며칠전에 DreamBooth 에 대한 소개 글을 올렸습니다. 간단히 요약하면, 나만의 피사체(우리 가족이나 우리집 멍뭉이, 내가 좋아하는 피규어, 내가 이번에 산 책등)의 사진을 4-5장 정도만 학습시켜 인공지능 이미지 생성에 사용할 수 있다는 내용입니다. 이미지 생성형 인공지능으로 자기 자신이던 누구던 아무나 끼워넣을 수 있고, 어떤 배경으로도 이미지를 생성할 수 있다는 겁니다. 그러고 보면 Dream(꿈) Booth(칸막이 공간), 즉 꿈의 사진관이라고 할까요...
드림부스를 설치하고 사용하는 방법에 대한 글 그리고 영상이 여기저기 올라와 있습니다만, 저도 나름대로 정리해보고자 합니다. 그런데.... 원래는 AUTOMATIC1111 에 Dreambooth 확장을 붙여서 학습하는 방법을 생각했었습니다. 그런데 정리를 하다보니 제가 현재 사용중인 사양(VRAM 8GB)로는 드림부스를 학습시키기에 부족하다는 것을 알게되었습니다(LoRA 로만 가능하다고 합니다). 그래서 그냥 Google Colab에서 Dreambooth를 학습시키는 방향으로 틀었습니다.
이미지 준비하기
먼저 학습시킬 이미지를 준비합니다. 학습시킬 사진은 가능한 한 아래와 같은 사진을 사용하는 게 좋다고 합니다. 특히 드림부스는 이미지 전체를 학습하기 때문에 피사체가 아닌 것은 자주 나타나지 않도록 하는 것이 좋다고 하네요.
- 가능한 한 고해상도 이미지
- 학습시킬 피사체를 다른 사물이 가리지 않을 것
- 구도가 간단할 것
- 다양할 것. 예를 들어 사람을 학습할 경우, 배경이나 조명, 의상, 표정, 포즈 등이 다양할 수록 좋음
또한 아래와 같은 사진은 피해야 한다고 합니다.
- 저해상도 - 학습시킬 해상도 보다 작은 이미지나, 압축에 의한 왜곡이 있는 이미지는 사용하지 말것
- 잘못 크롭된 이미지 - 클로즈업 사진만 입력하면 생성되는 이미지가 모두 클로즈업만 나오게 됨
- 중복사진 혹은 매우 비슷한 이미지 - 과적합이 발생하기 쉬움
- 피사체가 주 초점이 아닌 이미지
저는 그냥 고민하다가 구글에서 배우 박은빈 사진을 모아서 사용하기로 했습니다(그래도 가능한한 고해상도 사진만 모았습니다). 4-5장이면 충분하다지만, 20장 정도 준비했고요.
드림부스 학습은 원래 거의 모든 이미지 포맷과 거의 모든 크기를 지원합니다. 해상도가 다르면 자동적으로 크기를 조절하고 적당히 잘라내게 됩니다. 그런데 원하는 부분을 정확하게 잘라준다는 보장이 없으므로, 미리 512x512 크기로 정리해 주는 게 좋습니다.
이렇게 이미지를 정리해 주는 사이트는 birme.net 을 사용합니다. 이 링크를 따라가면 이미지 크기와 품질 등이 이미 설정되어 있으니 별다른 설정이 필요없습니다.
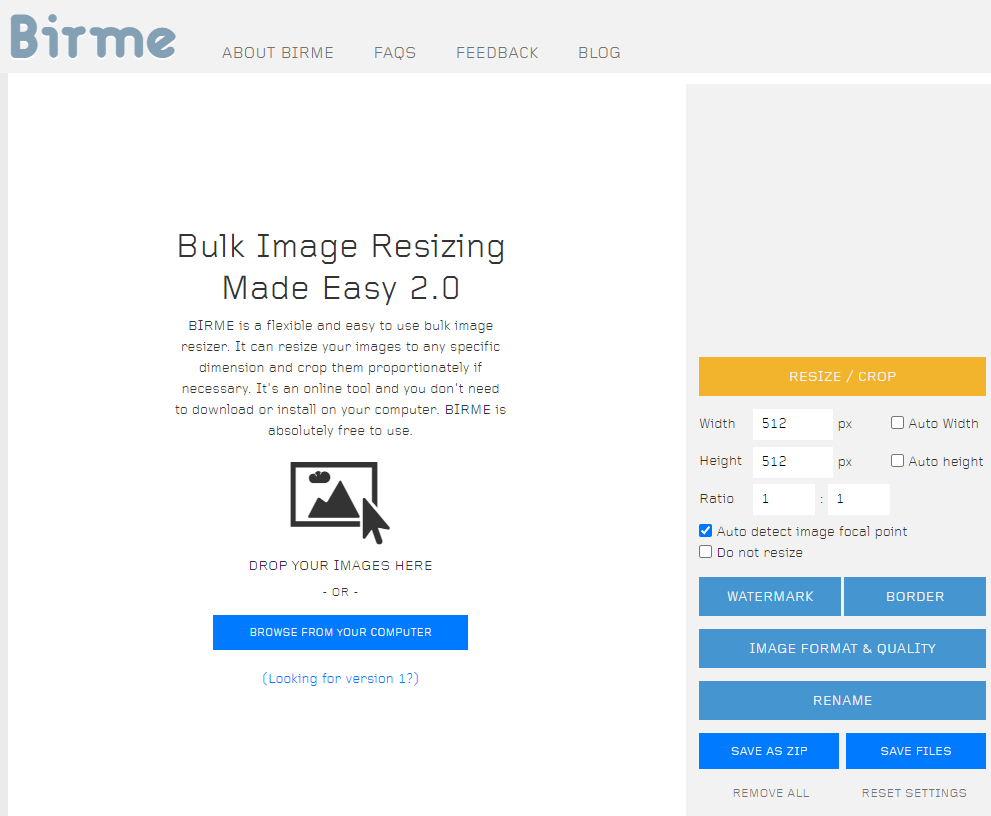
먼저 캔버스에 사진을 올립니다. Drag&Drop해도 되고 파란색 버튼을 눌러 불러오기를 해도 됩니다. 이미지를 불러들이면 아래처럼 됩니다. 여기서 정사각형 모양이 원하는 범위에 맞도록 조정해 줍니다.
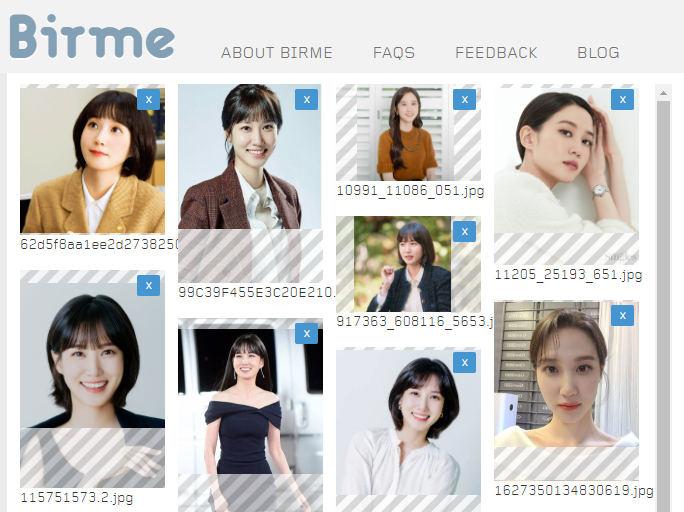
정리가 되면, 맨 아래쪽에 있는 [SAVE AS ZIP] 또는 [SAVE FILES]를 눌러서 원하는 폴더에 넣어주시면 됩니다. 보시는 것처럼 모든 사진이 정사각형 크기로 정리되었습니다.

이 글은 기본적으로 조코딩님의 유튜브를 기반으로 정리한 글입니다.
Dreambooth Colab 설치
제가 사용한 Dreambooth Colab은 TheLastBen 님이 개발한 버전입니다. TheLastBen님의 fast-stable-diffusion github에 들어가보면 아래와 같이 여러가지 내용이 포함되어 있습니다.
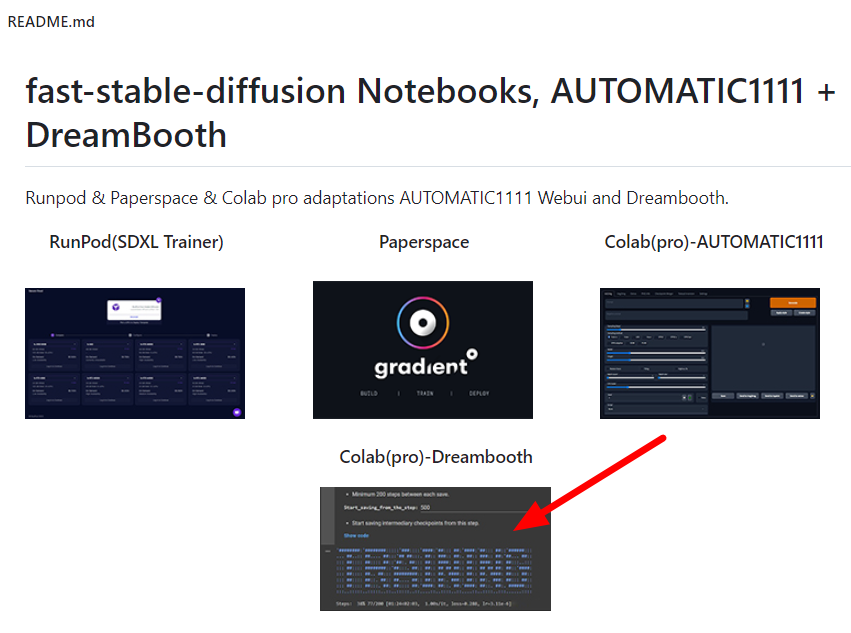
이중에서 화살표를 친 Colab(pro)-Dreambooth를 클릭하면 아래와 같이 Colab notebook으로 연결됩니다. 여기에서 Drive로 복사를 클릭하면 자신의 구글 드라이브로 이 노트북이 복사됩니다. (구글 드라이브의 루트에 'Colab Notebook'이라는 폴더 속에 들어가면 'fast-dreambooth.ipynb의 사본' 이라는 파일이 추가됩니다)
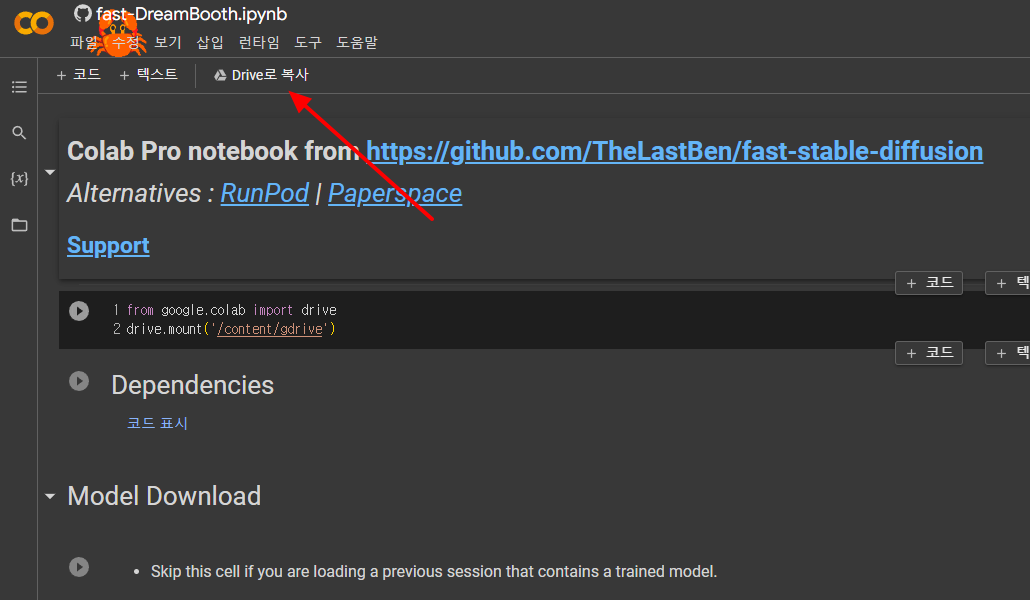
이제 원본은 닫고, 자신의 드라이브에 있는 사본을 사용해 작업하면 됩니다. 아래는 사본입니다. 보시는 것처럼 Drive로 복제라는 항목은 없습니다.
DreamBooth 실행
먼저 런타임 -> 런타임 유형 변경을 눌러, 아래와 같이 하으웨어 가속기가 GPU로 설정되어 있는지 확인합니다.

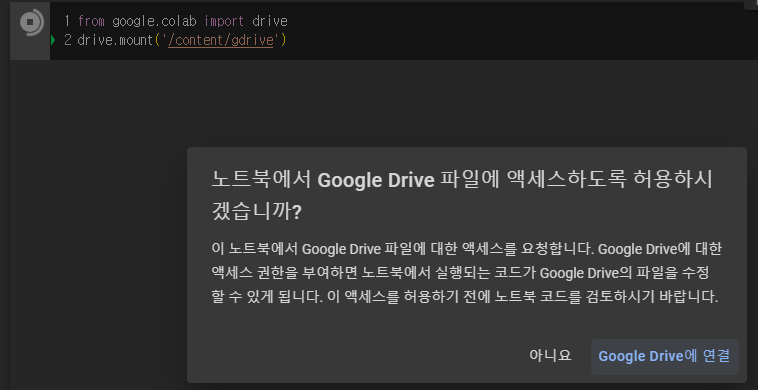
먼저 구글 드라이브를 연결하는 코드를 실행시킵니다. "from google.colab' 왼쪽에 있는 괄호를 누르면 아래와 같이 드라이브 접근 요청 화면이 나오는데, [Google Drive에 연결]을 눌러주시면 됩니다. 상황에 따라 로그인이 필요할 수도 있습니다.
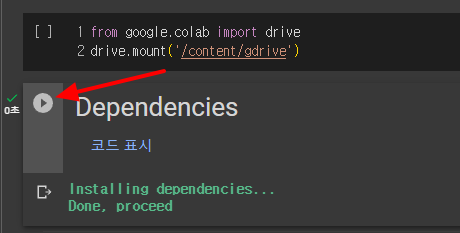
다음은 관련있는 여러가지 관련 모듈을 다운로드 받습니다. Dependencies 옆의 삼각형 동그라미를 누르면 실행이 됩니다.
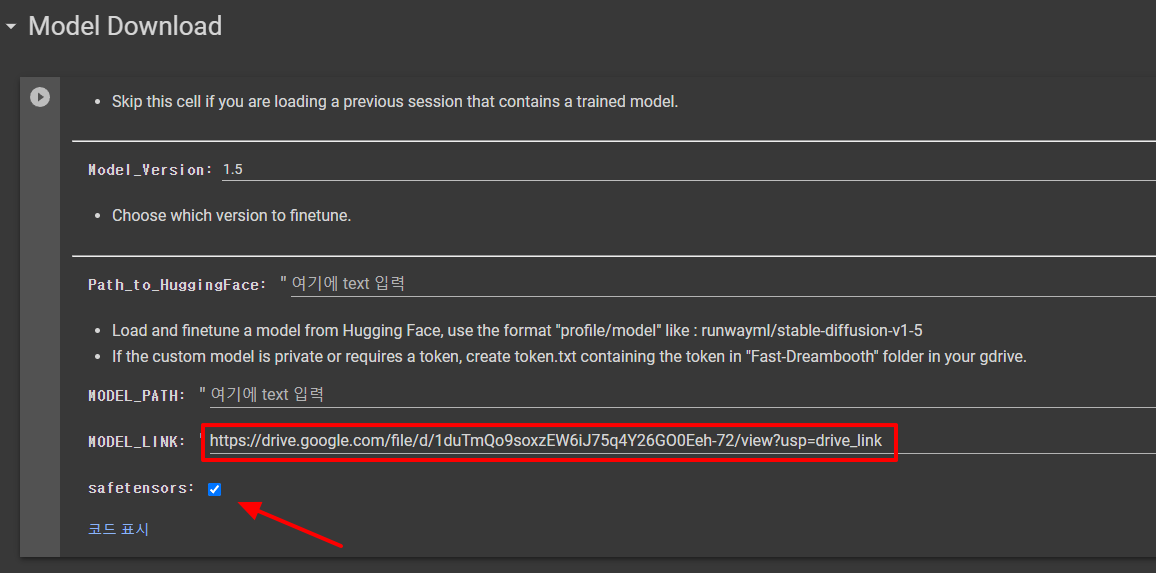
다음은 모델을 다운로드 받습니다. 제가 올리는 박은빈 배우는 아무래도 동양인이어서 ChilloutMix를 기반으로 학습시키기로 했습니다. 그래서 해당 파일을 구글 드라이브에 올리고, 링크를 복사해서 넣었습니다(단, 파일의 공유 권한을 추가로 설정해주어야 합니다. 저는 편집권까지 허용했습니다). 또한 이 파일이 .safetensor 포맷이라서 아래쪽에 체크를 해주었습니다. 살정이 끝나면 모델 다운로드 아래에 있는 삼각형 동그라미를 눌러 실행시켜줍니다.
다음은 Dreambooth 세션설정입니다. 세션명을 입력해주면 되는데, 각각의 프로젝트를 구분할 수 있도록 입력해주면 됩니다. 중간에 잘렸을 때, 여기에 동일한 이름을 써주면 다시 불러올 수 있다고 합니다.
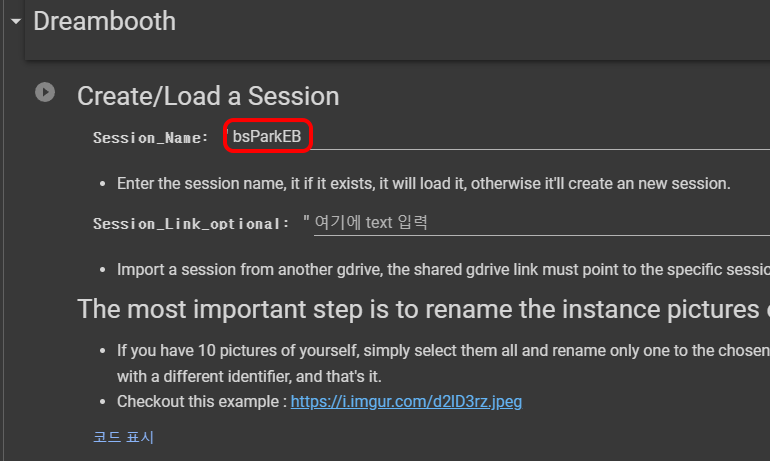
여기 맨 아래에 보면 "가장 중요한 단계..." 어쩌구 써져 있는데, 학습에 사용할 사진들의 이름을 통일시키라는 것입니다. 이때 파일명은 학습에 사용할 키워드로 입력해야 하는데, 이미 모델 내에 존재해서는 안되므로 가능한한 이상한 단어를 선정해야 합니다. 저는 bspeb을 키워드로 사용합니다. 먼저 모든 파일을 선택한 후 우클릭을 하여 이름 바꾸기를 실행한 뒤 bspeb라고 입력하고 엔터를 누르면 모두 아래 그림과 같이 바꿔집니다. 반드시!! 꼭!! 이렇게 바꿔주셔야 합니다. 왜냐하면 이 노트북에는 별도로 키워드를 입력하는 곳이 없고 여기에서 입력한 파일명이 키워드로 사용되기 때문입니다.
또한.... 원래는 관련된 클래스(class)를 입력해야 하는 걸로 아는데, 아무 곳에도 클래스를 입력할 수 없네요. 제 생각에는 이 노트북을 사용하는 건 문제가 있지 않나 싶습니다.

이제 이 파일들을 올릴 차례입니다. 이미 512x512로 크롭한 이미지를 올리므로, 화살표가 있는 Smart_Crop_images의 체크박스를 해제합니다. 그 다음 Instance Images왼쪽에 있는 동그라미 삼각형을 눌러 실행시키면, 맨 아래에 파일 선택 버튼이 나타납니다. 이 버튼을 누르고 파일을 선택해줍니다.
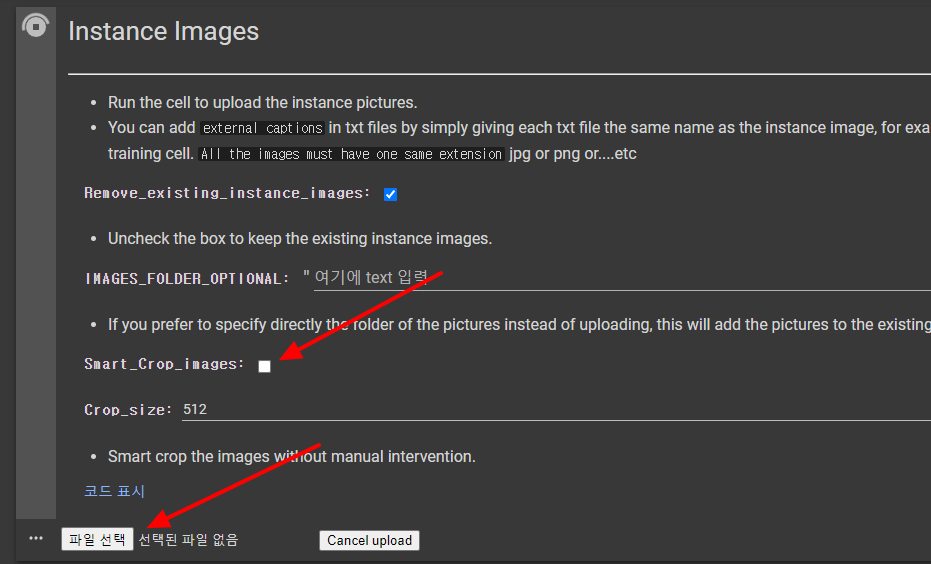
다음에는 Captions라는 항목이 있는데, 사람을 학습시킬 때는 필요없으므로 건너띕니다.

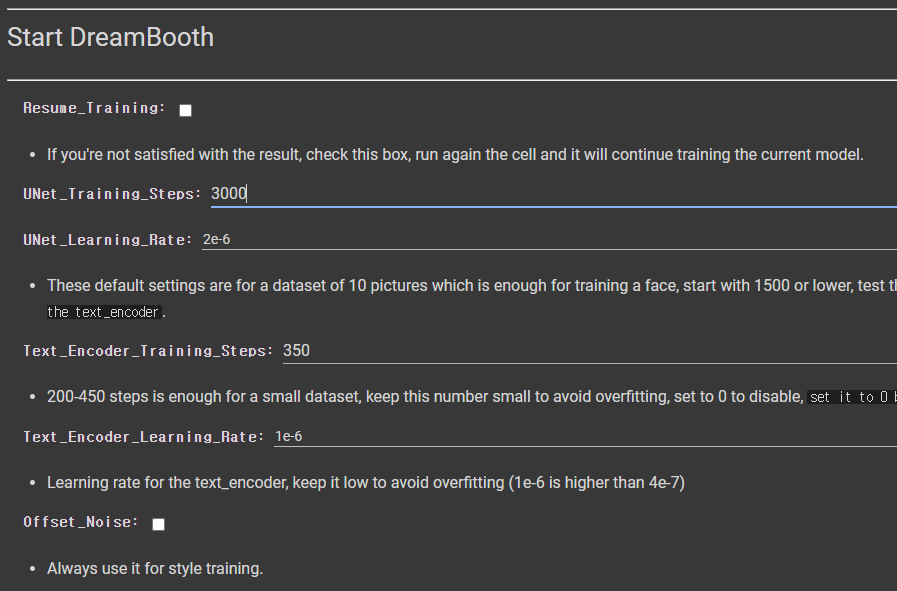
이제 학습을 위한 설정을 시작합니다. 여기서 가장 중요한 것은 UNet_Training_Steps입니다. 기본 값은 1500인데, 10개짜리 데이터세트용이라고 되어 있습니다. 저는 25개의 이미지를 사용하므로 150*25=3350 이지만, 그냥 3000으로 입력했습니다. 나머지 설정값은 그대로 두었습니다.
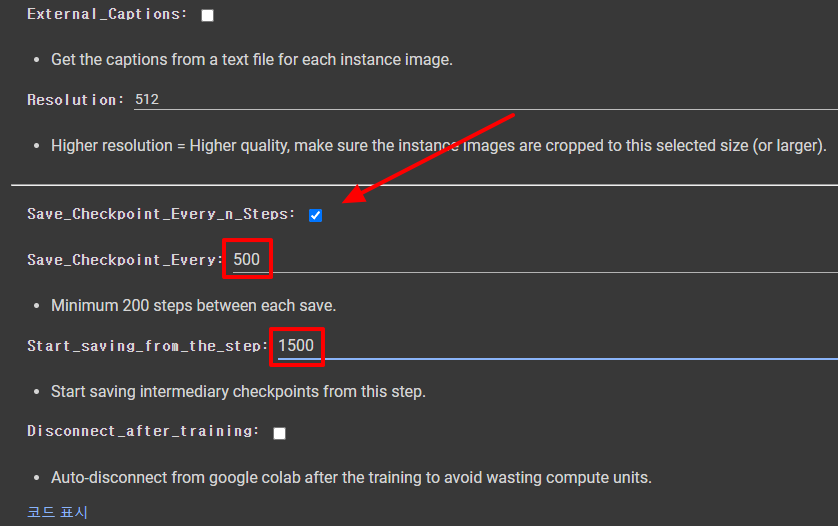
다음은 1500 스텝, 2000스텝, 2500스텝, 3000스텝에서 결과를 저장하도록 설정했습니다. 과적합이 발생할 경우 이전 버전을 사용할 수 있어서 입니다.
이렇게 설정해 두고 텍스트 인코더 학습이 시작됩니다. 잠시 기다리면 아래와 같이 TRAINING이라는 배너와 진행상황이 표시됩니다.
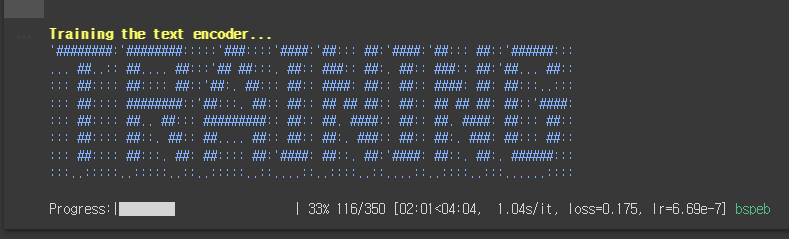
텍스트 인코더 학습이 완료되면 비슷한 형태로 UNet 학습이 진행됩니다. 진행속도는 텍스트 인코더에 비해 5배 이상 느린 것 같네요. 아래 그림에서 여러번 저장되고 다시 재게되는 것은 1500, 2000 등에서 저장되도록 설정해뒀기 때문입니다.
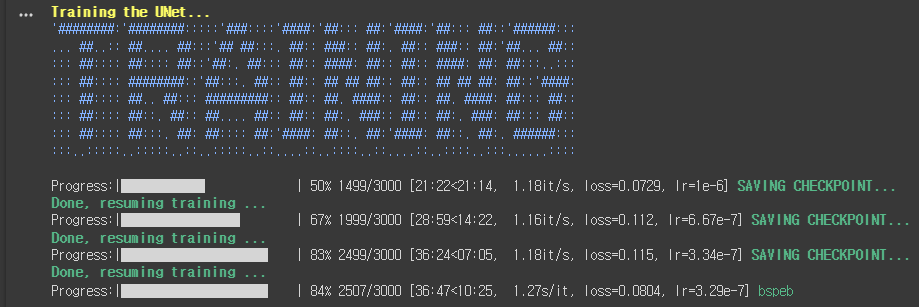
약 1시간 정도 걸려서 학습이 완료된 것 같네요. 학습이 완료되면, 구글 드라이브에 Fast-DreamBooth라는 폴더가 생기고, 그 안에 있는 세션명 폴더 속에 ckpt 파일이 생성됩니다. 아래는 생성결과입니다. 총 5개가 생성되었네요. 아마 bsParkEB_step_3000.ckpt와 bsParkEBckpt 파일은 동일하지 않을까... 싶습니다.

그 아래에는 이렇게 생성된 DreamBooth 체크포인트 파일을 사용해 시험한다던지 HuggingFace에 모델을 올리는 등의 작업이 가능하지만, 저는 생략했습니다.
=====
아래는 이렇게 생성된 체크포인트 파일(bsParkEB.ckpt)을 사용해서 생성한 결과중 몇개 입니다.
 |
 |
 |
 |
 |
 |
박은비 배우님의 특징이 전혀 없다고는 말하지 못하겠지만, 제가 보기에는 전혀 닮지 않은 것 같습니다. 특히나 광대뼈가 강조되어서 더 이상한 사진도 많이 나왔거든요.
그래서 조코딩님의 유튜브를 따라, X/Y/X plot 스크립트로 여러가지 샘플링 방식(sampler)와 CFG 척도를 바꿔가며 괜찮은 게 있는지 확인해 봤습니다. 다만 아래위로 길게 나오도록 x/y 축만 바꿔서 실행시켰습니다. (비슷한 이미지가 나오도록 시드 값을 고정시켰습니다)
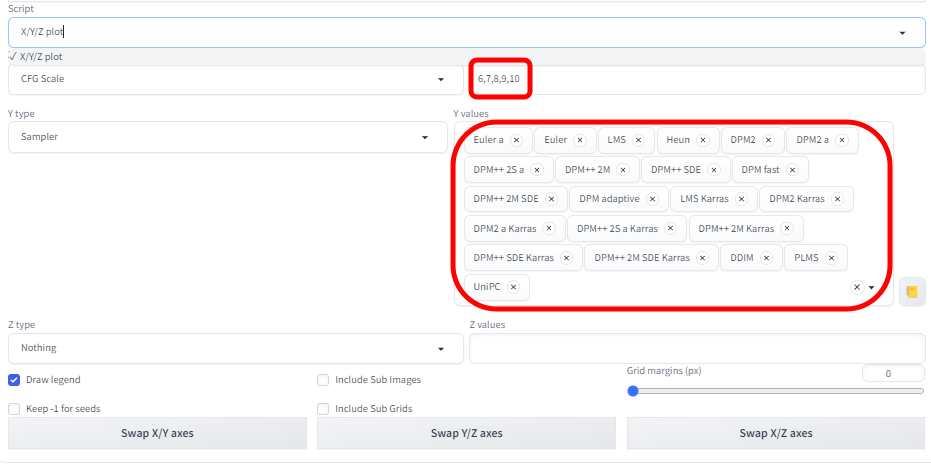
아래가 그 결과입니다.

몇가지는 과적합이 나서 깨졌지만, 대부분 얼굴이 정상적으로 나오긴합니다. 문제는 얼굴이 닮은 것 같지 않아서... ㅠㅠ 그나마 맨 아래에 있는 UniPC가 좀 나은 것 같아 다시 몇가지 생성해 봤습니다. 아래는 설정환경입니다.
모델: bsParkEB.ckpt
프롬프트: a photo of a bspeb, a beautiful woman sitting at a table, brown eyes, looking at me, atmospheric cafe
부정적 프롬프트: ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur, distorted face, b&w, nude, nsfw, EasyNegative
샘플러: UniPC
CFG: 7
아래는 생성된 이미지입니다. 동일한 모델12개 중에서 2개를 선정했는데... 박은비 배우님을 닮은 것 같지는 않네요.ㅠㅠ
 |
 |
===
제가 일반적인 프로세스와 다르게 설정한 부분이 있습니다. 먼저 대부분 기본 v1.5 체크포인트파일(v1-5-pruned-emaonly) 대신 ChilloutMix를 베이스로 사용했다는 점이고(입력한 사진보다 눈이 크게 나온게 그 영향이 아닐까... 싶네요), 학습 단계수를 좀더 올릴 걸 하는 생각도 조금 들더군요. 그리고... 중간에 잠깐 말씀 드렸지만, 이 노트북의 경우 Class 를 별도로 지정할 수 없는 부분도 마음에 걸리고요.
구글 Colab을 한번 더 돌리면 사용제한에 걸릴 것 같아 마음대로 테스트해보지도 못하네요. 12GB 짜리 그래픽카드로 교체할 형편도 안되고요. ㅠㅠ
암튼 완벽하게 테스트해보지 못해서 마음에 걸리지만, 이번엔 이정도로 멈춰야겠네요~
민, 푸른하늘
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- Stable Diffusion - 모델에 대한 모든 것
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기