Stable Video 3D(SD3D)는 이미지를 단 한장 입력받아서, 3차원으로 회전하는 동영상을 생성해주는 AI 모델입니다. Stability AI에서는 이 모델을 비 상업적 목적에 한해 공개했습니다.
아래는 입력 이미지와 이를 이용해 생성헌 3차원 회전 이미지입니다.
 |
 |
이 글의 목차는 아래와 같습니다.
소프트웨어
이 글에서는 ComfyUI를 사용합니다. ComfyUI 에 대해 잘 모르신다면 설치 및 사용법 기초와 투토리얼을 읽어보시기 바랍니다.
따라하기
1단계: SV3D 워크플로 불러오기
아래의 json 파일 혹은 이미지 파일을 다운로드 받은 후, ComfyUI 화면에 Drag&Drop하면 워크플로가 불러들여집니다.
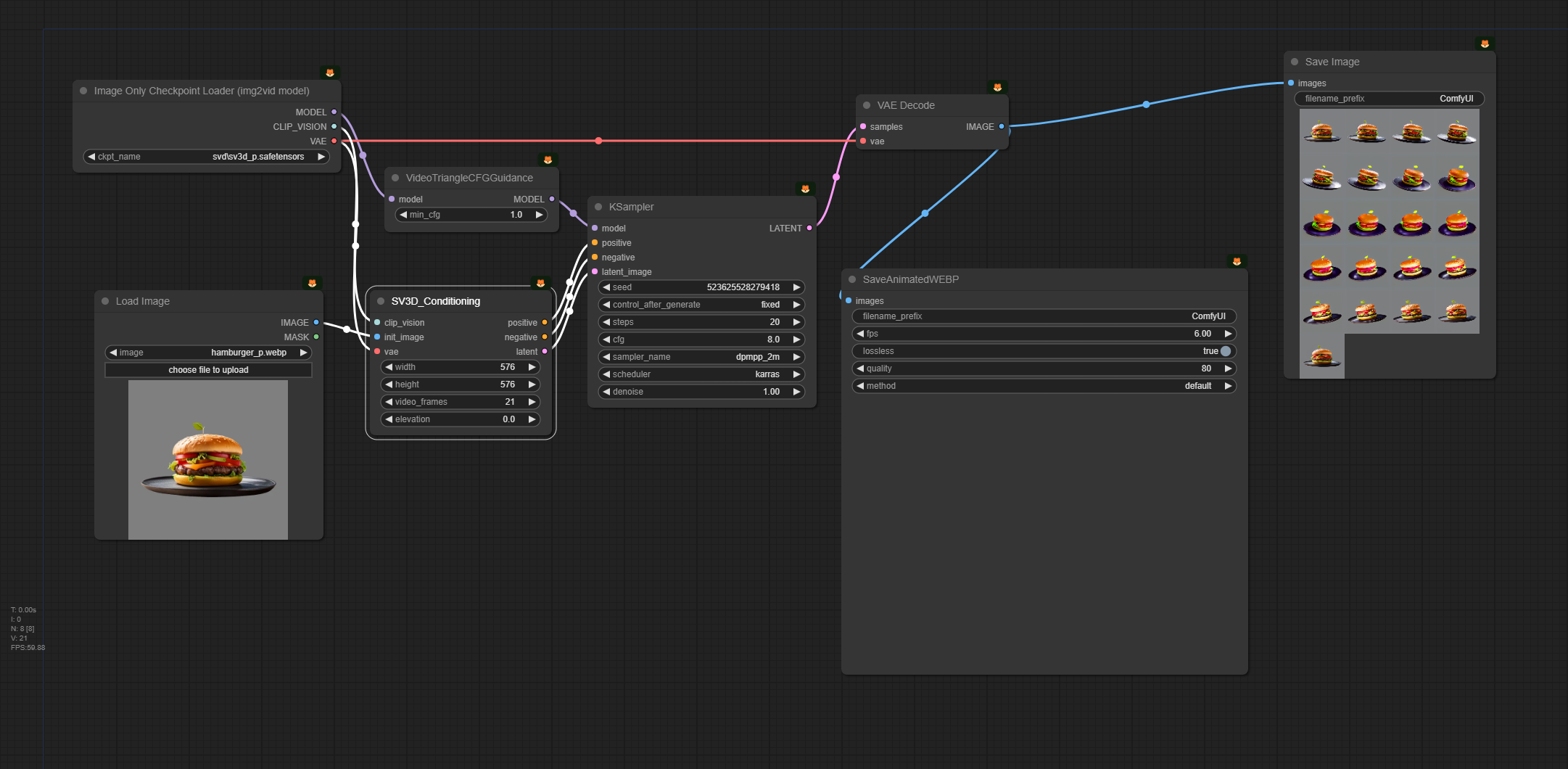
이 워크플로는 대부분 그냥 그대로 사용할 수 있지만, 때때로 오류가 발생할 수 있습니다. 그러한 경우, 다음과 같은 작업이 필요할 수 있습니다.
- 처음 사용할 때 -ComfyUI Manager 를 설치해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 -빠진 커스톰 노드를 가져오기해야 합니다.
- ComfyUI 전체 업데이트 - ComfyUI를 최신버전으로 업데이트해야 합니다.
2단계: 모델 다운로드

먼저 HuggingFace 의 SV3D 모델 페이지에 들어갑니다. 우측과 같은 화면을 볼 수 있는데, 여기에서 [I agree]를 체크한 후, [Agree and access repository] 버튼을 눌러서 사용권 동의를 해야 SV3D 모델을 다운로드 받을 수 있습니다.
그 다음 SV3D-p 모델을 다운로드 받아 ComfyUI\models\checkpoints 폴더에 넣어줍니다. (AUTOMATIC1111과 모델을 공유할 경우 여기를 읽어보세요)
3단계: 워크플로 실행
[Load Image] 노드에서 배경이 없는 이미지를 불러옵니다. 없으시면 아래에 있는 이미지를 이용하셔도 됩니다. 배경이 없는 이미지를 생성하고 싶을 땐 이 글을 읽어보세요.
 |
 |
 |
 |
 |
 |
이제 [Queue Prompt] 버튼을 누르면 워크플로가 실행되고 아래와 같이 3차원 회전 이미지를 얻을 수 있습니다.

이미지 조정

우측의 [SV3D_Conditioning] 노드의 매개변수를 조정하여 생성되는 이미지를 약간 변경할 수 있습니다.
- 이미지 크기 (width/height)
- 프레임수(video_frame) - 높은 값일 수록 부드러운 이미지가 생성됩니다.
- 촬영 고도 각(elevation) - 수평방향을 기준으로 높은 방향에서 촬영한 이미지를 생성합니다. 아래는 각각 0도 5도, 10으로 두고 생성한 예입니다.
 |
 |
 |
SV3D의 원리
SV3D의 자세한 원리는 SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion에 기술되어 있습니다. 아래는 간략히 정리한 내용입니다.
SV3D 모델
SV3D 모델을 스테이블 비디오 디퓨전(SVD, Stable Video Diffusion)모델에 기반으로 한 모델로서, 어떤 사물의 여러 방향에서 바라보는 모습을 일관성있게 생성하는 모델입니다. SV3D는 입력된 이미지의 뒤쪽 모습과 같은 새로운 뷰를 생성하는 기능을 활용합니다.
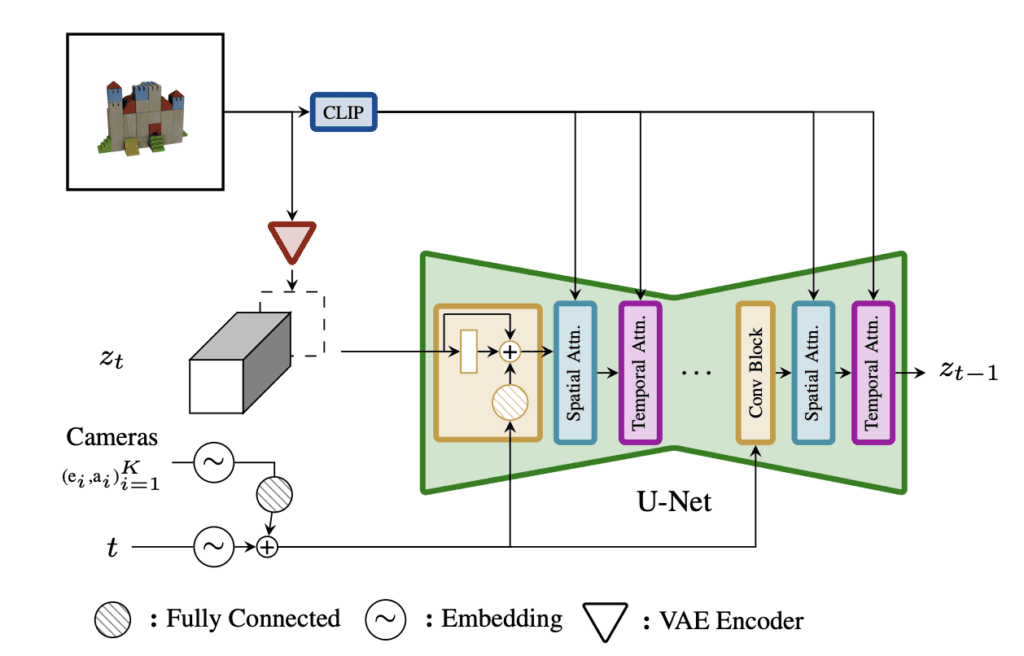
이 모델은 입력된 이미지에 기반하여 이미지에 나타난 객체의 회전 모습을 담은 비디오를 생성합니다. 입력 이미지는 SVD의 VAE를 사용하여 잠상으로 변환됩니다.
잡음 예측기(U-Net)는 다음과 같은 조견부여를 사용합니다.
- CLIP으로 처리된 입력 이미지
- 카메라의 촬영 각도
이를 통해 여타 스테이블 디퓨전 모델과 비슷한 방법으로 일련의 이미지가 생성됩니다.
학습데이터
이 모델은 Objaverse 데이터셋에 있는 3D 객체 합성 이미지를 사용해 학습되었다고 합니다.
사전 학습 모델(Pretrained models)
모든 사전 학습된 모델은 SVD 모델에서 미세 조정됩니다. 세 가지 모델이 학습되었습니다.
- SVD-u(unconditioned): 입력 이미지로만 조건부여되고 카메라 각도는 조건부여되지 않습니다.
- SVD-c(unconditioned): 입력 이미지와 카메라 각도로 모두 조건부여됩니다.
- SVD-p(progressive): 먼저 카메라 각도로 조건 없이 학습한 다음, 카메라 포즈의 동적 궤도를 학습합니다.
이 중에서 SVD-p가 가장 성능이 좋은 모델입니다. 따라서 하나만 다운로드하려는 경우 p 모델을 다운로드하세요.
이상입니다. 이 글은 https://stable-diffusion-art.com/stable-video-3d/ 을 번역하면서 몇가지 수정하여 작성하였습니다.
민, 푸른하늘
===
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기