
스테이블 디퓨전(Stable Diffusion)은 텍스트로부터 인공지능 이미지를 생성하는 잠재 확산 모델(latent diffusion model) 입니다. 고차원의 이미지 공간이 아닌, 먼저 이미지를 잠재 공간(latent space)로 압축합니다.
Stable Diffusion을 우리말로 번역하면 "안정적인 확산"입니다. 왜 이런 이름을 붙였을까요? 그냥 사용할 줄 알면 되지, 왜 작동 원리까지 알아야 할까요? 그 해답은 이렇습니다. "우리가 필요한 것은 내가 원하는 이미지를 잘 뽑아내는 것이고, 내부 작동원리를 알면 이렇게 이미지를 잘 뽑아내는 데 도움이 되기 때문"입니다.한마디로 도구를 올바르게 사용하면 더 정밀한 결과를 얻을 수 있습니다.
text-to-image 는 image-to-image와 어떻게 다른가? CFG 척도는 무엇인가? 잡음제거 강도는? 이 글에서는 이러한 내용에 대한 간단한 해답을 알아본니다.
- Stable Diffusion 은 무엇을 하는가?
- 디퓨전(Diffusion) 모델
- 학습 방법
- 스테이블 디퓨전 모델
- 조건부여(Conditioning)
- Stable Diffusion 의 처리 단계
- 무분류기 안내(CFG, Classifier-Free Guidance)
- 스테이블 디퓨전 v1 과 v2 비교
- SDXL 모델
Stable Diffusion은 무엇을 하는가?
간단하게 말해서 스테이블 디퓨전은 text-to-image 모델, 즉, 텍스트(문장/단어)로부터 이미지를 뽑아내는 모델입니다. 텍트트 프롬프트를 입력하면, 그 텍스트에 맞는 이미지를 반환하는 것이죠.

디퓨전(Diffusion) 모델
Stable Diffusion은 디퓨전 모델(diffusion model)이라는 딥러닝 모델의 일종입니다. 디퓨전 모델은 생성형 모델입니다. 즉, 학습받은 것과 비슷한 새로운 데이터를 생성하도록 설계된 모델입니다. Stable Diffusion의 경우 데이터는 이미지를 의미하죠. ChatGPT는 문장을 생성하는 것이고요. 마찬가지로 생성형 모델은 음악이든 글이든 무엇이든 생성할 수 있습니다.
그러면 왜 Diffusion 모델이라고 할까요? 물리학에서의 확산(diffusion)과 수학적으로 매우 비슷하기 때문입니다. 이를 좀 더 자세하게 알아보도록 하겠습니다.
일단, 개와 고양이로 구성된 두가지 종류의 이미지들만 사용해서 디퓨전 모델을 학습시킨다고 가정해 봅시다. 아래 그림에서 가운데 부분에 있는 두 개의 (옆으로 눕혀진) 종모양이 각각 고양이 이미지와 강아지 이미지를 대표합니다.
순방향 확산(Forward Diffusion)
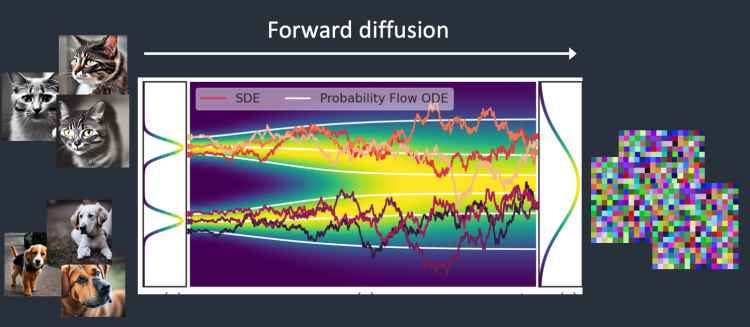
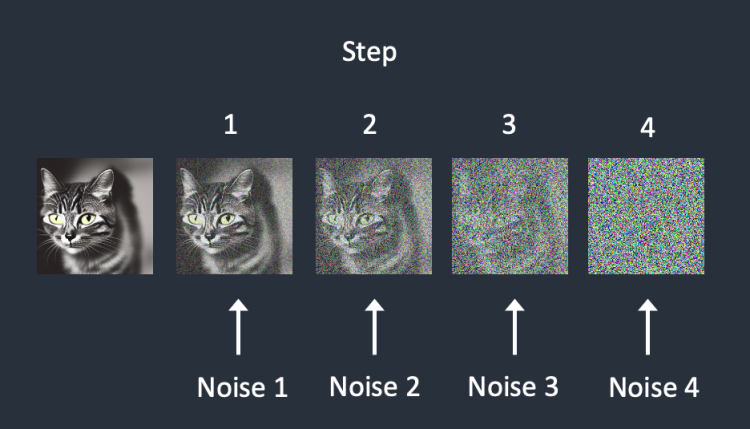
순방향 확산(forward diffusion) 프로세스에서는 학습용 이미지에 점차적으로 잡음을 추가하여, 점점 아무런 특징이 없는 잡음 이미지로 바꿔갑니다. 아무리 예쁜 이미지도 순방향 프로세스를 거치면 위 그림 맨 오른쪽에 있는 잡음 이미지가 되어서, 결국 강아지 그림인지 고양이 그림인지도 알 수 없게 되어 버립니다(이 사실이 매우 중요합니다).
이것은 물컵에 잉크를 한방울 떨어뜨리는 것과 비슷합니다. 잉크가 물속에서 "확산(diffusion)"하게 되고, 몇분 지나면 물속에 완전히 퍼져버려서 처음에 잉크가 어디에 떨어졌는지 전혀 알 수 없게 되어 버립니다.
아래는 이미지가 순방향 확산을 거치는 과정입니다. 고양이 이미지가 결국 무작위 잡음(random noise)로 바뀌게 됨을 볼 수 있습니다.

역방향 확산(Reverse diffusion)
이 확산 과정을 거꾸로 돌리면 어떻게 될까요? 물론 물속의 잉크를 다시 잉크로 뽑아내는 방법은 없지만, 컴퓨터 세계에서는 가능합니다. 비디오를 거꾸로 돌리는 것처럼요.
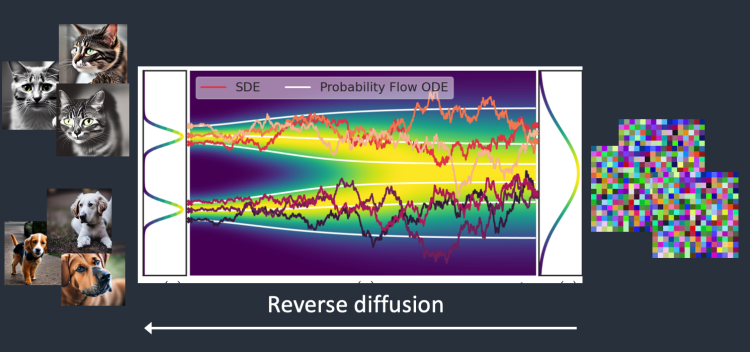
역방향 확산(reverse diffusion)은 잡음(noise), 즉 의미없는 이미지에서 출발해서 강아지 혹은 고양이 이미지를 복구하는 것입니다. 잉크물에서 잉크가 떨어진 위치를 알아낼 수 있는 것입니다.
기술적으로 보았을 때, 확산 프로세스는 (1) 드리프트(drift) 혹은 방향성 이동 (2) 무작위(random) 이동 등 두 부분으로 구성됩니다. 역방향 디퓨전은 아무것도 없는 곳에서 고양이 또는 강아지 이미지를 향하여 드리프트(떠도는 것)하게 되죠. 이렇게 해서 결과가 고양이 또는 강아지가 되게 됩니다.
학습 방법
역방향 확산은 정말 영리하고 우아합니다. 하지만, 어떻게 이게 가능할까요? 확산(diffusion)을 뒤집기 위해서는 이미지에 얼마나 많은 잡음이 들어있는지 알아야 합니다. 그 해답은 신경망(NEURAL NETWORK) 모델에게 추가된 잡음을 예측하도록 학습시키는 것입니다. 이것을 스테이블 디퓨전에서는 잡음 예측기(noise predictor)라고 하며, U-Net 모델을 사용합니다. 훈련은 다음과 같이 진행됩니다.
- 학습용 이미지(예: 고양이 이미지)를 선택한다.
- 무작위 잡음 이미지를 생성한다.
- 학습용 이미지에 정해진 단계만큼 무작위 잡음 이미지를 추가하여 손상시킨다.
- 잡음 예측기에게 잡음 추가량을 학습시킨다. 가중치를 조정하고 정답을 보여주는 방식으로 작업이 수행된다.
이렇게 학습이 이루어지면, 이미지에 추가된 잡음을 예측할 수 있는 잡음 예측기(noise predictor)를 확보하게 됩니다. 이 잡음 예측기를 역방향 확산 프로세스에서 사용하여 이미지를 복원하게 됩니다.
역방향 확산(Reverse diffusion)
지금까지 잡음 예측기를 사용했습니다. 이것을 어떻게 사용할까요?
먼저 완전한 잡음 이미지를 생성하고, 잡음 예측기(noise predictor)에게 이 이미지에 잡음이 얼마나 포함되었는지 질문을 던집니다. 그 다음 잡음 예측기가 반환한 예측 잡음을 원래의 잡음 이미지에서 제거합니다(substract). 이렇게 생성된 이미지에서 다시 잡음 예측기에게 예측을 시키고, 이로부터 새로운 이미지를 생성합니다. 이러한 방식을 몇번 반복하면 최종적으로 고양이나 강아지 이미지중 하나를 얻게 되는 것입니다.
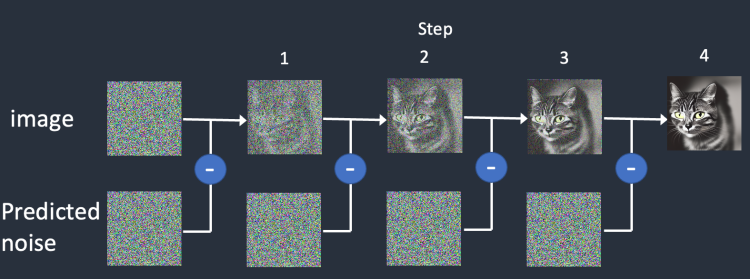
이 설명에서는 생성되는 이미지에 아무런 제어도 하고 있지 않습니다. 즉, 조건없이 이미지가 생성되는데, 컨디셔닝(conditioning, 조건부여)에 대해서는 아래에서 다루겠습니다. 당분간은 조건부여가 없는(unconditioned) 이미지를 생성합니다.
스테이블 디퓨전 모델
이제까지 설명은 개념적인 것에 불과합니다. 이대로는 거의 작동이 안되거나, 매우 느리다는 뜻입니다. 위의 설명은 이미지 공간에서 직접 설명했는데(이미지 공간이라고 이야기했지만, 그냥 이미지 상태라는 뜻으로 생각하면 됩니다.), 이렇게 되면 계산이 매우매우 느리게 됩니다. 이 경우, 현존하는 최고의 GPU를 사용한다고 해도, 하나의 GPU로는 계산이 불가능합니다.
이지지 공간은 엄창나게 크기가 큽니다. 3 개의 색채널(R,G,B)가 있는 512x512 짜리 이미지라면, 786,462 차원을 차지합니다. 이미지 하나마다 이 값을 지정해야 하는 것입니다.
구글의 Imagen 또는 Open AI의 DALL-E는 이러한 이미지 공간에서 작동됩니다. 모델을 빠르게 돌릴 수 있는 몇가지 기법을 동원하고는 있지만, 워낙 크기가 커서 한계가 있죠.
잠재 확산 모델(latent diffusion model)
스테이블 디퓨전은 이러한 문제를 잠재 확산 모델(latent diffusion model)을 사용하여 해결했습니다. 이상과 같이 고차원의 이미지 공간에서 작동시키는 것이 아니라, 먼저 잠재 공간(latent space)으로 이미지를 압축한 뒤 연산을 시행하는 것입니다. 잠재 공간은 이미지 공간에 비해 48배나 작기때문에 훨씬 연산이 빨라집니다.
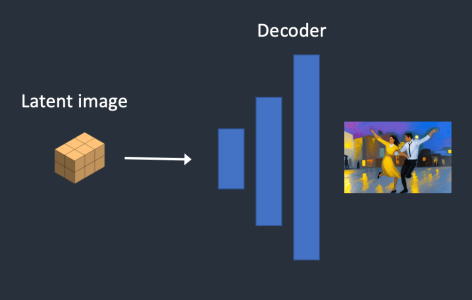
가변 자동 인코더(VAE, Variational AutoEncoder)
이미지를 잠재 공간으로 압축하는 데는 가변 자동 인코더(variational autoencoder)라는 기법을 사용합니다. (스테이블 디퓨전 설정할 때 VAE는 들어보셨죠? VAE 파일이 이 역할을 하는 것입니다.)
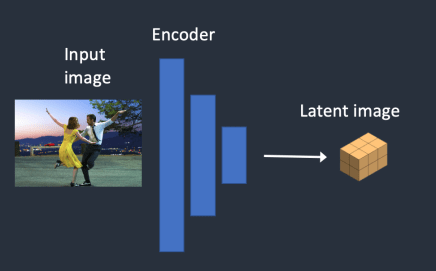
가변 자동 인코더(VAE) 신경망은 (1) 인코더(encoder), (2) 디코더(decoder) 등 두 부분으로 나누어집니다. 인코더는 이미지를 잠재 공간에서 낮은 차원의 표현으로 압축하며, 디코더는 잠재 공간(latent space)으로부터 이미지를 복원하는 역할을 담당합니다.

스테이블 디퓨전의 잠재 공간의 크기는 4x64x64(16,384)입니다. 이미지 픽셀 공간에 비해 1/48뿐이 안됩니다. 위에서 이야기한 순방향 디퓨전 및 역방향 디퓨전은 모두 이 잠재 공간상에서 이루어지게 됩니다.
즉, 다시 말해서, 위에서는 잡음 이미지를 생성한다고 했지만, 실제로는 잠재 공간상의 무작위 텐서(random tensor, latent noise)를 생성합니다. 또한 잡음을 사용해 이미지를 손상시키는 게 아니라, 잠재 공간상의 이미지 표현을 잠재 잡음(latent noise)을 사용해 손상시킵니다. 이렇게 하는 이유는 잠재 공간이 작기 때문에 연산이 훨씬 빠르기 때문입니다.
이미지 해상도
이미지 해상도는 잠재 이미지 텐서의 크기에 반영됩니다. 512x512 이미지에 대해서만 잠재 이미지의 크기가 4x64x64가 됩니다. 768x512 이미지의 경우 4x96x64가 되죠. 이 때문에 크기가 큰 이미지를 생성하려면 시간이 오래 걸리고 VRAM을 더 많이 차지하는 것입니다.
스테이블 디퓨전 v1은 512x512 이미지에 대해 미세 조정(fine-tuned)되었습니다. 따라서 이보다 큰 이미지를 생성하려면 물체가 겹쳐지는 현상이 발생할 수 있습니다. 이런 영상처럼요.
이미지 확대(upscaling)
SD v1 모델을 사용해 큰 이미지를 생성할 경우, 적어도 한쪽은 512에 맞추고 나중에 AI 확대도구를 사용하는 것이 좋습니다.
또는 SDXL 모델을 사용하시면 좋습니다. SDXL은 1024x1024 크기로 학습되었기 때문입니다. 또한 이미지 품질도 대부분 뛰어납니다.
잠재 공간이 가능한 이유
지금까지의 설명을 읽어보면, VAE를 사용해 이미지를 훨씬 작은 잠재 공간으로 압축한다고 했는데, 어떻게 정보에 손상이 없이 가능한지 궁금하실 수 있습니다. 이는 대부분의 이미지가 무작위가 아니기 때문입니다. 즉, 자연적 이미지는 규칙성이 높다는 뜻입니다. 얼굴을 예를 들면 눈, 코, 입 사이에는 특정한 공간적 관계가 존재합니다. 나무를 그리면 녹색 픽셀 바로 옆에는 녹색 픽셀이 나올 확률이 매우 높죠. 이런 것이 공간적 관계입니다.
다른 말로 하면, 자연적 이미지는 이러한 정보의 손상없이 잠재 공간으로 압축하는 것이 가능하다는 뜻입니다. 이를 머신 러닝에서 다중체 가설(manifold hypothesis)라고 합니다.
잠재 공간에서의 역방향 디퓨전
위에서 이미지 공간에서의 역방향 디퓨전에 대해 설명했는데, 잠재공간(latent space)에서의 역방향 디퓨전은 다음과 같이 작동됩니다.
- 무작위 잠재 공간 행렬을 생성한다.
- 잡음 예측기(noise predictor)가 잠재 행렬의 잡음을 예측한다.
- 예측된 잡음을 잠재 행렬에서 제거한다.
- 지정한 샘플링 단계(sampling step)에 이를 때까지 2,3 단계를 반복한다.
- VAE 디코더(decoder)가 잠재 행렬로부터 최종 이미지로 변환한다.
VAE 파일
Stable Diffusion v1에서 VAE 파일의 목적은 눈과 얼굴을 향상시키는데 사용되었습니다. VAE파일이 방금 언급한 자동인코더(autoencoder)의 디코더입니다. 디코더를 세부 조정하면 훨씬 나은 이미지가 생산될 수 있습니다.
위에서 가변 자동 인코더로 이미지를 압축하면 정보 손실이 없다고 언급했는데, 사실 잘못된 표현이었습니다. 전체적인 형태는 문제가 없지만, 세세한 부분은 정보가 손실되어 복구하지 못하기 때문입니다. 대신 VAE 디코더가 미세한 세부 사항을 그려내는 역할을 하게됩니다.
조건부여(Conditioning)
이제까지 설명한 것에는 심각한 결함이 있습니다. 어디에도 텍스트 프롬프트가 들어갈 곳이 없다는 거죠. 즉, 이상의 모델에서는 이미지를 VAE 인코더를 통해 잠재공간으로 압축하고, 잠재공간에서 이미지를 학습하여 모델을 생성하는 학습과정과, 모델에서 잡음 예측기를 사용해 잡음을 제거하여 잠재공간상의 이미지를 생성하고 이를 VAE 디코더를 통해 이미지를 생성하는 과정으로 나눌 수 있는데, 여기 어디에도 텍스트 프롬프트는 개입되지 않는다는 점입니다.
즉, 이 상태로는 잠재공간의 학습 데이터에서 이미지를 뽑으면 그냥 알아서 뽑을 뿐, 어떤 이미지를 뽑으라고 지시할 수 없어서 무작위로 이미지가 튀어 나오게 되는 겁니다. 위의 예라면 강아지가 나올 수도 있고 고양이도 나올 수도 있는 겁니다.
이를 위해 조건부여(conditioning)가 필요합니다. 조건부여의 목적은 잡음 제거기를 제어하여 이미지에서 예측된 잡음 제거한 결과가 우리가 원하는 것이 되도록 몰아가는 것입니다.
텍스트 조건부여(text-to-image)
아래는 텍스트 프롬프트가 처리되어 잡음 예측기로 들어가는 방법을 개략적으로 나타낸 그림입니다. 먼저 프롬프트에 포함된 단어들을 토큰생성기(Tokenize)가 토큰(token)이라고 하는 숫자로 변환합니다. 각각의 토큰은 임베딩(embedding)이라고하는 769 개 값의 벡터로 변환됩니다.(이게 AUTOMATIC1111에서 사용하는 임베딩과 동일합니다.) 다음으로 텍스트 변환기(text transformer)가 임베딩을 처리하여 노이즈 예측기(noise predictor)가 사용할 수 있는 데이터를 생성하게 됩니다.
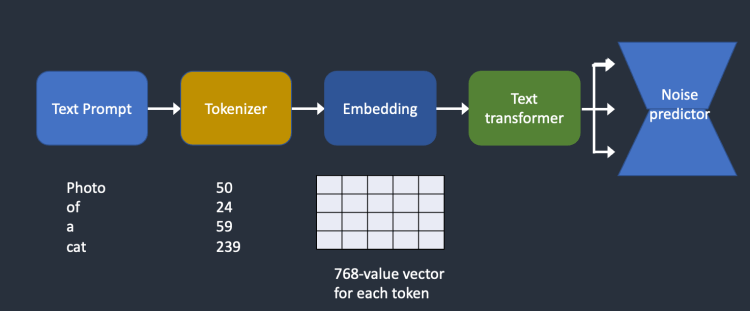
이제 이 그림에 포함된 각각의 부분에 대한 자세히 살펴보겠습니다. 위에 있는 개요만으로 충분하다면 다음 절로 넘어가셔도 됩니다.
토큰 생성기(Tokenizer)
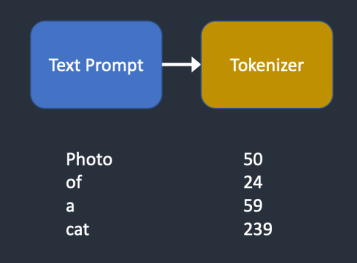
먼저 텍스트 프롬프트는 CLIP tokenizer를 통해 토큰으로 바뀌게 됩니다. CLIP(Contrastive Language-Image Pre-Training)은 OPEN AI에서 개발한 딥러닝 모델로서, 이미지에 대한 텍스트 설명을 설명하기 위해 사용됩니다. Stable Diffusion v1은 CLIP의 토큰생성기를 사용합니다.
토큰화(Tokenization)는 컴퓨터가 단어를 이해하는 방법입니다. 사람들은 단어를 읽을 수 있지만, 컴퓨터는 숫자를 읽을 뿐이고, 따라서 사람이 입력한 단어들은 토큰화를 통해 숫자로 변환되어야 컴퓨터가 읽을 수 있습니다.
토큰생성기는 자신이 학습할 때 보았던 단어들만 토큰으로 변환할 수 있습니다. 예를 들어, CLIP 모델에 "dream"과 "beach"는 있는데 "dreambeach"는 없다고 가정하면, 토큰 생성기는 dreambeach를 분해해서 "dream"과 "beach"라는 두 개의 토큰으로 변환하게 됩니다. 이처럼 하나의 단어가 반드시 하나의 토큰에 대응되는 것이 아닙니다.
또 한 가지 주의할 점은 공백(space)도 토큰의 일부라는 점입니다. 위의 예에서 "dream beach"는 "dream"과 " beach"(beach 앞에 공백이 있음) 이라는 두 개의 토큰으로 변환됩니다. 이 토큰은 "dreambeach"에서 생성된 "dream"과 "beach"(beach 앞에 공백 없음)와 다르게 됩니다.
Stable Diffusion 모델은 프롬프트에서 75개의 토큰만 사용하도록 제한하고 있습니다. 단 75개의 토큰은 75개의 단어가 아니라는 점을 다시한 번 상기시켜 드립니다.
임베딩(Embedding)
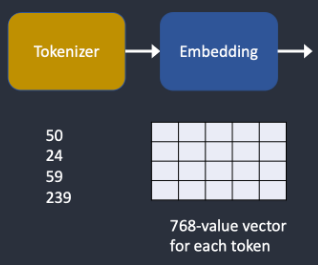
스테이블 디퓨전 v1은 OPEN AI의 VoT-L/14 CLIP 모델을 사용합니다. 임베딩은 768개의 값을 갖는 벡터입니다. 각각의 토큰은 각각의 고유한 임베딩 벡터를 갖고 있습니다. 임베딩은 CLIP 모델에서 생성되어 고정되어 있습니다. 다시 말해서 학습과정에서 임베딩이 결정되는 것입니다.
왜 임베딩이 필요한 걸까요? 임베딩은 일부 단어들이 서로 연관되어 있기 때문입니다. 예를 들어 man, gentleman, guy 등의 단어는 거의 동일합니다. 실세계에서 바꿔가며 사용되기 때문입니다. 다른 예로 Monet(모네), Manet(마네), 드가(Degas)는 모두 인상주의 화가이지만, 그림 스타일은 약간씩 다름니다. 이들 이름은 밀접하지만 동일하지는 않은 임베딩입니다. 결과적으로 임베딩에는 하나의 토큰에 대응되는 768개의 다른 토큰과의 연관성을 담고 있다고 생각하면 될 것 같습니다.
임베딩을 적절히 사용하면 마술을 부릴 수 있습니다. 과학자들은 적절한 임베딩을 찾아내면, 임의의 물체와 스타일을 발동시킬 수 있다는 것을 발견했습니다. 이것이 텍스트 인버전(textual inversion)이라고 하는 세밀 조정 기법입니다.
임베딩을 잡음 생성기에 넣기
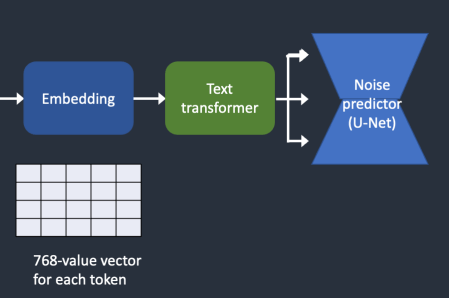
그 다음으로 임베딩은 텍스트 트랜스포머(text transformer)에서 처리된 후 잡음 예측기에 공급됩니다. 트랜스포머(transformer)는 조건부여(conditioning)를 위한 범용 어댑터와 같습니다. 이 예에서 텍스트 트랜스포머의 입력은 텍스트 임베딩 벡터이지만, 클래스 라벨, 이미지 혹은 깊이 맵(depth map)도 트랜스포머에 입력될 수 있습니다. 트랜스포머는 데이터를 추가로 처리할 뿐 만 아니라, 다양한 조건부여 방식을 수용할 수 있는 메카니즘도 제공합니다.
교차 인지(cross-attention)
U-Net 전체에서 노이즈 예측기는 텍스트 트랜스포머의 출력을 여러 번 사용합니다. U-Net은 교차 인지(crosss-attention) 메커니즘을 통해 이를 사용합니다. 여기가 바로 프롬프트가 이미지와 만나는 지점입니다.
"파란 눈을 가진 남자"라는 프롬프트를 예로 들어 보겠습니다. 스테이블 디퓨전은 "파란색"과 "눈"이라는 두 단어를 함께 짝을 지어(프롬프트 내의 셀프 인지) 파란 눈을 가진 남자를 생성합니다. (하지만 파란 셔츠를 입은 남자는 생성하지 않습니다.) 그런 다음 이 정보를 사용하여 역방향 확산과정에서 파란 눈이 포함된 이미지로 유도됩니다. (프롬프트와 이미지 간 교차 인지)
참고: Stable Diffusion 모델에서 미세 조정하는 기술인 하이퍼 네트워크(hypernetwork)는 교차 인지(cross-attention) 네트워크를 가로채어 여러가지 스타일을 삽입합니다. LoRA 모델은 교차 인지(cross-attention) 모듈의 가중치를 수정하여 특정한 스타일을 변경합니다. 교차 인지 모듈을 수정하는 것만으로도 Stable Diffusion 모델을 미세 조정할 수 있다는 사실로부터, 이 모듈이 얼마나 중요한지 알 수 있습니다.
기타 조건부여
Stable Diffusion 모델에서 텍스트 프롬프트 이외의 조건부여(conditioning) 기법도 존재합니다. depth-to-image 모델의 조건부여는 텍스트 프롬프트와 깊이(depth)이미지를 함께 사용하는 방법이 사용됩니다. ControlNet의 경우, 외곽선이나 사람의 자세 등으로 잡음 제거기에 조건부여함으로써, 이미지 생성시 원하는 구도를 제어할 수 있습니다.
Stable Diffusion 의 처리 단계
지금까지 스테이블 디퓨전 모델의 내부적인 작동 방식에 대해 알아보았습니다. 지금부터는 스테이블 디퓨전을 작동할 때 어떠한 일이 일어나는지 몇가지 예를 들어 알아 보겠습니다.
Text-to-Image
txt2img는 텍스트 프롬프트를 입력해 이미지를 얻는 기능입니다.
1단계 : Stable Diffusion은 잠재 공간(latent space)에 무작위 텐서(random tensor)를 생성합니다. 이때, 씨드(seed)번호를 사용해 무작위 숫자 생성기(random number generatior)를 통해 무작위 텐서를 제어할 수 있습니다. 씨드를 특정한 값으로 입력하면, 항상 동일한 무작위 텐서가 만들어집니다. 무작위 텐서가 바로 잠재 공간에 있는 이미지입니다. 다만, 이때에는 모든 이미지가 잡음일 뿐이죠.

2단계 : 잡음 예측기(U-Net)가 잠재 잡음 이미지와 텍스트 프롬프트를 입력받아 잡음을 예측합니다. 이 과정도 잠재 공간(4x64x64 텐서)에서 시행됩니다.
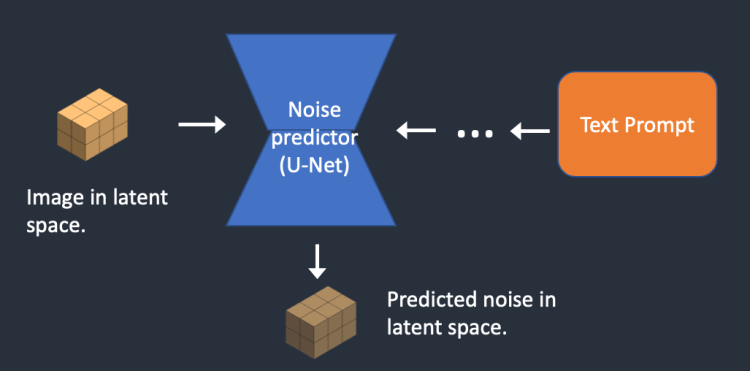
3단계 : 잠재 이미지에서 잠재 잡음을 제거합니다. 그 결과는 새로운 잠재 이미지입니다.

2단계와 3단계는 정해진 샘플링 단계(예: 20회) 동안 반복됩니다.
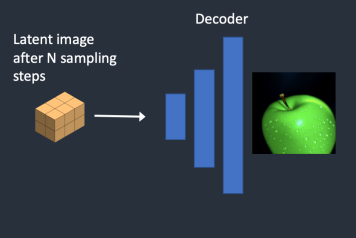
4단계 : 최종적으로 VAE 디코더가 잠재 이미지를 픽셀 공간으로 보내어 이미지를 생성합니다. 이것이 스테이블 디퓨전을 돌리면 생성되는 이미지입니다.
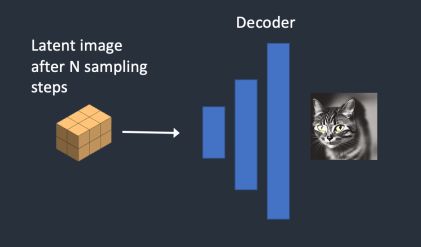
아래는 각 샘플링 단계에서 이미지가 변화하는 과정입니다.
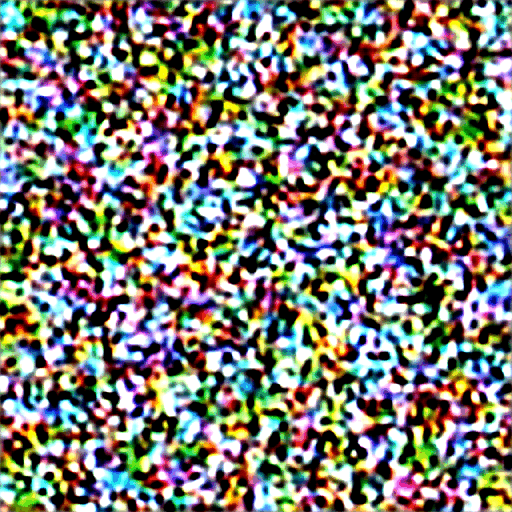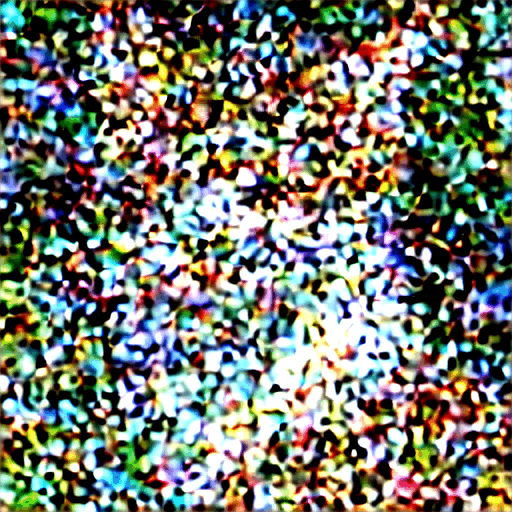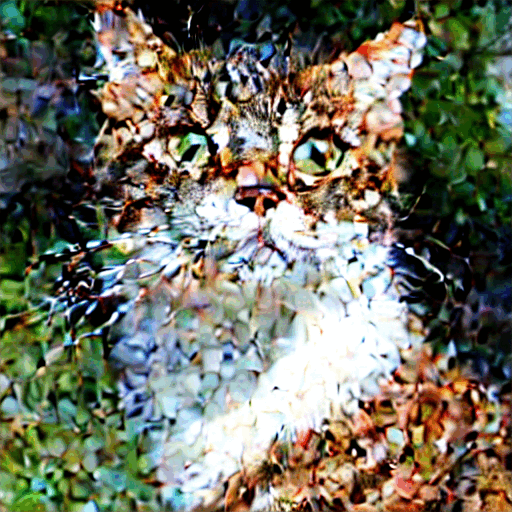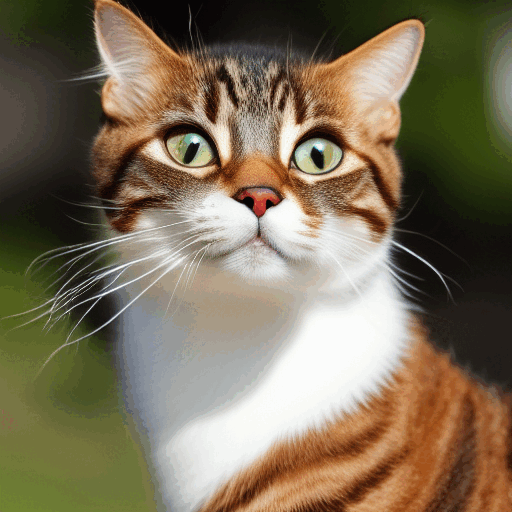
잡음 스케줄(Noise schedule)
위에서 보는 것처럼 Stable Diffusion의 이미지는 완전 잡음으로부터 점차 깨끗해집니다. 초기 단계에서는 잡음 예측기(noise predictor)가 제대로 작동하지 않는 것처럼 보이시나요?사실 이것은 부분적으로만 사실입니다. 진짜 이유는 각 샘플링 단계에서 예상되는 잡음에 도달하려고 노력하기 때문입니다. 이를 잡음 스케줄(noise schedule)이라고 합니다. 아래는 그 예시입니다.
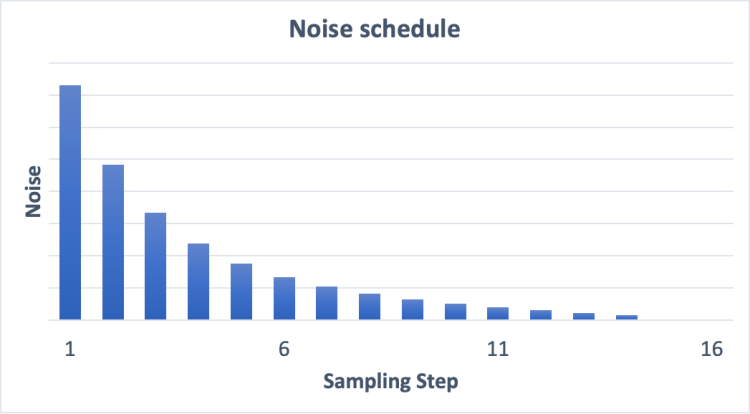
잡음 스케줄을 우리가 정의합니다. 각 단계에서 동일한 양만큼 제거하도록 할 수도 있고, 위 그림처럼 처음에 많이 제거하도록 할 수도 있습니다. 샘플링 알고리즘은 다음 단계에서 예상되는 잡음에 도달한 만큼만 잡음을 제거합니다. 이 때문에 우리는 단계별 이미지를 볼 수 있습니다.
Image-to-Image
Image-to-image는 어떤 이미지를 스테이블 디퓨전을 사용해 다른 이미지로 변환하는 기법입니다. Image-to-Image는 SDEdit 방법에서 처음으로 제안된 방법입니다. SDEdit는 어떠한 디퓨전 모델에도 적용할 수 있습니다. 이 때문에 우리는 Stable Diffusion(잠재 확산 모델)에서 image-to-image 기능을 볼 수 있습니다.
Image-to-Image에서는 이미지와 텍스트 프롬프트가 입력으로 사용됩니다. 생성된 이미지는 입력 이미지와 텍스트 프롬프트로 조건부여(conditioning)됩니다. 예를 들어 아래 왼쪽 그림의 아마추어 그림과 프롬프트 "photo of perfect green apple with stem, water droplets, dramatic lighting"를 입력으로 사용하면, 스테이블 디퓨전은 우측과 같은 전문가적인 그림으로 바꾸어줍니다.
 |
 |
 |
1 단계 : 입력 이미지가 잠재 공간으로 인코딩 됩니다.
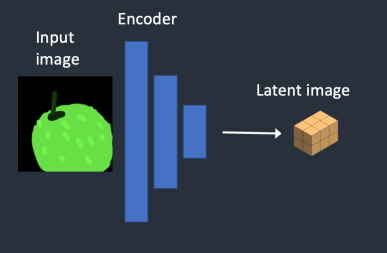
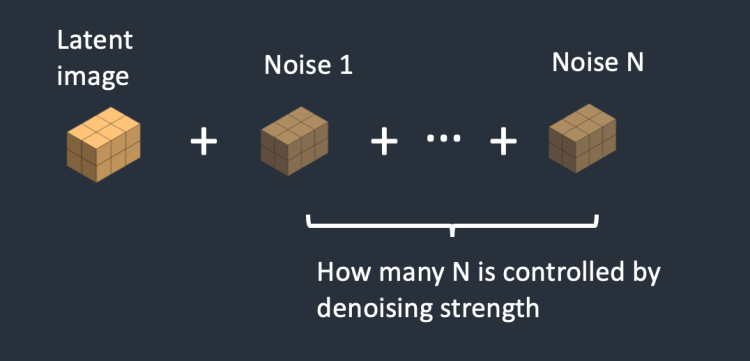
2 단계 : 잠재 이미지에 잡음 추가됩니다. 이때 잡음 제거 강도(Denoising strength) 값에 따라 추가되는 잡음의 양이 결정됩니다. 0으로 설정할 경우 잡음이 추가되지 않으며, 1일 경우, 잡음이 최대치로 추가되어, 잠재 이미지가 완전한 무작위 텐서(random tensor)가 됩니다.
3 단계 : 잡음 예측기(noise predictor) U-Net이 잠재 잡음 이미지와 텍스트 프롬프트를 입력으로 받아, 잠재 공간(4x64x64 텐서)에서 잡음을 예측합니다.
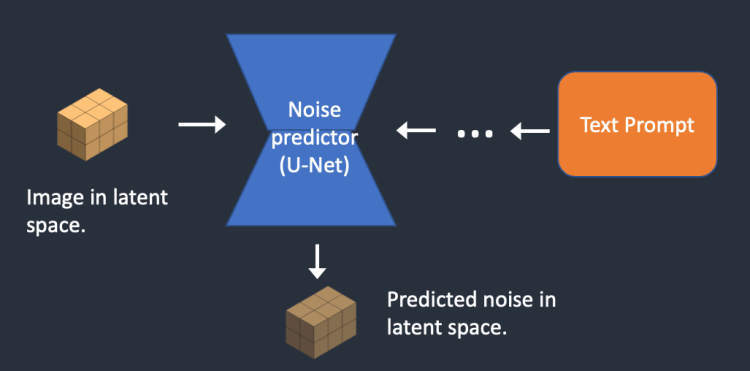
4 단계 : 잠재 이미지에서 잠재 잡음을 제거합니다.. 그 결과 새로운 잠재 이미지가 생성됩니다.

3 단계 4단계는 지정된 샘플링 단계(예 20회)만큼 반복됩니다.
5 단계 : 마지막으로 VAE(가변 자동 인코더)의 디코더가 잠재 이미지를 픽셀 공간으로 내보냅니다. 이렇게 나온 결과가 image-to-image 의 결과가 됩니다.
요약하면, image-to-image가 text-to-image와 다른 점은, 입력된 이미지에 약간의 잡음을 추가한 초기 잠재 이미지가 입력으로 사용되는 것 뿐입니다. 참고로 잡음 제거 강도(denoising strength)를 1로 설정하면, 초기 잠재 이미지가 완전한 무작위 노이즈가 되어 버리기 때문에 text-to-image와 동일하게 됩니다.
인페인트(Inpainting)
인페인트(Inpaint)는 image-to-image의 특별한 경우일 뿐입니다. 그림 전체가 아니라 인페인트시 적용한 마스크 부분에 대해서만 잡음이 추가된다는 점만 다릅니다.추가되는 잡음의 양은 일반 image-to-image와 마찬가지로 잡음 제거 강도에 의해 제어됩니다.
Depth-to-Image
Depth-to-Image는 image-to-image를 더욱 진보시킨 것입니다. 즉, 깊이 맵(depth map)을 사용하여 추가적인 조건부여(conditioning)를 적용하여 새로운 이미지를 생성합니다.
1 단계 : 입력 이미지가 잠재 공간으로 인코딩됩니다.
2 단계 : MiDas(AI 깊이 모델)가 입력된 이미지의 깊이 맵을 추정합니다.
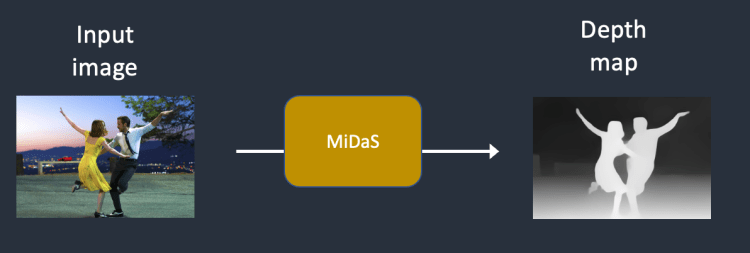
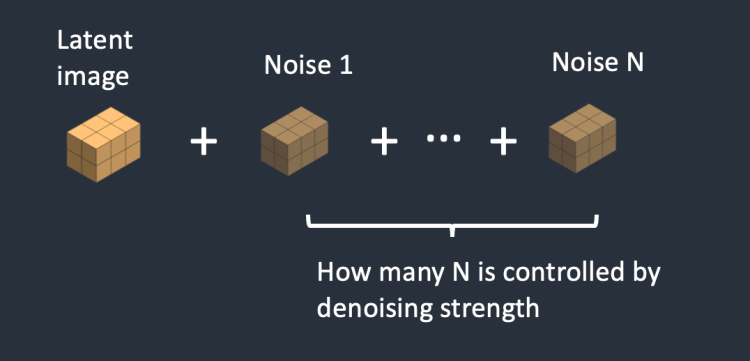
3 단계 : 잠재 이미지에 잡음을 추가합니다. 추가되는 잡음의 양은 잡음 제거 강도(denoising strength)에 의해 결정됩니다. 잡음 제거 강도가 0이면 잡음이 추가되지 않고, 1이면 잡음이 최대치로 추가되어 잠재 이미지가 무작위 텐서(random tensor)가 됩니다.
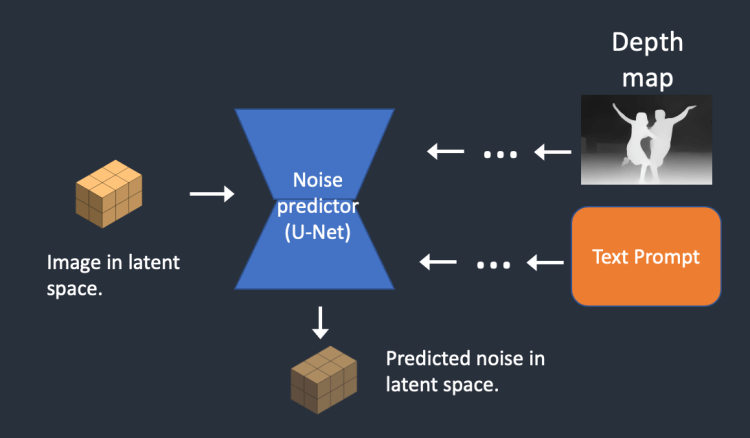
4 단계 : 잡음 예측기가 잠재공간의 잡음을 예측합니다. 이때 텍스트 프롬프트와 깊이 맵을 조건부여로 사용합니다.
5 단계 : 잠재 이미지에서 잠재 잡음을 제거합니다. 그 결과 새로운 잠재 이미지가 생성됩니다.
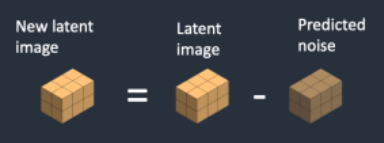
4 단계와 5 단계는 샘플링 단계 수만큼 반복됩니다.
6 단계 : VAE(가변 자동 인코더)의 디코더가 잠재 이미지를 디코딩합니다. 이렇게 나온 결과가 depth-to-image 의 결과가 됩니다.
무분류기 안내(CFG, Classifier-Free Guidance)
이미지 생성형 인공지능을 사용하다보면, 분류 자유도 척도를 고민하지 않을 수 없습니다. CFG가 무엇인지 이해하려면 먼저 분류기 안내(classifier guidance)에 대해 알아볼 필요가 있습니다.
분류기 안내(classifier guidance)
분류기 안내는 디퓨전 모델에서 이미지 레이블을 통합하는 방법입니다. 레이블을 사용하여 확산 프로세스의 방향을 안내할 수 있습니다. 예를 들어 "cat"이란 레이블은 역방향 확산 프로페스가 고양이 사진을 생성하도록 유도합니다.
분류기 안내 척도(classifier guidance scale)란 디퓨전 프로세스가 얼마나 밀접하게 레이블을 따를 것인지를 제어하는 파라미터입니다. 아래의 그림은 이 논문에서 나온 예인데, 3개의 그룹의 이미지에 각각 "cat", "dog", "human"이라고 레이블이 붙었다고 가정합니다. 디퓨전이 아무런 안내/유도를 받지 않는다면, 무작위로 각 그룹의 전체 모집단에서 샘플을 추출하게 됩니다. 때로는 두개의 레이블에 맞는 이미지 (예: 개를 쓰다듬는 소년)를 추출할 경우도 발생할 수 있습니다.
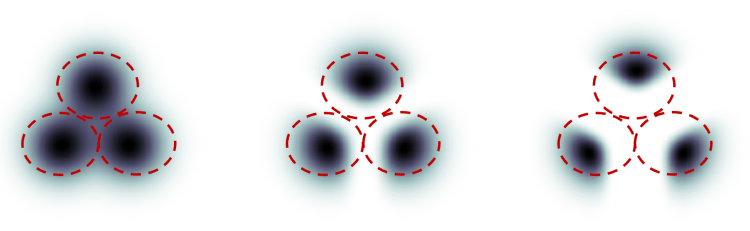
분류기 안내 척도를 높은 값으로 설정할 경우, 디퓨전 모델은 극단적으로 모호성이 없는 이미지를 생성합니다. 예를 들어 "cat"을 요청할 경우, 다른 것은 없고 고양이만 있는 이미지가 반환될 수 있습니다.
분류기 안내 척도(classifier guidance scale)는 안내(프롬프트)를 얼마나 밀접하게 따를지를 제어합니다. 위의 그림에서 CFG를 높게 설정하면 맨 오른쪽에 있는 그림과 같은 상태가 됩니다. 즉, cat을 요청하면 human이나 dog이 나올 확률은 거의 없게 되는 겁니다.
무분류기 안내(Classifier-free guidance)
분류기 안내는 놀라운 성능을 발휘하지만, 이러한 안내를 제공하려면 추가적인 모델이 필요합니다. 이로 인해 학습에 약간의 어려움이 존재합니다.
무분류기 안내(classifier-free guidance)는 거칠게 말해 "분류기가 없이 분류기 안내"를 달성하는 방법입니다. 클래스 레이블과 별도의 모델을 사용하여 안내하는 대신, 이미지 캡션을 사용하고 text-to-image 방식에서 설명한 것과 동일한 조건부여(conditioning)방식으로 디퓨전 모델을 훈련하는 방법입니다.
이들은 분류기 부분을 잡음 예측기인 U-Net의 조건부여(conditioning)로 둠으로써, 이미지 생성에서 소위 "분류기 없는"(즉, 별도의 이미지 분류기가 없는) 안내를 달성했습니다.
텍스트 프롬프트는 text-to-image에서 이 안내를 제공합니다.
CFG 값
이제 조건부여를 통하여 무분류기 디퓨전 프로세스를 확보했는데, 안내를 얼마나 따를지는 어떻게 제어해야 할까요? 무분류기 안내(CFG) 척도는 텍스트 프롬프트 조건부여를 디퓨전 프로세스가 얼나나 따를지를 제어하는 값입니다. 이 값을 0으로 두면 이미지 생성은 조건부여 없이(즉, 프롬프트가 무시됨) 이루어집니다. 높은 값을 부여할 수록 디퓨전은 프롬프트를 따라가게 됩니다.
스테이블 디퓨전 v1 과 v2 비교
모델의 차이
스테이블 디퓨전 블로그에 따르면, 스테이블 디퓨전 v2는 텍스트 임베딩에 OpenClip을 사용합니다. (반면, Stable Diffusion v1은 OPEN AI의 CLIP ViT-L/14를 사용합니다.) 이유는 아래와 같습니다.
- OpenClip은 크기가 5배 큽니다. 텍스트 인코더 모델이 클 수록 이미지의 품질이 올라가게 됩니다.
- Open AI의 CLIP 모델이 오픈 소스이기는 하지만, 이 모델은 독점적인 데이터를 사용하여 학습되었습니다. OpenClip 모델로 바뀌게 됨으로써, 연구자들은 모델을 연구하거나 최적화할 때 더욱 투명하게 진행할 수 있게 되었습니다. 결과적으로 장기적인 발전에 도움이 될 것입니다.
학습 데이터의 차이
Stable Diffusion v1.4의 학습데이터는 다음과 같습니다.
- laion2B-en 데이터 셋의 256x256 해상도에서 237k 단계
- laion-high-resolution 데이터 셋의 512x512 해상도에서 194k 단계
- laion-aesthetics v2 5+ 의 512x512 에서 225k 단계(텍스트 조건부여에서 10% 감소)
Stable Diffusion v2의 학습데이터는 다음과 같습니다.
- 음란물에 대해 필터링된 LAION-5B 하위 집합의 해상도 256x256에서 550만 단계. (punsafe=0.1 및 aesthetic score(미적 점수) >= 4.5의 LAION-NSFW 분류기를 사용함)
- 동일한 데이터 세트에서 해상도 >= 512x512인 이미지에 대해 해상도 512x512로 850만 단계
- 동일한 데이터 세트에서 v-objective을 사용하여 15만 단계
- 768x768 이미지에 대해 140만 단계를 다시 시도
Stable Diffusion v2.1은 v2.0에 대해 다음과 같은 세부조정을 실시했습니다.
- 동일한 데이터 셋에 대하여 추가로 55k 단계(punsafe=0.1 로 설정)
- punsafe=0.98을 설정하여 추가로 155k 단계
즉, 기본적으로 마지막 학습단계에서 NSFW 필터를 사용하지 않았습니다.
차이 극복 방법
사용자들은 일반적으로 Stable Diffusion v2 를 사용할 때 스타일 제어가 힘들고 유명인 생성이 힘들다고 합니다. Stability AI 에서 예술가 및 유명인 이름을 명시적으로 필터링하지는 않았지만, v2에서는 그 효과가 훨씬 약해졌다고 하네요. 이는 아마도 학습 데이터에 의한 차이 때문으로 보입니다. Open AI의 독점 데이터에는 예술 작품과 유명인 사진이 더 많이 포함되어 있을 수 있습니다. 이러한 사진이 빠져서 발생하는 일로 보입니다.
다만, v2 및 v2.1 모델은 그다지 많이 사용되지 않습니다. 대부분 미세조성된 v1.5 모델과 SDXL 모델을 더 많이 사용합니다.
SDXL 모델
SDXL 모델은 v1 및 v2 모델에 대한 공식적인 업그레이드 모델입니다. 이 모델은 오픈소스로 공개되었습니다.
SDXL은 v1 및 v2 에 비해 모델의 크기가 훨씬 큽니다. AI 세계에서 모델 크기가 크다는 것은 성능이 좋다는 것과 동등합니다. v1.5의 경우 파라미터 수는 9.8억개 정도였는데, SDXL 모델의 경우 66억개로 늘어났습니다.
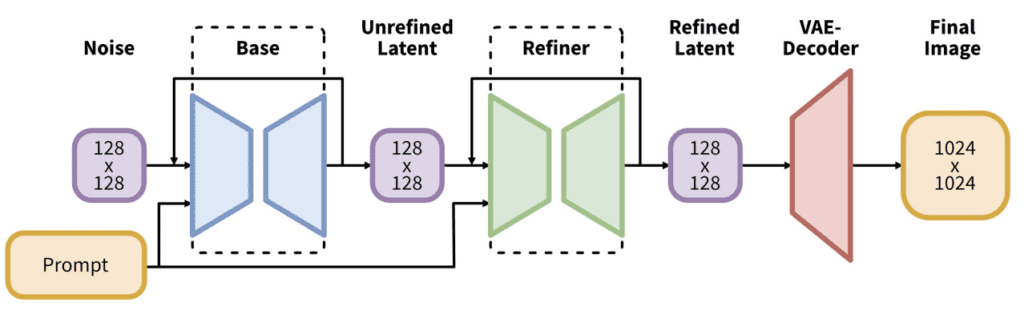
SDXL 모델은 두개의 모델로 구성되어 있습니다. 먼저 base 모델을 돌리고나서 refiner 모델을 돌리게 됩니다. base 모델은 전반적인 구성을 설정하고, refiner 모델은 세밀한 부분을 추가하는 역할을 합니다.
물론 base 모델만 돌려도 무방합니다.
SDXL base 모델은 이전 버전에 비해 아래와 같은 차이가 있습니다.
- 텍스트 인코더가 가장 큰 OpenClip 모델(ViT-G/14)와 OpenAI 독점 모델인 CLIP Vit-L이 결합되어 있습니다. 이렇게 함으로써 프롬프트를 쉽게 작성할 수 있게 되었고, 강력하면서도 학습가능한 OpenClip을 유지하였기 때문입니다.
- 새로운 이미지 크기 조건부여(conditioning)을 도입하여 256x256 크기의 이미지도 학습시켰습니다. 이렇게 함으로써 전체 데이터세트중 39%에 달하는 학습데이터를 버리지 않고 사용하였습ㄴ디ㅏ.
- U-Net가 v1.5보다 3배가량 커졌습니다.
- 기본 이미지 사이즈가 1024x1024가 되었습니다. 이는 v1.5 모델의 기본 이미지 크기(512x512)에 비해 4배나 커진 것입니다.
추가 정보
- Stable Diffusion v1.4 보도 자료
- Stable Diffusion v2 보도 자료
- Stable Diffusion v2.1 보도 자료
- High-Resolution Image Synthesis with Latent Diffusion Models – Stable Diffusion을 소개한 연구 논문
- The Illustrated Stable Diffusion – 모델 아키텍처에 대한 약간 상세한 설명
- Stable Diffusion 2 – 공식 모델 페이지
- Diffusion Models Beat GANs on Image Synthesis – 분류기 안내에 대한 연구 논문
- Classifier-Free Diffusion Guidance – 무분류기 안내를 소개한 연구 논문
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics – 역방향 디퓨전 프로세스
==========
이상입니다. 이 글은 Andrew님이 작성한 글 How does Stabel Diffusion work? 을 거의 그대로 번역하였습니다. 약간 수정은 물론 들어 있습니다만, 이번엔 작품이 아니라 거의 이론적인 내용이라 고치기가 힘들었네요.
민, 푸른하늘
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- Stable Diffusion - 모델에 대한 모든 것
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기