이 글은 주로 ComfyUI 에서 SDXL refiner 모델을 사용하는 방법을 다룹니다. 이 시리즈는 아래와 같이 구성되어 있습니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(1) - 기초 - 이 글. 아주 간단한 기본 SDXL 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(2) - 조건부여 - SDXL 에만 적용되는 조건부터를 추가하고, 조건부여 파라미터 변경에 따른 이미지 영향을 시험합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(3) - Refiner - 완전한 SDXL 프로세스를 위해 refiner 모델을 추가합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(4) - LoRA - 커스텀 노드를 설치하고 LoRA를 사용하는 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI와 SDXL 사용법(5) - img2img - img2img 를 사용하는 워크플로를 생성합니다.
불행히도 아직 refiner모델에 대한 상세한 내용은 알려진게 별로 없습니다. StabilityAI에서 아직 자세한 내용을 발표하지 않았기 때문입니다. 그냥 별도의 모델이고, base 모델후에 사용해야 하며, 최종 출력물의 품질을 향상시키는 게 목적이라는 정도입니다. 이 모델은 완전히 선택적입니다. base 모델만 사용해도 상당히 휼륭한 결과물을 만들기 때문입니다. SDXL 논문에서 언급한 내용은 다음과 같습니다.
샘플 품질을 개선하기 위하여, 우리는 동일한 잠재 공간에서 고품질, 고해상도 데이터에 특화된 별도의 LDM을 훈련하고, 기본 모델의 샘플에 대해 SDEdit [28]에서 도입한 노이즈 제거 프로세스를 적용하였습니다. 우리는 [1]을 따라 처음 200개의 (이산) 잡음 스케일에서 이 정제 모델을 특화하였습니다. 추론하는 동안 기본 SDXL에서 잠상을 렌더링하고, 동일한 텍스트 프롬프트를 사용하여 정제 모델에 대해 레이턴트 공간에서 직접적으로 확산(디퓨전) 및 잡음 제거를 수행합니다(그림 1 참조). 이 단계는 선택 사항이지만, 그림 6과 그림 13에서 볼 수 있듯이 세부적인 배경과 사람의 얼굴에 대한 샘플 품질을 향상시킵니다.
이를 통해 SDXL refiner 모델을 추가할 것인지 말것인지 판단할 수 있지만, refiner 모델을 사용할 때 필요한 요소도 몇가지 알 수 있습니다.
- 동일한 텍스트 프롬프트를 그대로 사용해야 함
- SDXL base 처리를 통해 생성된 잠상(latent image)를 그대로 refiner 모델에 넘겨야 함(디코딩하면 안됨)
- 그런데, base 잠상 잡음 제거(denoising)중 어떤 단계에서 refiner로 넘겨야 하는지는 명확치 않습니다. 우리는 80/20 정도가 좋다고 결론 내렸지만, 논문에서는 아무런 언급이 없습니다. "처음 200개의 (이산) 잡음 스케일에서"라고는 되어 있는데, 이것만으로는 부족하죠. 그래서 여기에서 직접 시험해 봤습니다.
마지막으로, 최근 SDXL 커뮤니티에서는 SDXL refiner를 사용하지 않고, 다른 워크플로(다른 확대(upscaling)방법)을 사용해 최종 결과물의 성능을 향상시키는 경향이 있음을 발견했습니다. 현재 refiner 모델을 미세조정할 수 있는 맞춤형 학습 프로토콜이 전혀 없는 상태임을 고려하면, 이는 매우 합리적으로 보입니다. 즉, base에 LoRA를 적용하면 refiner는 이를 사용하지 않아, 최종 이미지에서 디테일/피사체 추가를 취소할 수 있습니다.
Workflow에 Refiner 추가하기
이글에서는 두 단계로 진행합니다. 첫번째는 base 모델만 사용해서 이미지를 생성하는 워크플로는 그대로 두고, refiner 모델을 추가한 워크플로를 추가하면서 최적의 세팅을 찾아가는 실험을 해봅니다. 두번째는 중복되거나 필요없는 노드들을 삭제하고 refiner 모델을 추가한 최종 SDXL 워크플로를 생성합니다. 중간 부분 실험은 필요없이 그냥 refiner 모델을 사용하고싶다면, 그냥 맨 아래로 내려가시면 됩니다.
시작 워크플로는 ComfyUI 사용법 기초(2)에서 최종적으로 만들어진 워크플로입니다. 이 글을 먼저 읽거나 이해가 안되시면 1편과 2편을 먼저 읽어보시기 바랍니다.
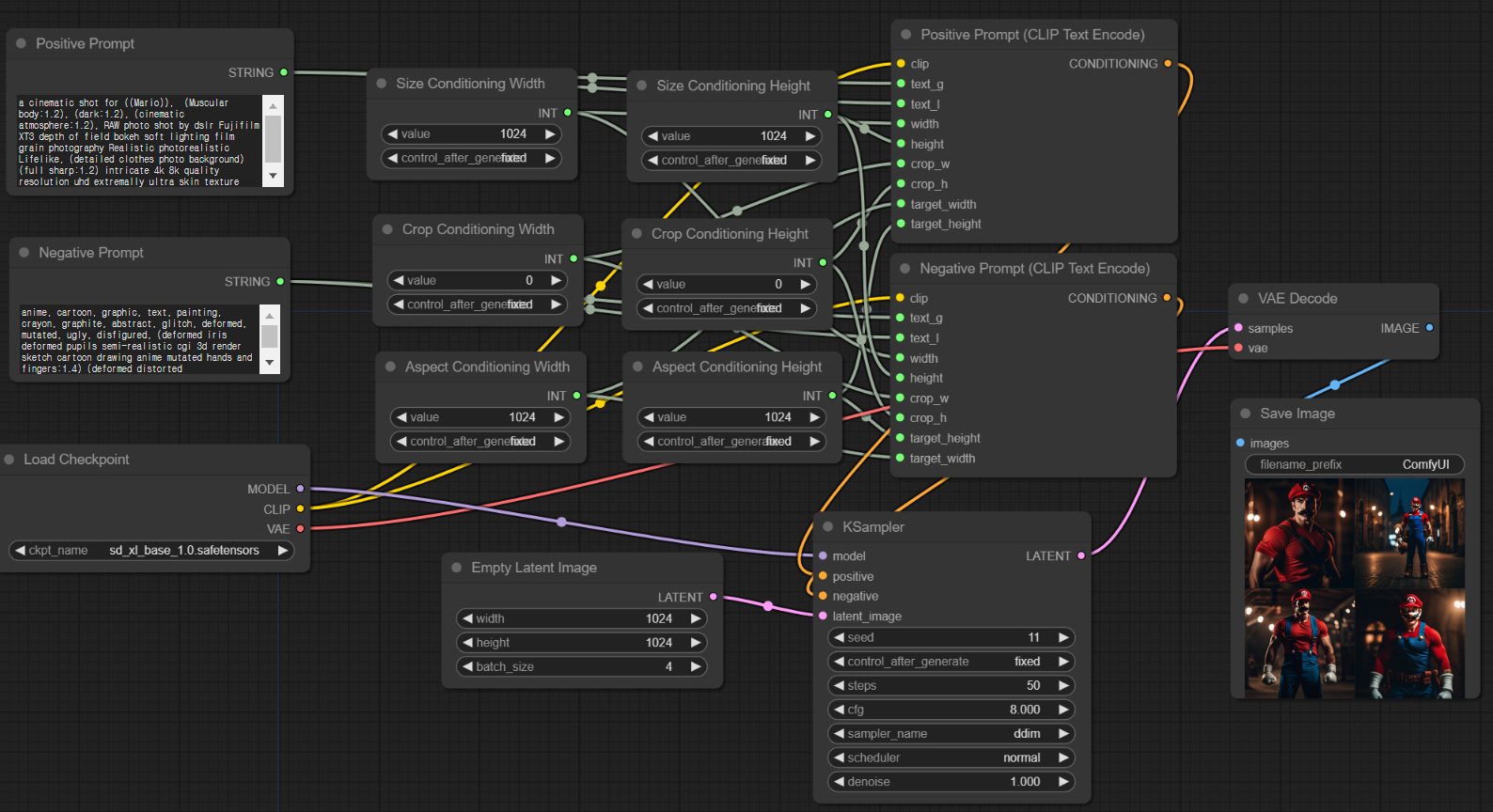
그냥 이 워크플로를 불러오고 싶다면 이 링크에 있는 그림을 다운로드한 뒤, ComfyUI 캔버스에 드래그/드롭하면 됩니다.
이 글에서는 아래와 같은 프롬프트를 사용합니다.
프롬프트: Amazing detailed photography of a cute beautiful girl, pink hair, high resolution, piercing eyes, Anti-Aliasing, FXAA, De-Noise, Post-roduction, SFX, insanely detailed & intricate, elegant, ornate, hyper realistic, super detailed, noir coloration, serene, 16k resolution
부정적 프롬프트: (worst quality, low quality, illustration, 3d, 2d, painting, cartoons, sketch), tooth, open mouth, dull, blurry, watermark, low quality, black and white, city
고급 KSampler 노드 추가
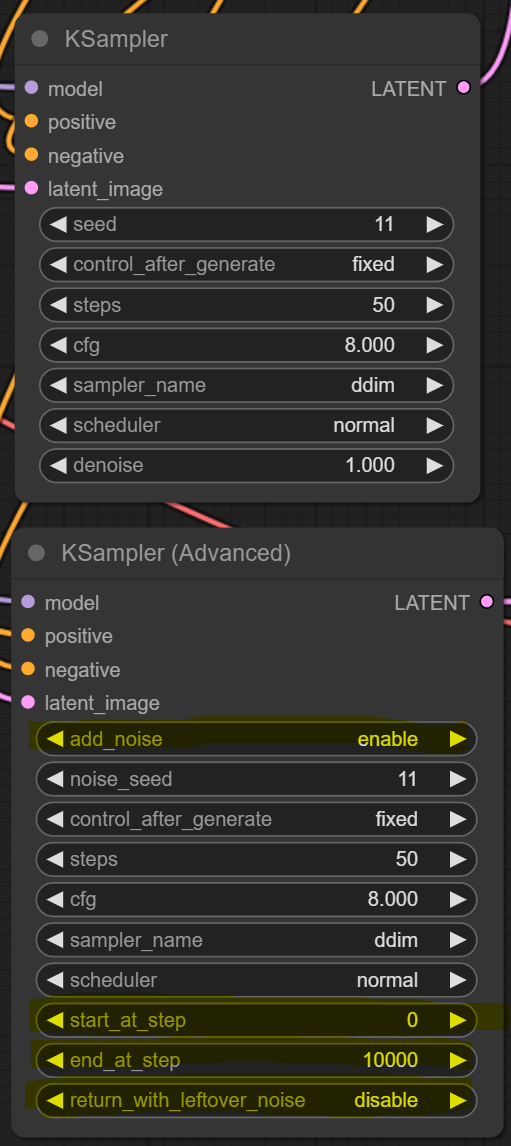
디퓨전 프로세스를 좀더 세밀하게 제어하기 위해선는 샘플러 노드를 다른 것으로 바꿔야 합니다. refiner 모델을 사용하려면, base 모델을 사용하는 프로세스에서 이미지가 완성되기 전에 refiner로 넘겨줘야 하기 때문입니다. 추가할 노드는 고급 KSampler로서, 아랙 그림과 같이 캔버스를 우클릭하고 Add node -> sampler -> KSampler(Advanced)를 선택하여 추가할 수 있습니다.

아래는 일반 KSampler와 고급 KSampler를 비교해 본 모습입니다. 전반적으로는 비슷하지만, 4개의 입력란이 추가되었음을 알 수 있습니다. 먼저 동일한 입력란은 같은 값으로 채워넣고 나머지 항들을 자세히 들여다 보겠습니다.
이제 이 고급 샘플러 노드를 아래와 같이 연결해줍니다. 단, 결과물을 비교해볼 수 있도록 원래 워크플로는 건드리지 않습니다.
- model 입력 슬롯 - 체크포인트 노드의 MODEL 출력 슬롯
- positive/negative 입력 슬롯 - 각각 Posiitive/Negative TextEncoderSDXL 노드의 CONDITIONING 출력 슬롯
- latent_image 입력 슬롯 - Empty Latent Image의 LATENT 출력 슬롯
다음으로 VAE Decode 노드를 하나 더 추가합니다. 빈 캔버스에서 우클릭 Add Node -> latent -> VAE Decode를 선택하면 됩니다. 그 다음 Add Node -> image -> Preview image를 선택해 Preview 노드도 하나 추가해 줍니다.

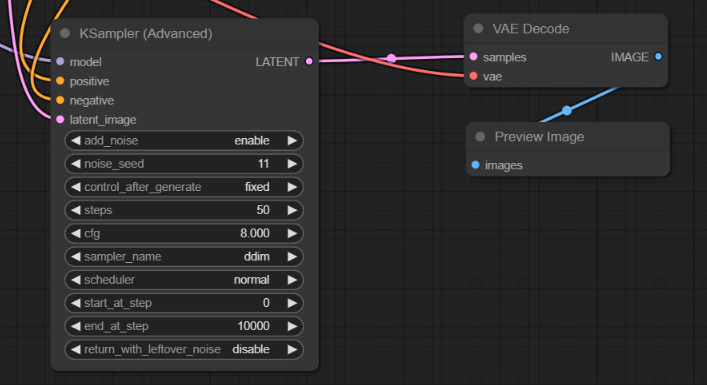
다음으로 이 VAE Decode 노드를 아래와 같이 연결해줍니다.
- samples 입력 슬롯 - 위에서 만든 KSampler (Advanced) 노드의 LATENT 출력 노드
- vae 입력 슬롯 - Load checkpoint 노드의 VAE 출력 노드
- IMAGE 출력 슬롯 - 바로 위에서 만든 Preview image 노드의 images 입력 노드
연결 상태는 아래와 같습니다.
아래가 시행 결과입니다. 보시는 것처럼 완전히 동일한 이미지가 생성되었습니다.
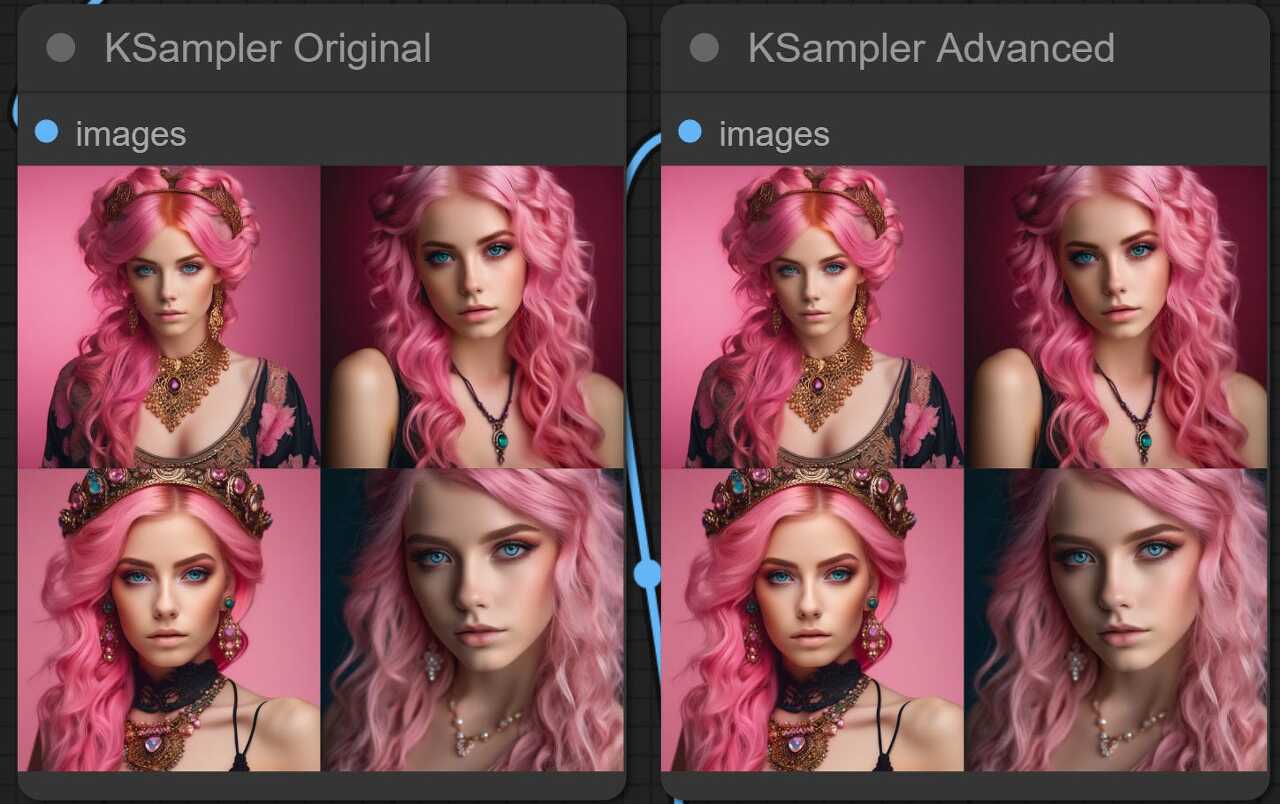
지금부터는 고급 KSampler 에서 추가된 4개의 입력란에 대해 자세히 알아보겠습니다.
add_noise
빈 잠재 이미지가 전달되면, 여기에 노이즈를 추가할지를 결정하는 인자입니다. 그 다음에 이 노이즈를 제거하여 이미지를 생성하게 되죠. 이것을 끄고 시행하면 아래 오른쪽과 같이 아무 이미지도 생성되지 않습니다.
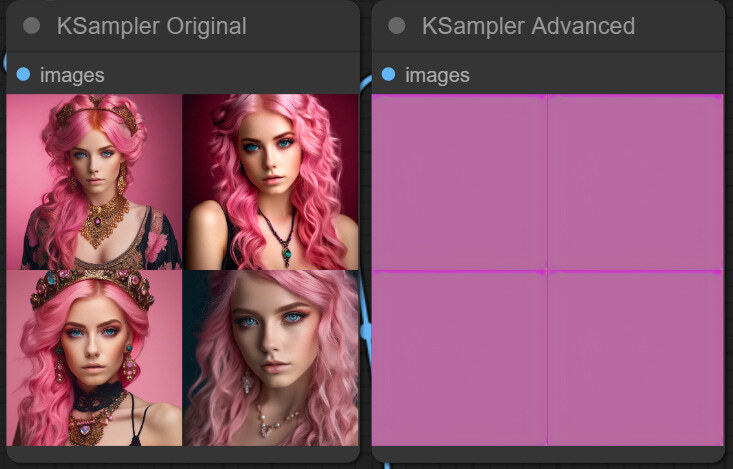
이렇게 보면 무쓸모일 것 같지만, Refiner 모델을 사용하려면 중요합니다. Refiner 모델은 새로 잡음을 추가하는 게 아니라, base 모델을 사용해 생성된 이미지를 받아서 사용하기 때문에 잡음을 추가할 필요가 없고, 따라서 add_noise 옵션은 Disable 시켜야 합니다.
start_at_step, end_at_step
잡음제거를 시작하고 끝내는 단계입니다. 원래 잡음 제거 단계수(sampling steps)를 지정하면, 각 디퓨전 프로세스에서 어느정도 잡음을 제거할지(잡음제거 스케줄)이 정해집니다. 예를 들어 우리 워크플로와 같이 50 단계를 지정하고 start_at_step(기본값 1) 및 stop_at_step(기본값 10000)을 기본값으로 설정하면 정상적으로 잡음제거가 이루어집니다.
그런데 start_at_step 을 예를 들어 5, 15, 20 등으로 두면 앞쪽 잡음제거 단계가 생략되어 숫자를 크게할 수록 미완성이미지가 만들어지게 됩니다. end_at_step도 끝나는 부분의 잡음제거 단계가 생략되는 형태로 비슷한 효과가 만들어집니다. 따라서 만약 하나의 프로세스만 돌린다면 이 값은 변경하지 않는 게 일반적입니다.
그런데, SDXL의 경우, 앞부분은 base model로 생성하고, 완성되기 전에 refiner model에 넘겨져 처리되는 방식으로 이루어집니다. 예를 들면 전체 잡음 제거 단계수가 50 일때, base 모델 이미지 생성 프로세스에는 stop_at_step을 40으로 지정하고, refiner 모델 프로세스에서는 start_at_step 을 41로 지정하면 연이어 작업을 하게 되는 것입니다.
returen_with_leftover_noise
이 값은 end_at_step으로 잡음 제거 절차가 끝난 뒤, 잡음이 남아있는 상태로 넘긴다는 뜻입니다. stop_at_step을 40으로 설정하고 return_with_leftover_noise를 enable로 두고 실행하면 아래 우측과 같이 잡음이 많이 남은 상태로 이미지가 생성됩니다.
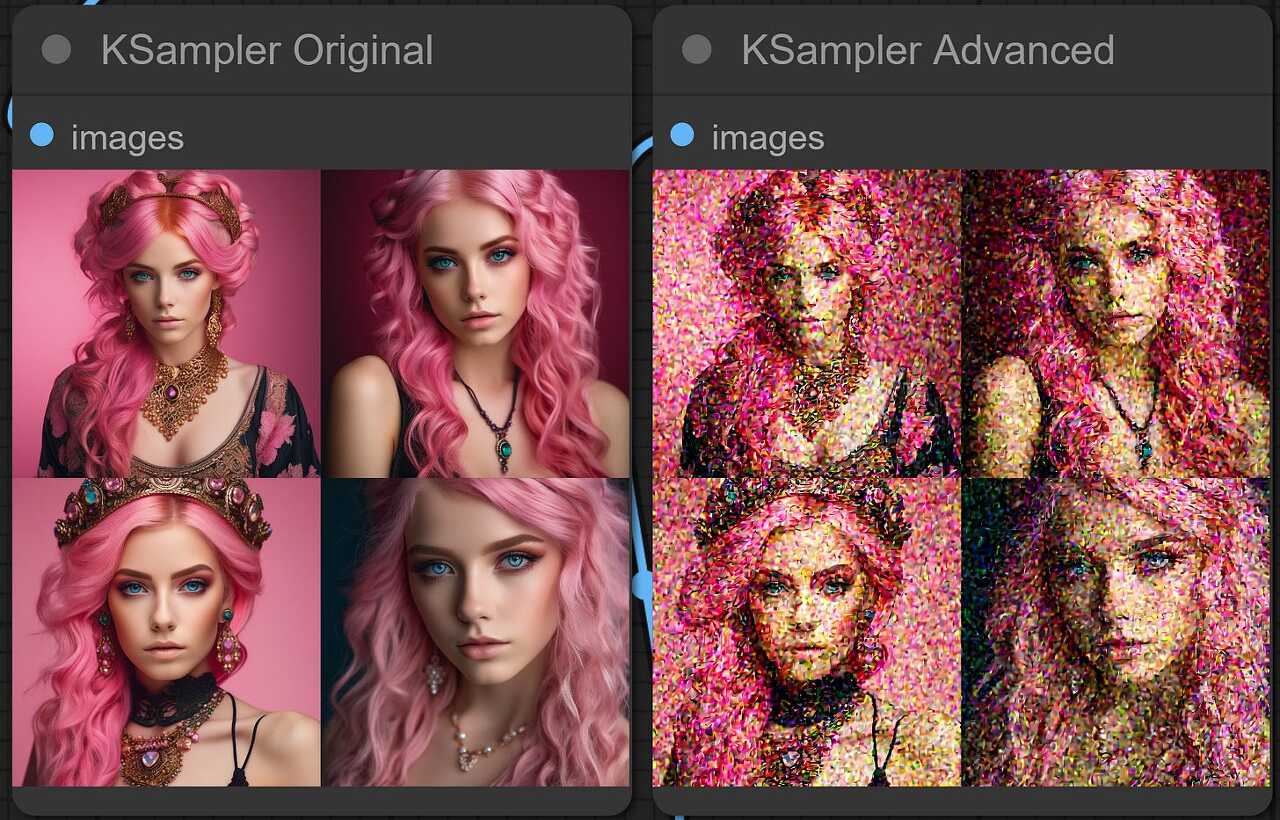
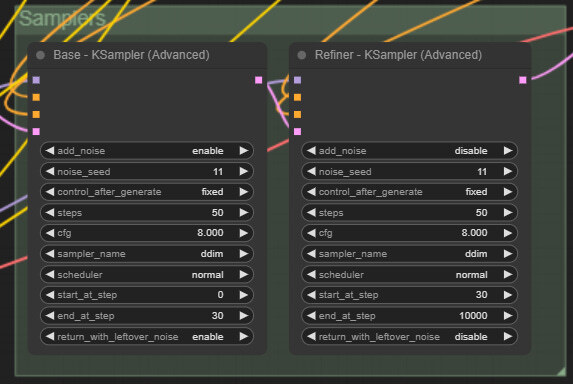
이러한 값들을 고려하면, base 모델 이미지 생성절차와, refiner 모델 이미지 생성절차는 각각 아래와 같이 설정하면 됩니다.
| base | refiner |
| add_nose : enable start_at_step : 0 end_at_step : 40 return_with_leftover_noise : enable |
add_nose : disable start_at_step : 40 end_at_step : 10000 return_with_leftover_noise : disable |
Refiner 구현
Refiner 모델을 추가하려면 별도의 고급 KSampler 노드를 하나 더 추가하고, SDXL refiner 모델을 불러올 체크포인트 노드가 하나 더 필요하며, 이미지를 최종 생성하고 보기 위한 VAE decode 노드와 image preview 노드가 필요합니다.
먼저 고급 KSampler를 추가하겠습니다. 빈 캔버스에서 우클릭후 Add Node -> sampling -> KSampler (Advanced) 를 선택하면 생성됩니다. 이것을 위에서 생성한 고급 KSampler 아래에 두고, 바로 위에 있는 표와 같이 값을 변경시킵니다. 또, 이 두가지를 구분시키기 위해 Title도 변경시킵니다. 그리고 Base 쪽 출력 LATENT를 Refiner쪽 입력 latent_image에 연결해줍니다. 그 결과는 아래와 같습니다.
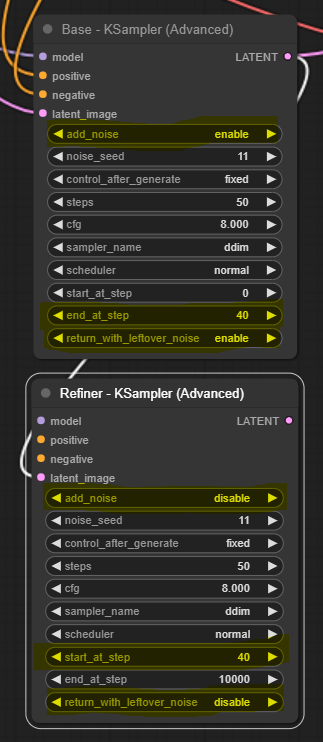
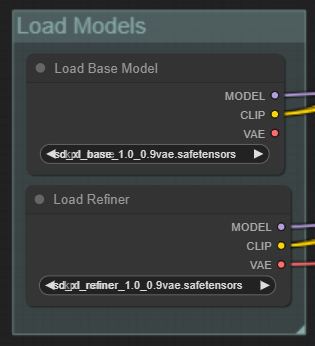
이제 refiner 모델을 불러오기 위한 [Load Checkpoint] 노드를 추가합니다. Refiner KSampler의 좌측 model 슬롯을 드래그해서 빈 캔버스에 떨어뜨린 후, CheckpointLoaderSimple을 선택하면 노드가 추가됩니다. 체크포인트 파일은 sd_xl_refiner_1.0_0.9vae.safetensors 를 선택합니다.
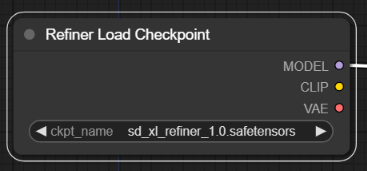
이제 프롬프트 노드를 추가해주어야 합니다. 그런데, 예전에 만들어둔 Positive TextEncoder 및 Negative TextEncoder는 사용하지 못합니다. refiner 모델은 base모델과 조건부여 매개변수가 다르게 학습되었기 때문입니다. 따라서 새로운 refiner용 TextEncoder가 필요합니다.
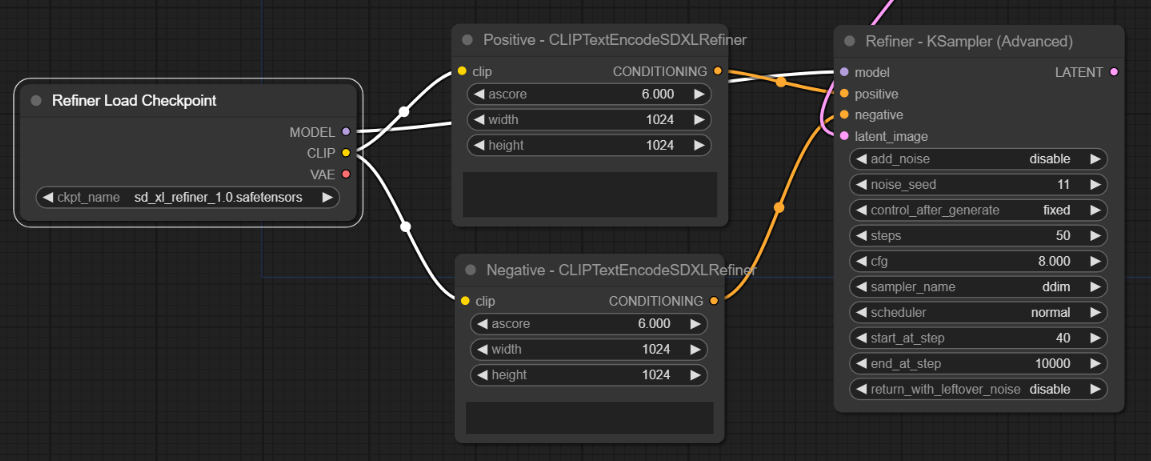
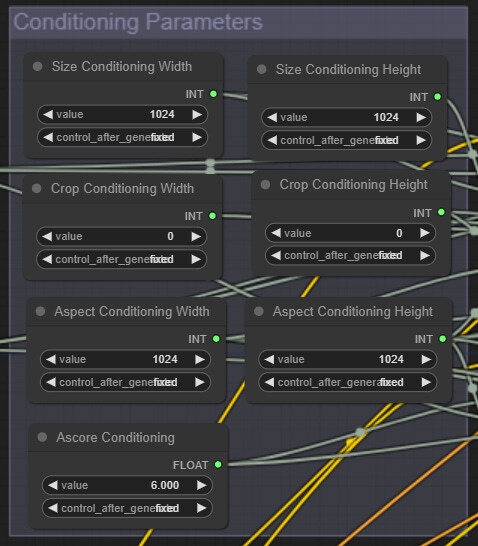
빈 캔버스를 우클릭하고 Add Node -> Advanced -> conditioning -> CLIPTextEncodeSDXLRefiner 를 선택합니다. 두 개를 생성해서 각각 Positive/Negative로 제목을 수정해줍니다. 그리고 다음과 같이 연결해 줍니다. (참고로 CLIPTextEncodeSDXLRefiner에는 ascore와 height/width 입력란이 있는데 이에 대해서는 아래에서 설명합니다)
- 좌측 clip 입력 슬롯 - Refiner 체크포인트 로더 노드의 CLIP 출력 슬롯
- 우측 CONDITIONING 출력 슬롯 - 바로 위에 생성한 Refiner KSampler 노드의 왼쪽 positive/negative 입력 슬롯
아래가 결과입니다.
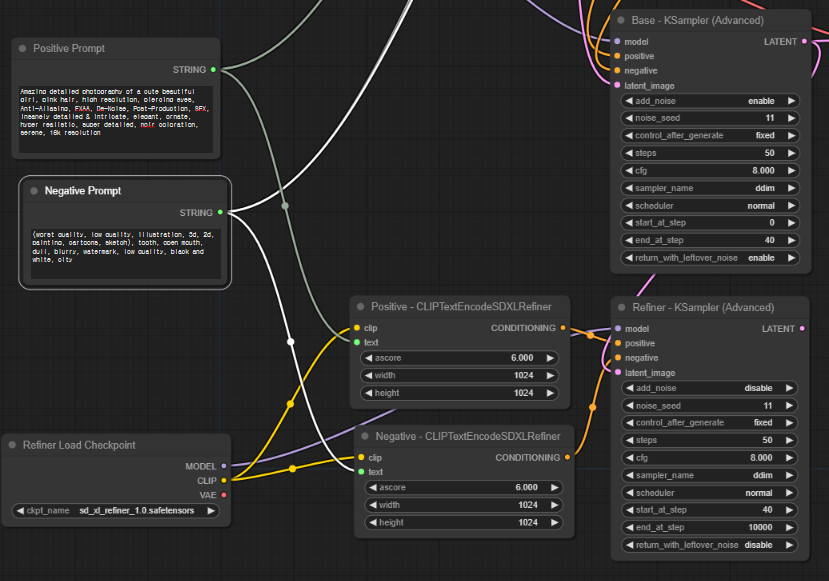
프롬프트 자체는 base 모델과 동일하게 사용합니다. 따라서 여기에서는 별도로 프롬프트를 입력할 필요가 없습니다. 이들 노드를 우클릭하고 convert text to input을 누릅니다. 그러면 아래와 같이 프롬프트 입력란은 사라지고, text라는 입력 슬롯이 추가됩니다. 이 입력 슬롯은 base 모델용 프롬프트 텍스트에 연결해주면 됩니다. 아래가 결과입니다.
마지막으로 Refiner 용 KSampler의 우측 LATENT 출력 노드를 드래그해서 VAEDecode 노드를 추가하고, VAEDecode 노드의 IMAGE 출력 노드를 드래그해서 Preview Image 노드를 추가해줍니다. 또한 VAEDecode 노드의 vae 입력노드는 Refiner 체크포인트 노드의 VAE 출력 노드에 연결해주면 됩니다.
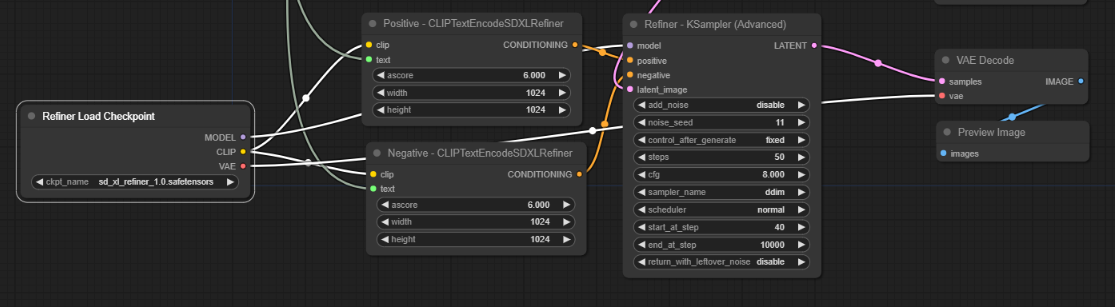
지금까지 만들어진 워크플로입니다. 위쪽은 base 모델만 사용하는 워크플로, 아래쪽은 refiner까지 사용하는 워크플로까지 있고, 노드가 너무 많아서 아주 복잡합니다. (아래쪽에서 정리할 예정입니다) 직접 생성하기 귀찮으신 분은 이 링크의 이미지를 ComfyUI 캔버스에 드래그&드롭하면 됩니다.
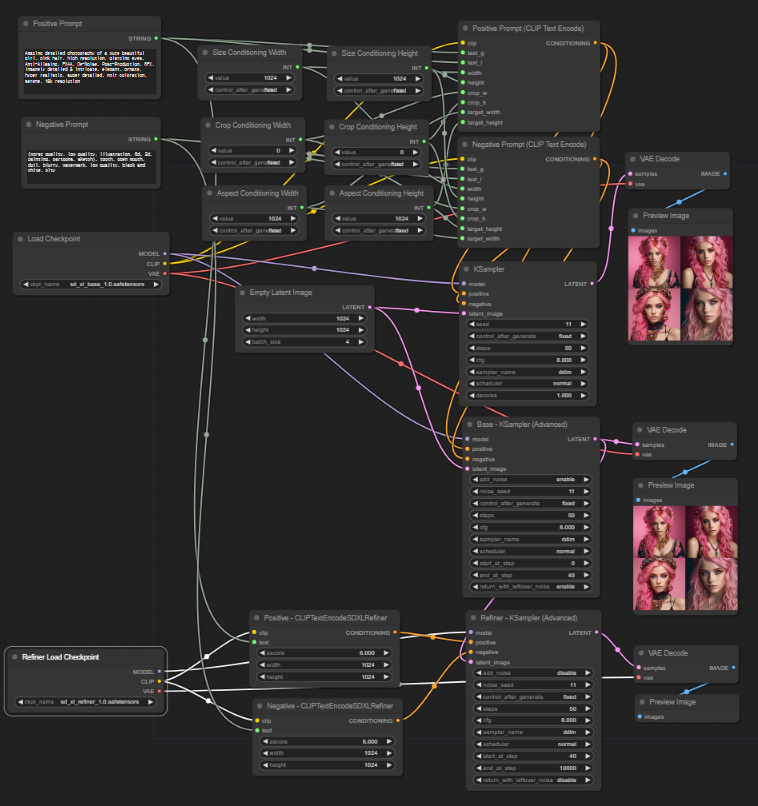
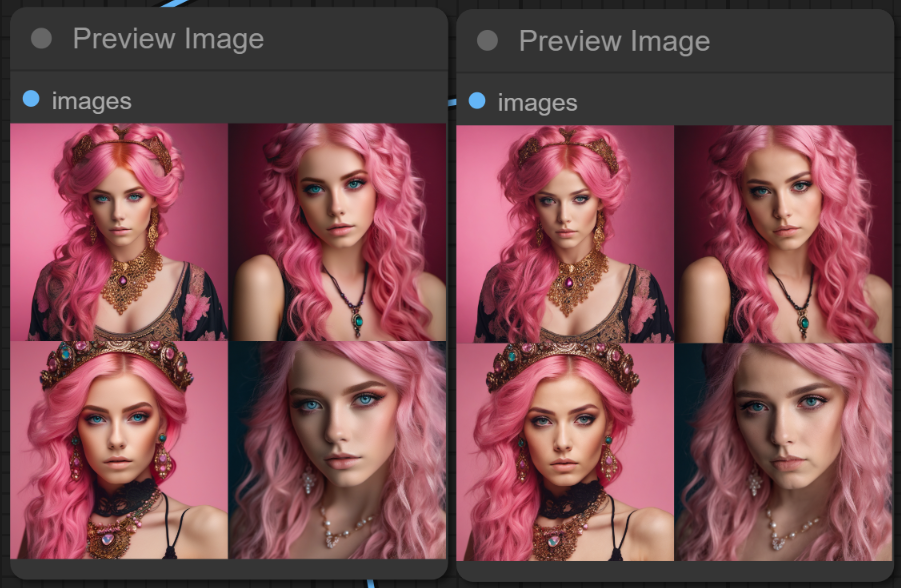
아래는 위의 설정으로 이미지를 생성한 결과입니다. 왼쪽은 base 모델만 사용한 경우, 오른쪽은 refiner 모델까지 사용한 경우입니다. 1~40 까지 base, 41~50은 refiner 가 담당하므로, 80:20인데, 양쪽이 거의 차이가 없네요.
그래서 비율을 바꿔가면서 몇가지를 더 시험해 보기로 했습니다. 먼저 25:75 (즉 base 1~12, refiner 13~50) 를 적용한 결과입니다. 출력 이미지가 나쁘다는 것은 아니지만, base 모델만 사용했을 때와는 상당히 많이 다른 이미지가 생성되었습니다.

다음은 50:50 (즉 base 1~25, refiner 25~50) 일 경우입니다. base 모델과 상당히 비슷해지만 군데 군데 차이가 있습니다. 디테일이 추가되었다기 보다는 어딘가 모자란듯한 느낌도 약간 들고요.

다음은 75:25 (즉 base 1~33, refiner 34~50) 일 경우입니다. 제가 보기엔 이 정도도 base모델만 사용했을 경우와 거의 비슷한 정도가 아닐까 싶네요.

아래가 base 모델만 사용했을 경우입니다.

이 정도로 보면, 대략 50:50까지는 base모델만 적용한 경우에 비해 차이가 심하고, 80:20정도면 거의 비슷하니 그 사이 정도에서 적당한 값을 찾아야 할 것 같습니다.
아래는 세번째 이미지에 대해 60:40, 70:30, 80:20, 그리고 base 모델만 적용한 경우를 비교해본 것입니다. 아래는 참고로 배치 형태입니다.
| 60:40(30에서 자른 경우) | 70:30(35에서 자른 경우) |
| 80:20(40에서 자른 경우) | base만 적용한 경우 |
 |
 |
 |
 |
아래는 동일한 조건으로 네번 째 이미지를 비교해본 결과입니다.
 |
 |
 |
 |
대략 보면 base:refiner = 70:30 정도로 설정하는 게 제일 좋을 듯합니다. 물론 피사체가 달라지면 다른 결과가 나올 수는 있습니다.
아직까지 확인할 것은 더 많겠지만, 지금까지 알려진 사실을 정리하면 아래와 같습니다.
- refiner KSampler의 add_noise는 disable 시켜야 한다. disable 시키지 않으면 잡음이 많은 이미지가 생성된다. 이렇게 add_noise를 비활성화시키면 noise_seed 와 control_after_generate는 아무런 역할을 하지 않는다.
- base KSampler와 동기화 시켜야 한다. 아니면 잡음이 많거나 품질 낮은 이미지가 생성된다.
- CFG와 sampler_name 은 base KSampler와 달라도 무방하다. 잘 조합하면 더 좋은 결과가 나올 수도 있다.
- scheduler는 base KSampler와 동일해야 한다.
- refiner의 start_at_step과 base의 stop_at_step와 같아야 한다. 아니면 이미지 품질이 낮아진다.
CLIPTextEncodeSDXLRefiner의 ascore 와 width/height
위에서 잠깐 언급한 것처럼, refiner의 TextEncoder 에는 이미지 크기에 대한 조건부여(conditioning)과 ascore(aesthetic score)라는 처음 보는 조건부여가 있습니다. 논문에는 이에 대한 자세한 언급은 없지만, 학습 데이터 세트의 이미지에 특별한 모델을 사용해 부여한, 이미지가 얼마나 미적으로 만적스러운지 평가하기 위한 지표입니다. 따라서 이론적으로는 ascore 값이 높을 수록 이미지가 더 좋아질 것입니다. 하지만, 점수가 올라갈 수록 해당되는 이미지 수가 기하급수적으로 감소하기 떄문에 최적 지점을 찾아야 할 필요가 있습니다. 이 글에서는 6에서 시작하기로 했습니다.
아래는 ascore를 4, 6, 8로 변경하면서 이미지를 생성한 결과입니다. 4에서는 확실히 품질이 안좋습니다. 워터마크도 보이고 흐릿한 경우도 많이 발생하였습니다. 6부터 8까지는 이미지 변화가 그다지 많지 않습니다. 디테일이 추가된 것 같기는 한데, 약간 이상한 결함도 보이는 듯합니다.
 |
 |
 |
width/height 조건부여에 대해서는 어떤 값을 사용하여야 할 지 명확하지 않습니다. 그냥 refiner 모델은 좀더 높은 해상도의 데이터셋을 사용할 것 같다는 정도입니다. 일단은 종횡비와 동일한 값으로 사용할 예정입니다.
워크플로 정리
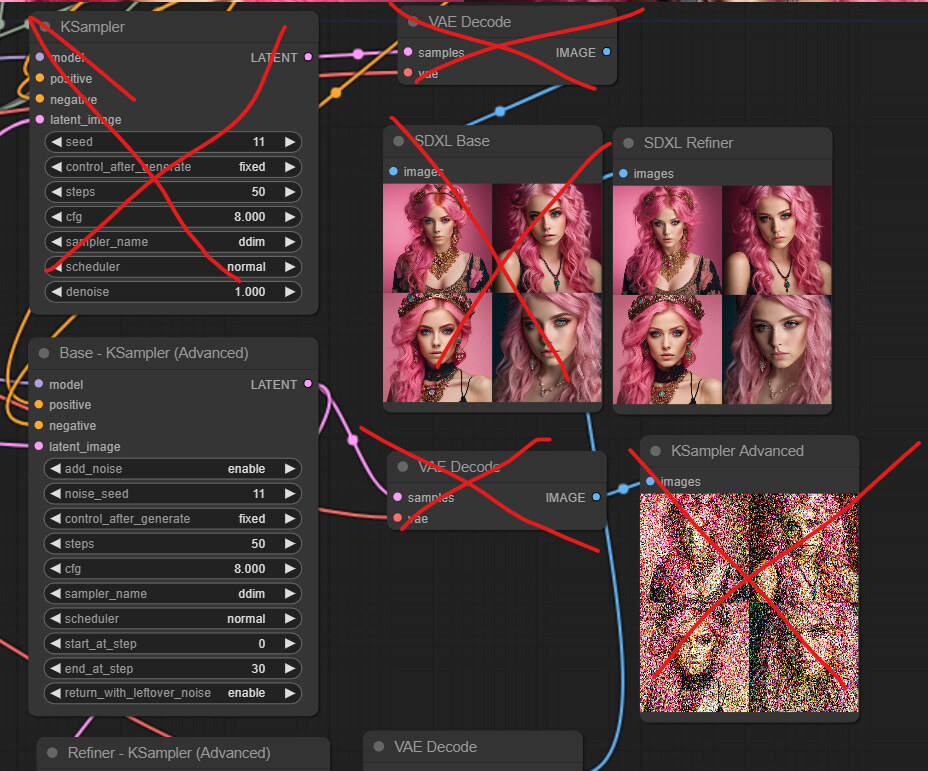
이제는 비교가 끝났으므려, base 모델로만 생성한 이미지는 필요가 없습니다. 따라서 KSamper 노드와 VAE Decode 노드, Image Preview 노드를 삭제합니다. 또한 Base - 고급 KSampler 에서 직접 생산되는 잡음섞인 Image 도 필요없으니 삭제합니다.
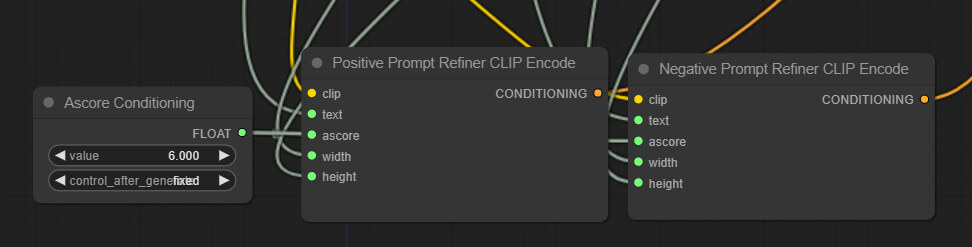
다음으로 TextEncoder CLIP 인코딩 노드를 정리합니다. 이들 노드를 우클릭한 후, ascore/width/height를 모두 입력 슬롯으로 전환합니다. 다음 ascore 입력 슬롯을 캔버스위에 드래그&드롭하고 Add Node -> utiis -> Primitive 를 선택합니다. 이 노드에 Positive/Negative CLIP Encode 노드를 모두 연결해야 합니다.
그 다음 남아있는 width/height 입력 슬롯을 base 쪽의 Aspect Conditioning 의 Width/Height에 각각 연결해줍니다.
이제 좀더 알아보기 쉽도록 여러가지 노드를 그룹으로 묶어보겠습니다. 캔버스 아무곳이나 우클릭하고 Add Group을 누릅니다. 그리고 Positive Prompt 와 Negative Prompt를 그 속에 넣고 적절히 크기와 이름을 조정합니다.
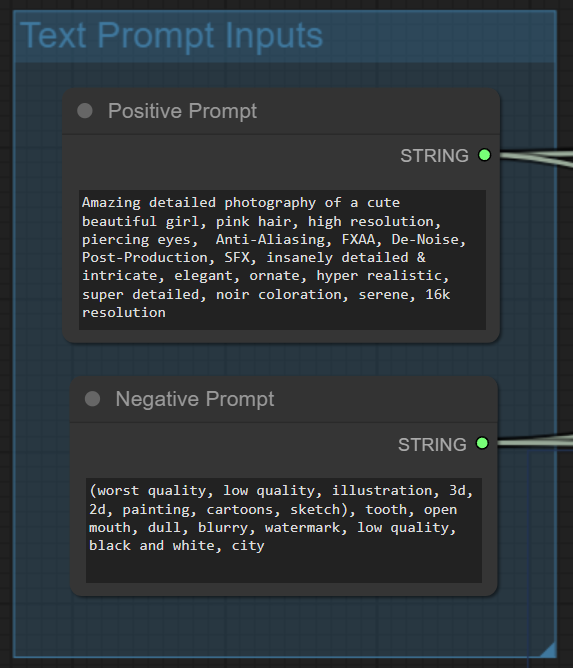
체크포인트 모델도 함께 그루핑하고요....
조건부여 파라미터 입력 그룹도 만듧니다. 모두 7개가 포함되네요.
다음으로 KSampler도 그루핑을 하고...
마지막으로 CLIP Encoding 노드도 그룹으로 묶어줍니다. 2개는 base 모델, 2개는 refiner 모델용입니다.

이제 완성되었습니다. 모두 적절한 위치로 옮겨주면 됩니다. 이렇게 해두면 나중에 논리적으로 이해하기도 쉽게 편집하거나 변경도 쉬워집니다.
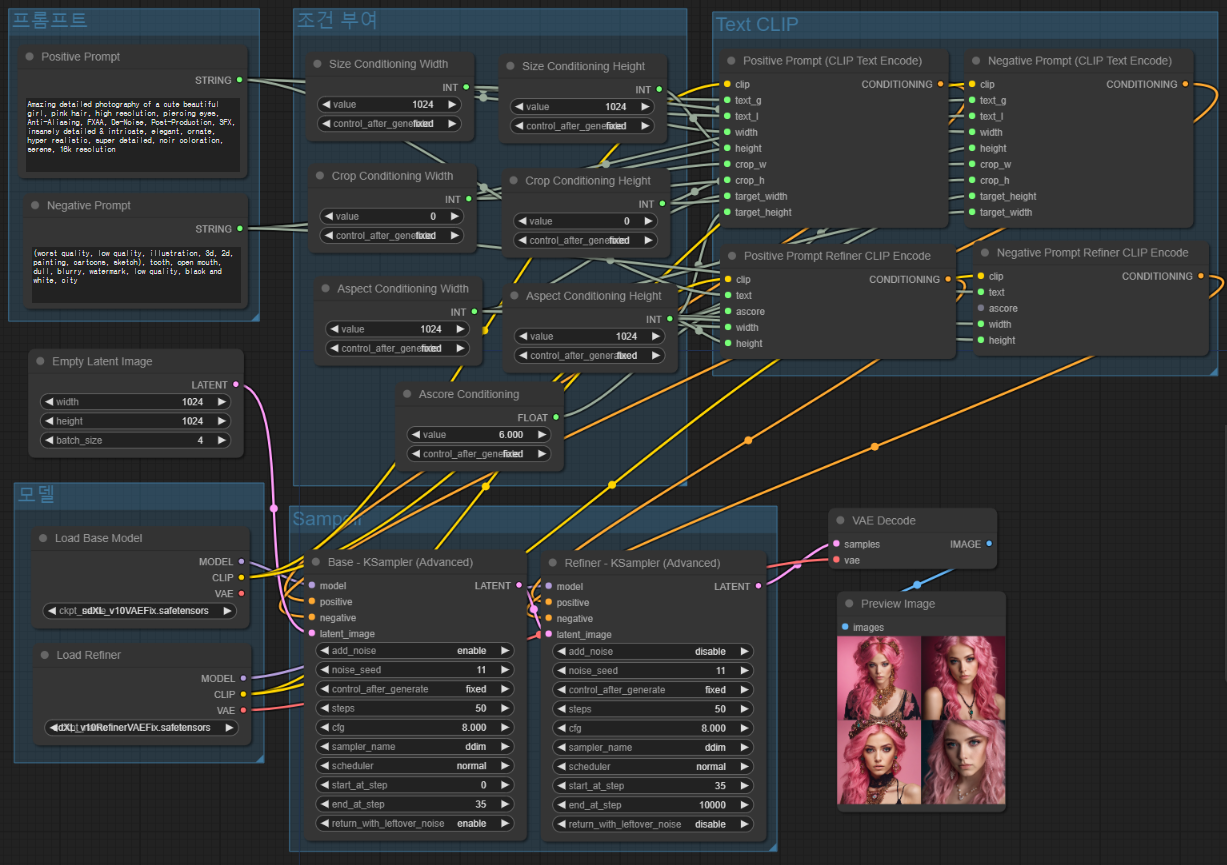
이 워크플로를 직접 사용하고 싶으시면, 아래 그림을 다운로드 받아 ComfyUI 캔버스에 드래그&드롭하면 됩니다.

이상입니다.
이 글은 https://followfoxai.substack.com/p/part-3-sdxl-in-comfyui-from-scratch 를 번역하면서 일부분은 제가 수정/편집해서 작성하였습니다.
민, 푸른하늘
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기