얼마전, Stable Diffusion을 오픈소스로 공개한 Stability.ai에서 텍스트 입력만으로 짧은 비디오(움짤)를 생성할 수 있는 Stable Video Diffusion을 공개했다는 소식을 알려드렸습니다(비디오 생성 스테이블 디퓨전 참조). 오늘은 이에 대한 좀 더 자세한 소식이 있어 소개합니다. 아래는 이 글에서 다루는 내용입니다.
ComfyUI에서 img2vid 사용하기
비디오 스테이블 디퓨전(SVD) 이란?
Stable Video Diffusion(SVD, 비디오 생성용 스테이블 디퓨전)은 Stability AI에서 공개한 기반 비디오 모델(foundational video model)입니다. 스테이블 디퓨전과 마찬가지로 코드 및 모델 가중치가 공개된 오픈소스 모델입니다.
용도
SVD는 image-to-video(img2vid) 모델입니다. 즉, 이미지를 하나 제공하면(1번 프레임이 됩니다) 모델이 짧은 비디오 클립을 생성합니다. 아래는 입력한 이미지입니다.

아래는 이 이미지를 기반으로 생성된 SVD 비디오입니다.
모델과 학습
모델과 학습은 Andreas 등이 작성한 논문 "비디오 스테이블 디퓨전: 대형 데이터셋에 대한 잠재 비디오모델 확장(Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Dataset)"(2003)에 설명되어 있습니다.
SVD 모델은 3단계의 학습을 거쳤습니다.
- image 모델을 학습합니다.
- 이미지 모델을 video 모델로 학장하여, 대형 비디오 데이터셋에 대해 사전 학습합니다.
- 비디오 모델을 소형 고품질 비디오 데이터셋에 대해 미세조정합니다.
이미지 모델은 Stable Diffusion 2.1 모델입니다. SDXL 모델 이전에 나온 거의 사용되지 않은 모델이죠. 여기에서 사전 학습된 이미지 모델이 비디오 모델의 백본을 형성합니다.
비디오 모델을 생성하기 위해 U-Net 잡음 예측기에 시간 콘볼루션(temporal convolution)과 인지(attention) 레이어가 추가됩니다. 이제 잠재 텐서(latent tensor)는 이미지가 아닌 비디오를 표현하게 됩니다. 모든 프레임은 역 확산(reverse diffusion)을 사용해 동시에 잡음을 제거합니다. 시간 디퓨전 모델은 VideoLDM 모델과 동일합니다.
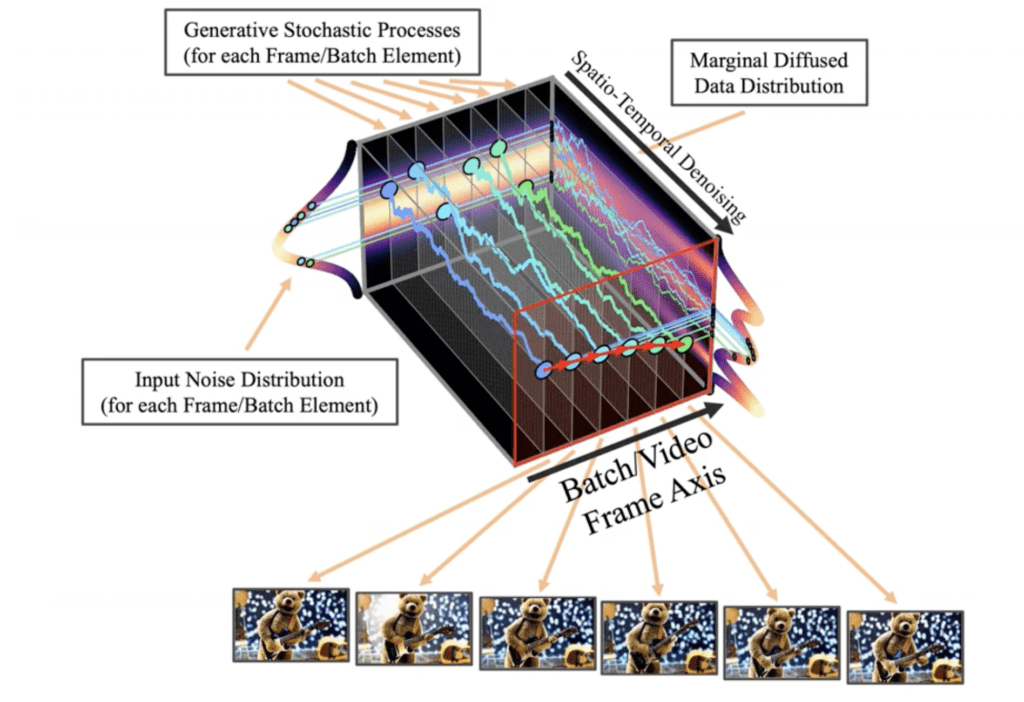
비디오 모델은 15억개의 파라미터를 보유하며, 대형 비디오 데이터셋을 사용해 학습됩니다. 마지막으로 이 비디오 모델을 작지만 고품질의 데이터셋을 사용해 미세조정(fine-tuned)하게 됩니다.
비디오 스테이블 디퓨전(SVD) 모델 가중치
SVD 모델의 가중치는 2가지 버전으로 공개되었습니다.
- SVD - 756 x 1024 해상도로 14 프레임을 생성하도록 학습된 모델
- SVD TX - 756 x 1024 해상도로 25 프레임을 생성하도록 학습된 모델
이 글에서는 SVD XT 모델을 중점적으로 다룰 예정입니다.
모델 파라미터
아래는 비디오 출력을 제어하는 중요한 파라미터들을 정리한 것입니다.
모션 버켓 id(Motion bucket id)
모션 버켓 id 는 비디오에서 얼마나 많이 움직일 것인지를 제어합니다. 높은 값을 주면 움직임이 많아집니다. 0~255 를 입력할 수 있습니다.
FPS
초당 프레임(fps: frame per second)는 모델이 생성할 프레임의 수를 제어합니다. 최적의 성능을 위해 5~30 정도로 입력하는 것이 좋습니다.
보정 수준(Augmentation level)
보정 수준은 초기 이미지에 추가되는 잡음량입니다. 초기 이미지를 더 많이 변경하거나 기본 크기에서 벗어난 동영상을 생성할 때 사용합니다.
ComfyUI로 비디오 스테이블 디퓨전 사용하기(txt2vid)
ComfyUI는 비디오 스테이블 디퓨전을 공식적으로 지원합니다. 발표된지 며칠 지나지 않았는데도 벌써 지원하다니 놀랍습니다. AUTOMATIC1111과 같은 경우 아마도 한참 걸리지 않을까 싶은데, 모듈식(노드)로 만들어져서 유연하다는 장점이 정말 잘 드러나네요. 아래의 워크플로는 text-to-video(txt2vid)와 image-to-video 를 모두 지원하는데, txt2vid를 여기에서 설명하고, img2vid는 다음 절에서 설명합니다.
txt2vid는 먼저 SDXL 모델을 사용하여 초기 이미지를 만든 뒤, SVD XT 모델을 사용하여 비디오클립을 생성하는 방식입니다.
ComfyUI에 대해서 알고싶으신 분은 ComfyUI 초보자 가이드와 설치 및 사용법 기초를 읽어보시기 바랍니다.
1 단계: txt2vid 워크플로 불러오기
아래 그림이나 json 파일을 다운로드 받은 후, ComfyUI 캔버스에 Drag&Drop하면 워크플로를 사용할 수 있습니다.

2단계: ComfyUI 업데이트
ComfyUI 업데이트, 커스톰 노드 업데이트 및 외부에서 가져온 워크플로 사용하기를 참고하여 최신버전으로 업그레이드 합니다. 이 작업을 위해서는 먼저 최신 버전의 ComfyUI Manager를 설치해야 합니다.
3단계: 모델 다운로드
SVD XT 모델을 다운로드 받아서 ComfyUI\models\checkpoints 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우 여기를 읽어보세요). 다운로드가 끝나면 ComfyUI 화면을 새로 고침하고 [Image Only Checkpoint Loader] 노드에서 svd_xt.safetensors 를 선택합니다.

이 워크플로는 JuggernautXL 모델을 사용합니다. 없다면 여기에서 다운로드 받아서 ComfyUI\models\checkpoints 폴더에 넣어줍니다(AUTOMATIC1111과 모델을 공유할 경우 여기를 읽어보세요). 마찬가지로 화면을 새로고침(F5)한뒤 [Load Checkpoint] 노드에서 SDXL 모델을 선택합니다.

4단계: 생성
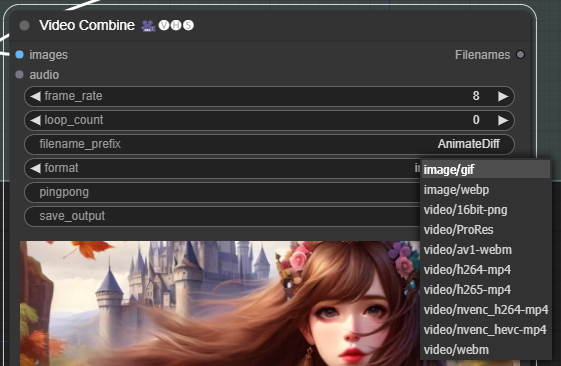
이제 메뉴에서 [Queue Prompt]를 선택하면 워크플로가 실행되고, 비디오가 생성됩니다. 이때 [Video Combine]노드에서 format을 바꿔주시면 gif, webp등 움짤도 생성할 수 있고, mp4 비디오도 생성할 수 있습니다.
아래는 전반부 (txt2img)에서 생성된 이미지입니다.
프롬프트: very beautiful insanely detailed image of glowing seascape volcano in golden spring". beautiful golden mountains, bright dark yellow ornate sun, by Victo_Ngai, Oleksandra Ekster, Malevich, Vladyslav Yerko and Alexander Jansson, Vladyslav Yerko! Very Complex perfect elegant composition! linen gesso acrylic paper, epic Dramatic lighting! Razor-sharp quality insanely detailed, deep colors realistic masterpiece<lora:xl_more_art-full_v1:0.5>

아래는 이를 기반으로 생성된(img2vid) 비디오입니다.

아래는 또 다른 예입니다.
프롬프트: A portrait of a fairy princess, tiara, long flowery hair, fantasy, soft background, sea-like , bluish dress, bare shoulders, UHD, 8k, beautiful composition, a modern surrealistic <lora: add_detail_xl>

아래는 위의 이미지를 기반으로 생성한 비디오입니다.

매개변수

- video_frame : 프레임의 수. 25로 둡니다. SVD XT 모델이 25 프레임으로 학습되었기 때문입니다.
- motion_bucket_id: 움직임의 크기를 제어합니다. 큰 값을 넣으면 더 많이 움직입니다.
- fps: 초당 프레임수(frams per second)
- Augmentation_level : 초기 이미지에 추가되는 잡음의 양. 높은 값을 주면 최초 프레임에서 비디오가 좀 더 많이 달라집니다. 비디오 크기를 다르게 할 경우 이 값을 증가시킵니다.
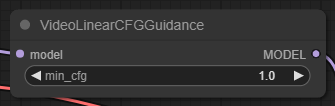
- min_cfg : 비디오 시작시의 CFG 척도를 설정합니다. KSampler에 cfg 값을 설정하는데, min_cfg에서 서서히 cfg로 변해가게 됩니다. 예를 들어 이 워크플로에서는 min_cfg가 1.0이고, cfg는 2.5 이므로, 첫번째 프레임의 CFG는 1.0, 마지막 프레임의 CFG는 2.5, 중간 프레임들은 1.0에서 2.0 사이 값을 가지게 됩니다.
ComfyUI에서 이미지를 비디오로 전환하기(img2vid)
위의 워크플로는 텍스트 프롬프트를 입력해서 video 를 생성했지만, 이미지를 입력해서 비디오로 전환하는 것도 매우 쉽습니다.
위 워크플로에서 [Text to Image] 그룹을 우클릭한 후, "Set Group Nodes to Never"를 선탟합니다. 그러면, 이 그룹에 있는 모든 노드들이 사용되지 않습니다.
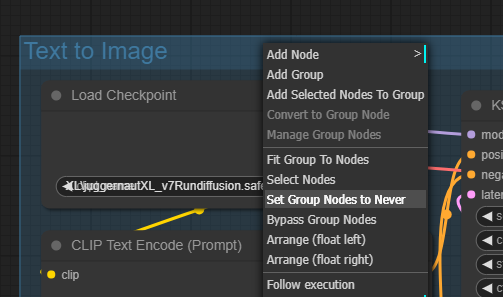
그 다음 아래쪽에 있는 [Load Image] 노드에서 적당한 이미지를 선택한 후, "IMAGE" 출력 슬롯을 [SVD_img2vid_Contitioning] 노드의 "init_image" 입력노드에 연결시켜주면 됩니다. 다만, 입력 이미지의 크기와 [SVD_img2vid_Contitioning] 노드에 있는 height/width를 적당하게 맞춰줘야 합니다.
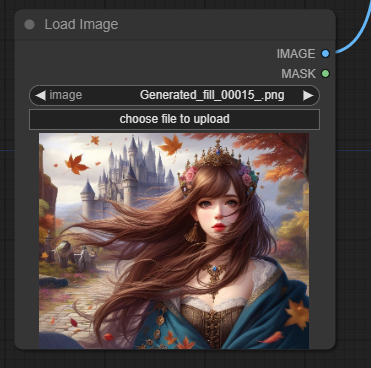
아래는 입력한 이미지입니다.

아래는 이 이미지를 사용하여 생성한 비디오 입니다. 참고로 생성시간은 160초 정도 소요되었습니다.

이상입니다.
===
이 글은 https://stable-diffusion-art.com/stable-video-diffusion-img2vid/ 에서 쓸데 없는 내용들은 삭제하고, 일부 편집해서 작성한 글입니다.
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기