LCM-LoRA를 사용하면 스테이블 디퓨전 모델을 사용한 이미지 생성 속도를 아주 빠르게 할 수 있습니다. 일반적인 경우 KSampler에서 20 단계 ~ 25 단계정도를 돌려야만 깔끔한 이미지를 생성할 수 있음에 비해, LCM-LoRA를 사용할 경우, 4-6 단계 정도면 비슷한 수준의 이미지를 생성할 수 있습니다. 즉 5배 정도 빨리 이미지를 생성할 수 있다는 것입니다. 또한 LCD-LoRA의 경우 SDXL에도 적용할 수 있어 유용할 것 같습니다.
특히 아래와 같은 AnimateDiff 비디오를 생성할 경우, 여러개의 프레임을 생성해야 하므로 속도가 매우 중요하다고 할 수 있습니다.

아래는 이 글의 목차입니다.
- LCM-LoRA란 무엇인가?
- LCM-LoRA의 작동 원리
- LCM-LoRA 다운로드
- AUTOMATIC1111 에서 LCM-LoRA 사용하는 방법
- ComfyUI LCM-LoRA SDXL txt2img 워크플로
- ComfyUI LCM-LoRA 를 사용한 animateDiff
LCM-LoRA란 무엇인가?
LCM-LoRA가 무엇인지 알아보려면 먼저 CM(Consistency Model, 일관성 모델)에 대해 알아야 합니다. CM은 한 단계만에 이미지를 생성할 수 있도록 훈련된 새로운 종류의 디퓨전 모델입니다. 이 모델은 OpenAI에 계신 Yang Song 등이 개발한 것으로, 자세한 내용은 Consistency Model 논문을 보시면 됩니다.
LCM(Latent Consistency Model, 잠재 일관성 모델)은 이 아이디어를 잠재 공간(latent space)에서 잡음 제거를 통해 이미지를 생성하는 Stable Diffusion 같은 잠재 디퓨전 모델에 적용한 것입니다.
일반적으로는, 모든 각각의 체크포인트 모델에 대해 새로운 LCM을 학습시켜야 합니다. 이렇게 되면 매우 불편하겠죠. LCM-LoRA는 일관성 모델 방법론을 사용하여 Stable Diffusion 기본 모델(v1.5, SDXL 등)에 대해 학습시킨 LoRA 모델입니다. LCM-LoRA는 모든 체크포인트 파일에 사용할 수 있으며, 4 단계 정도에 이미지를 빠르게 생성할 수 있습니다.
LCM-LoRA의 작동 원리
LCM-LoRA의 작동 원리를 알기 위해서는 먼저 CM(Consistency Model, 일관성 모델)을 이해해야 합니다.
Consistency Model(일관성 모델)
Consistency Model은 AI 이미지를 1 단계만에 생성하도록 훈련된 디퓨전 모델입니다. Consistenty Sutdent 모델은 SDXL과 같은 교사 모델(teacher model)을 사용하여 훈련된, 보다 효율적인 학생 모델(student model)입니다. 학생 모델은 교사 모델과 동일한 이미지를 생성하도록 학습되지만 한 번에 생성하도록 학습됩니다. 즉, 일관성 모델은 교사 모델의 더 빠른 버전입니다.
또한 교사 모델을 사용하지 않고 처음부터 Consistency Model 모델을 직접 학습시킬 수도 있습니다. 향후에는 표준 교사 모델이 없는 새로운 LCM 모델이 나올 수도 있을 것으로 예상됩니다.

Consistency Model 의 기본 개념은 최종 AI 이미지와 잡음 제거 단계 사이의 매핑 관계를 찾는 것입니다. 예를 들어 디퓨전 모델이 50단계로 AI 이미지를 생성하도록 학습된 경우, Consistency Model은 0, 1, 2, 3... 단계의 중간 노이즈 이미지를 최종 50단계에 매핑시킵니다.
일관성 모델(Consistency Model)이라고 불리는 이유는, 매핑에 따른 출력이 일관성이 있다는 점을 활용하기 때문입니다. 즉, 항상 한 단계만에 최종 이미지에 매핑됩니다. 결국, 이미지의 노이즈가 아무리 심해도 매핑 함수의 출력은 항상 동일합니다.
하지만, 실제 사례에서는 단일 단계로 생성한 이미지의 품질은 그다지 좋지 않습니다. 그래서 보통 몇 단계를 거쳐 생성하는 방식을 사용합니다.
일관성 모델은 지식 농축 방식(knowledge distillation method)입니다: 기존 (교사) 모델에서 정보를 추출하고 재배열하여 더 효율적으로 만듭니다.
참고 : 지식 농축(knowledge distillation)
머신 러닝에서 지식 농축(knowlege distillation) 또는 모델 농축(model distillation)이란, 큰 모델에서 작은 모델로 지식을 옮기는 과정을 말합니다. 대규모 모델(예: 매우 심층적인 신경망(deep neural network) 또는 여러 모델을 결합한 것(ensenble))은 소규모 모델보다 지식 용량이 더 크지만, 이 용량 전체를 완전히 활용하지 못할 수도 있습니다. 지식 용량을 일부만 사용하는 경우, 모델을 평가하는 데는 계산 비용이 많이 들 수 있습니다. 지식 농축을 거치면 유효성을 잃지 않으면서 지식을 큰 모델에서 작은 모델로 이전할 수 있습니다. 작은 모델은 평가 비용이 적게 들기 때문에 모바일 장치와 같이 성능이 낮은 하드웨어에서 사용할 수 있습니다. (en.wikipedia.org 에서 번역함)
Consistency Model은 Stable Diffusion의 속도를 획기적으로 높일 수 있다고 알려진 Progressive Distillation(점진적 농축) 보다 우수하며, 더 높은 품질의 이미지를 생성합니다.
Latency Consistency Model(LCM)
Latency Consistency Model(LCM, 잠재 일관성 모델)은 스테이블 디퓨전과 같은 Latent Diffusion에 적용된 Consistency Model입니다. Simian Luo 등이 연구한 결과로, 논문은 Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference(적은 단계의 추론으로 고해상도 이미지 합성)입니다. 원래의 Consistency Model은 픽셀 공간에서 작동하는데, 이를 잠재 공간(Latent space)에서 구현한 것입니다. 이것이 유일한 차이점입니다.
LCM-LoRA
이제서야 LCM-LoRA에 대해 설명드리게 되었네요. LCM-LoRA는 체크포인트 모델을 학습시킨 것이 아니라, LoRA 모델을 학습시킨 것입니다.

LCM-LoRA는 원래의 LCM에 비해 다음과 같은 장점이 있습니다.
- 이식성: LCM-LoRA는 모든 스테이블 디퓨전 체크포인트 모델에 적용할 수 있습니다. Stable Diffusion v1.5 및 SDXL 모델용 LCM-LoRA이 별도로 존재하기 떄문입니다. 기본적으로 LoRA를 적용하면 모델 속도가 빨라집니다.
- 학습 속도 향상: LoRA는 학습시킬 가중치의 수가 더 적습니다. 따라서 더 빠르고 효율적으로 학습시킬 수 있습니다.
LCM-LoRA 에 관한 논문은 여기에 있습니다. 참고하세요.
LCM-LoRA를 사용할 때의 샘플링 방법
LCM-LoRA 는 1단계에 최종 이미지를 추론하도록 학습되었습니다. 즉, 1 단계가 지나면 최종 이미지가 생성된다는 것입니다. 하지만, 이렇게 하면 이미지 품질이 그다지 좋지 않습니다.
아래는 LCM_LORA.md 에서 가져온 샘플입니다. 보시는 것처럼 1단계만으로 추론했을 경우에는 품질이 별로지만, 3,4 단계만 지나도 괜찮은 품질의 이미지가 생성됨을 알 수 있습니다.

일반적인 LCM 샘플링 방법은 아래와 같습니다.
- 잠재 이미지(latent image)에서 잡음을 제거(Denoising)한다.
- (잡음 스케줄에 따라) 약간의 잡음을 추가한다.
- 최종 샘플링 단계에 도달할 때까지 1-2를 반복한다.
LCM-LoRA 다운로드
LCM-LoRA 모델은 아래에서 받을 수 있습니다.
- SDXL 용 LCM-LoRA (다운로드 링크) -> 다운로드 후 lcm-lora-sdxl.safetensors 로 이름을 변경합니다.
- SD1.5 용 LCM-LoRA (다운로드 링크) -> 다운로드후 lcm-lora-sd1-5.safetensors로 이름을 변경합니다.
다운로드 받은 파일은 ComfyUI/models/lora 에 넣으시면 됩니다. AUTOMATIC11111과 공유해서 사용하는 경우에는 이 글을 읽어보시기 바랍니다.
ComfyUI 화면을 refresh(F5) 시키면 다운로드 받은 파일이 적용됩니다.
AUTOMATIC1111 에서 LCM-LoRA 사용하는 방법
현재 AUTOMATIC1111은 LCM-LoRA 를 공식적으로 지원하지 않습니다. 하지만, 약간 제한적이기는 하지만, LCM-LoRA를 이용한 속도 향상을 이용할 수 있습니다.
Stable Diffusion v1.5 모델
여기에 들어가서 SD1.5용 LCM-LoRA를 다운로드 받은 후, stable-diffusion-webui\models\Lora에 넣어줍니다. 그 다음 이름을 lcm-lora-sd1-5.safetensors로 변경해 줍니다.
다음은 설정 방법입니다.
모델: DreamShaper (v1.5 모델이면 어떤 것이나 사용가능합니다)
프롬프트 : a very cool car <lora:lcm-lora-sd1-5:1>
샘플러: Euler
CFG 척도: 1.2 (1~2 정도로 설정합니다)
샘플링 단계 : 4
아래가 결과입니다. 4단계만에 생성했음에도 (거의 [Generate] 버튼을 누르자 마자 생성되는 느낌입니다^^) 상당한 퀄러티의 이미지가 생성됩니다.
 |
 |
 |
 |
참고로 아래는 lcm-lora-sd1-5 LoRA를 제거하고 생성한 결과입니다. 뭔가 만들어지기 시작하는 느낌이네요.
 |
 |
 |
 |
SDXL용 LCM-LoRA
2023년 11월 24일 현재 AUTOMATIC1111에서는 LCM-LoRA를 공식적으로 지원하지 않습니다. sd1.5와 동일한 방식으로 시험해 보실 수는 있지만, 결과물은 그다지 좋지 않습니다. 공식적으로 지원할 때까지 기다리는 게 좋겠다고 생각됩니다.
 |
 |
그래도 사용하고 싶으시다면, LCM 샘플러를 사용하면 가능하다고 합니다. 그런데, LCM 샘플러는 기본 AUTOMATIC1111에는 존재하지 않고, AnimateDiff 확장을 설치하면 추가됩니다. 이미 설치해 두셨을 경우에는 최신버전으로 업데이트 하셔야 합니다.
다음과 같이 설정합니다.
모델: dreamShaperXL_10
프롬프트: a very cool car <lora:lcm-lora-sdxl:1>
샘플링 방법 : LCM
이미지 크기 : 1024x1024
CFG 척도 : 1.2(1~2로 설정해야 합니다.)
샘플링 단계 : 4
아래가 결과입니다. 되는 것 같기는 한데... 별로 추천하고 싶지 않네요. 3070을 사용하는데 4장을 생성하는데 1분 15초가 걸렸네요. 품질도 별로고요.
 |
 |
 |
 |
ComfyUI LCM-LoRA SDXL txt2img 워크플로
스테이블 디퓨전 웹UI 중 하나인 ComfyUI를 사용해 LCM-LoRA 워크플로를 만들어 보겠습니다. ComfyUI 설치방법 및 기초적인 내용은 여기와 여기를 보시면 됩니다.
1. 최종 워크플로
아래 그림이 SDXL 용 LCM-LoRA 를 사용하기 위한 최종 위크플로입니다. (Refiner는 사용하지 않는 기본 워크플로입니다) 아래에는 이 워크플로를 만들기 위한 방법을 설명하는데, 관심이 없으시면 그냥 이 워크플로를 사용하시면 됩니다.
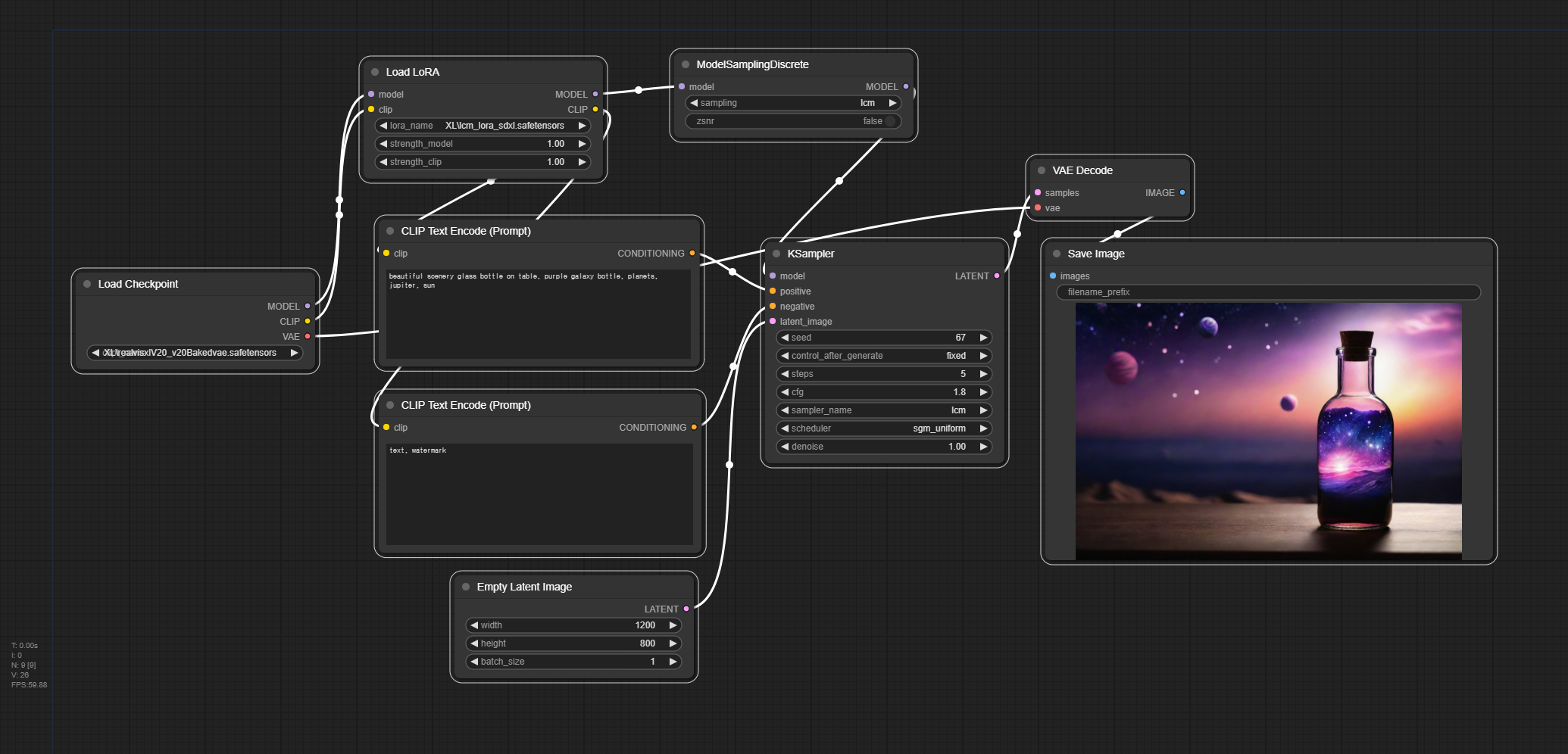
2. 기본 워크플로 불러오기
ComfyUI 오른쪽에 있는 메뉴에서 [Load Default]를 누르면 아래와 같은 기본 워크플로가 나타납니다.

3. SDXL 체크포인트 파일 불러오기
맨 왼쪽에 있는 [Load Checkpoint] 노드에는 SDXL 체크포인트파일을 불러옵니다. 여기에서는 realvisxlV20을 사용했지만, 기본 SDXL 파일이나 기타 SDXL 체크포인트 파일을 불러와도 무방합니다. 저는 SDXL용 파일만 따로 XL이라는 폴더에 넣어두었기 때문에 파일명이 저렇게 되어있으니 참고하세요.

4. LoRA 파일 불러오기
먼저 SDXL용 LCM-LoRA를 여기에서 다운로드 받은 후, lcm-lora-sdxl.safetensors 라고 이름을 변경하고 ComfyUI\models\loras에 넣어줍니다. (AUTOMATIC1111과 파일을 공유할 경우 여기를 읽어보세요)
ComfyUI 빈 캔버스를 우클릭하여 [Load LoRA] 노드를 추가합니다.

그리고 lcm-lora-sdxl 파일을 선택합니다. (파일이 안보이면 ComfyUI 화면을 Refresh(F5)하면 됩니다.)

[Load LoRA] 의 model 과 clip 입력 슬롯은, [Load Checkpoint] 의 출력 슬롯인 MODEL 과 CLIP에 연결해 줍니다.
그리고, [Load LoRA] 의 CLIP 출력 슬롯은 [CLIP Text Encode]의 clip 입력 슬롯에 연결해 주면 됩니다.
5. [ModelSamplingDiscrete] 노드 추가하기
ModelSamplingDiscrete 노드를 추가합니다. 위처럼 우클릭 메뉴에서 찾아갈 수도 있지만, 캔버스를 더블클릭한 후 나타나는 창에 ModelSamplin...라고 입력하면 쉽게 찾을 수 있습니다.

ComfyUI LCM 예제 사이트에는 ModelSamplingDiscrete 노드에 lcm을 샘플링 옵션으로 설정하면 품질이 약간 더 좋아진다고 나옵니다(정확히 어떤 역할을 하는 노드인지는 모르겠네요).
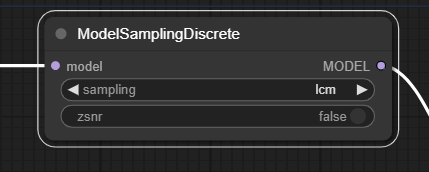
[ModelSamplingDiscrete] 노드의 입력 슬롯 model 에는 [Load LoRA] 노드의 MODEL에 연결해주고, [ModelSamplingDiscrete] 노드의 출력 슬롯 MODEL은 [KSampler] 노드의 model에 연결해주면 됩니다.
6. [KSampler] 노드 설정 변경

[KSampler] 노드에서 다음의 값을 수정해줍니다.
- steps - 일반적으로 20~25 정도로 설정하지만, LCM에서는 4~8 단계 정도면 충분합니다.
- CFG - 일반적으로 7을 사용하지만, LCM에서는 2 이하로 낮은 밗으로 설정합니다.
- Sampler-name - lcm 으로 설정합니다.
- Scheduler - 스케줄러도 sgm_uniform으로 설정해야 한답니다.
7. 이미지 생성
이제 [Queue Prompt]를 누르면 이미지가 생성됩니다. 무엇보다 매우 빠르게 생성됩니다. 20~25 번 반복해서 잡음 제거하는 것을 5번으로 줄였으니까요.

아래는 ComfyUI 블로그에 올라왔던 글에 있는 표로서 하드웨어의 종류에 따라 다르지만, 1/10 ~ 1/4 정도로 실행시간이 줄어들었음을 알 수 있습니다.

Prompt Styler와 Aspect Ratio 노드 추가버전
아래는 제가 좋아하는 두가지 커스톰 노드를 추가한 버전입니다. 참고하세요.

참고
보시는 것처럼, 이 워크플로에서는 Refiner 모델을 사용하지 않았기 때문에, 스테이블 디퓨전 v1.5 커스텀 모델도 사용할 수 있습니다. 다만, [Load Checkpoint] 노드에서 SD1.5용 모델을 선택하고, [Load LoRA] 노드에서는 v1.5용 LCM-LoRA 를 선택해 주면 됩니다. 이미지 크기도 768x512 로 줄여주시고요.
ComfyUI LCM-LoRA 를 사용한 animateDiff
실제 테스트해보셨다면 LCM-LoRA는 이미지 생성속도가 엄청 빠르다는 것을 아셨을 겁니다. 이걸 어디에 써먹을까요? 물론 그냥 이미지를 대량으로 생성하는데도 유용하지만, 비디오를 생성할 때 매우 유용합니다. 비디오는 여러개의 프레임을 생성해야 하니 시간이 많이 걸리는데, LCM-LoRA를 이용하면 빠르게 생성할 수 있으니까요. 여기에서는 예전에 Animatediff 를 사용한 Vid2Vid - ComfyUI라는 글에서 소개시켜드린 방법을 LCM-LoRA를 사용하도록 개선해 보겠습니다.
1 단계: 워크플로 불러오기
아래 그림을 다운로드받은 후, ComfyUI 화면에 Drag&Drop하면 워크플로가 불러들여집니다. 필요하다면 ComfyUI를 최신으로 업데이트 시키거나, 설치되지 않은 커스톰 노드를 추가하거나, 커스톰 노드들을 최신버전으로 업데이트 시켜야 합니다.
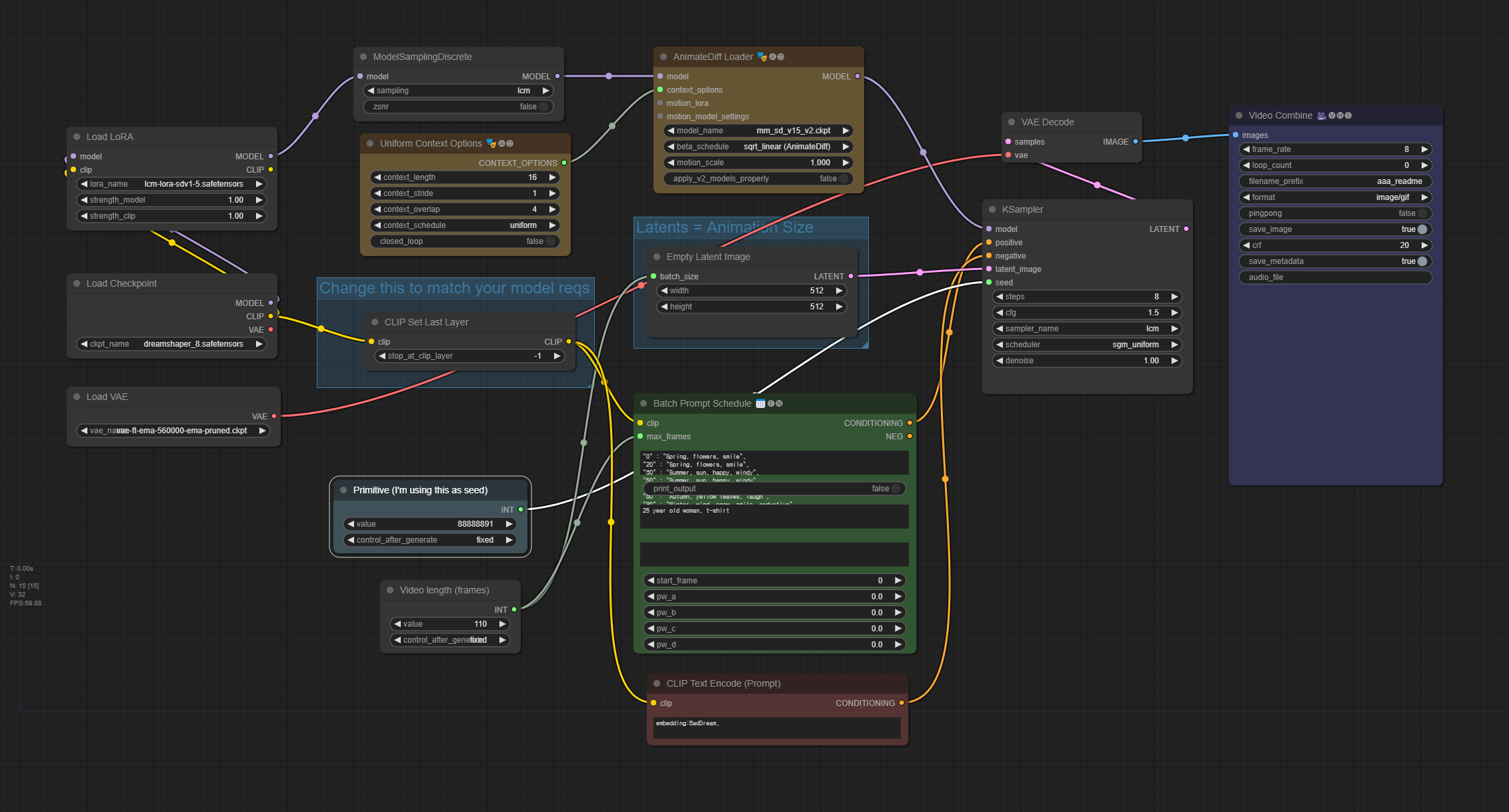
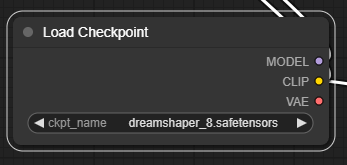
2단계: 체크포인트 모델 선택
DreamShpaer 8 모델을 다운로드 받아, ComfyUI\models\checkpoints 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우엔 여기를 참고하세요). 다 받은 후에는 화면을 Refresh하고 [Load Checkpoint] 노드에서 dreamshaper_8 모델을 선택해 줍니다.
3단계: VAE 선택
ema-560000 VAE 파일을 다운로드 받아, ComfyUI\models\checkpoints 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우엔 여기를 참고하세요).
다 받은 후에는 브라우저를 새로고침(F5)하고 [Load VAE] 노드에서 방금 다운로드 받은 파일을 선택해 줍니다.

4단계: LCM-LoRA 선택
SD1.5용 LCM-LoRA 파일을 다운로드 받고, lcm-lora-sd1-5.safetensors로 이름을 바꾼후, ComfyUI\models\loras 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우엔 여기를 참고하세요).
화면을 새로고침(F5)하고, [Load LoRA] 노드에서 방금 다운로드 받은 lcm-lora-sd1-5.safetensors를 선택합니다.

5단계: AnimateDiff 모션 모듈 선택
Animate v1.5 v2 모션 모듈을 다운로드 받아, ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\models 폴더에 넣어줍니다.
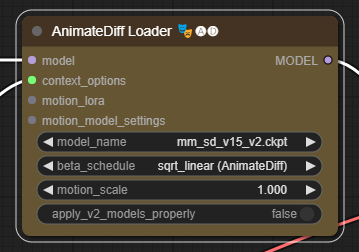
화면을 새로고침(F5)한 뒤, [AnimateDiff Loader] 노드에서 mm_sd_v15_v2.ckpt 파일을 선택합니다.
6단계: negative embedding 다운로드
이 워크플로에서는 부정적 프롬프트에 BadDream 이라는 임베딩을 사용합니다. 이 임베딩은 DreamShaper 모델을 위해 학습된 부정적 임베딩입니다. 이 임베딩을 ComfyUI\models\embeddings 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우엔 여기를 참고하세요).

7단계: 비디오 생성
이제 [Queue Prompt] 버튼을 누르면 비디오가 생성됩니다. [KSmapler] 노드 및 명령창(Command window)에서 진행상황이 표시되는데, 생성이 완료되면 [Video Combine] 노드에서 결과물이 나타납니다. 아래는 제가 씨드 번호만 바꿔서 생성한 결과입니다. 제 컴퓨터가 3070을 사용하는데, 약 2분 정도에 생성이 완료되었습니다. 현재 잡음 제거 샘플링을 8단계 수행하는데, 이를 줄이면 더 빨리 생성되겠죠.

이상입니다.
이 글은 https://stable-diffusion-art.com/lcm-lora/를 번역하면서 일부 수정해 작성한 글입니다. 참고: https://github.com/huggingface/blog/blob/main/lcm_lora.md 이 글도 참고하세요~
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기