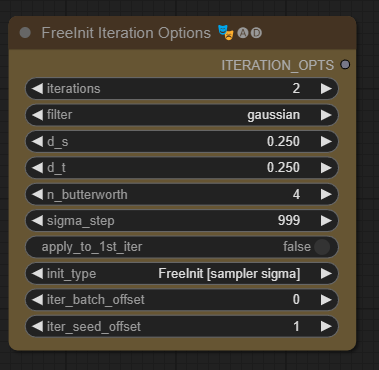
- iteration : KSampler가 수행되는 총 횟수. 기본 값이 2인 이유는 위의 설명을 참조하라.
- filter : 잡음에 적용할 저주파 필터를 결정한다. 각 필터의 원리나 방식은 매우 기술적이므로 코드나 온라인을 참조하라.
- d_s : 필터의 공간적 매개변수. 기술적임
- d_t : 필터의 시간적 매개변수. 기술적임
- n_butterworth : "butterworth" 필터에만 적용된다. 기술적임
- sigma_step : 잡음있는 잠상에 사용/에뮬레이션 하여 저주파 잡음을 제거하기 위한 잡음제거 단계. 999는 실제로는 마지막(-1)을 의미하며, 999 이하의 숫자는 마지막에서의 거리를 의미한다. 무슨뜻인지 모르겠다면 그냥 둘 것
- init_type : FreeInit를 적용하기 위한 코드 구현
- FreeInit [sampler sigma] : 아마 의도된 구견에 가장 가까울 것이며, 모델 대신 샘플러로부터 잡음제거를 위한 시그마를 얻는다.???
- FreeInit [model sigma] : 모델로부터 잡음제거를 위한 시그마를 얻는다. 사용자 지정 KSampler를 사용할 경우, 이 방법이 두가지 FreeInit 옵션에 사용된다.
- DinkInit_v1 : 잡음제거 방법을 정확하게 복제하는 방법을 알기전, 최초의 문제있는 FreeInit 구현. 운도 좋고 시행착오 끝에 이 방법이 통하도록 할 수 있었다. 이제 역 호환성이 주요 목적이나, 유용한 결과를 얻을 수도 있다.
- iter_batch_offset : 각각의 이어지는 반복에 적용되는 batch_offset
- iter_seed_offset : 각각의 이어지는 반복에 적용되는 seed_offset. 기본 값은 1로서, 매 반복마다 새로운 무작위 잡음이 사용된다.
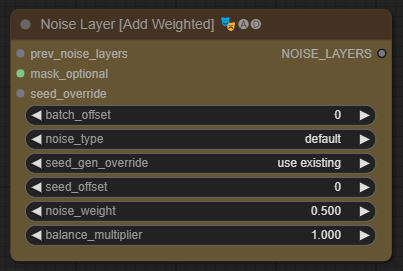
잡음 레이어
이들 노드는 잡음이 추가되거나 곱해지거나 대체될 수 있도록 한다. 가까운 미래에 나는 노이즈를 cut&paste 하는 대신, 마스크가 노이드를 마스크 이동에 상대적으로 이동시키는 기능을 추가할 예정이다.
[Sample Settings] 노드와 공유하는 입력은 동일한 효과가 있다. 새로운 옵션은 seed_gen_override로서, 기본으로 [Sampler Settings]와 동일한 seed_gen을 사용한다. 잡음 레이어가 다른 seed_gen 전략을 사용하도록 할 수있거나, 다른 씨드/씨드 집합을 사용할 수 있다.
- [Noise Layer [Add]] - 노이즈를 바로 위에 더한다.

- [Noise Layer [Add Weighted]] - 원래 있던 잡음과 새로운 잡음의 가중 평균을 취해 더한다.
- [Noise Layer [Replace]] - 기존 잡음을 제거한다.
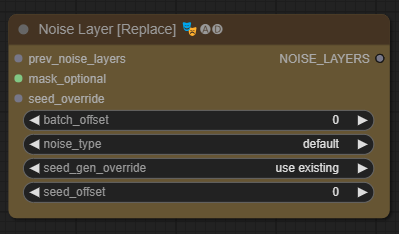
이상입니다.
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기