이 글에서는 이전 글까지 만들어온 워크플로에 img2img 기법을 적용하는 방법을 소개합니다.
이 시리즈는 아래와 같이 구성되어 있습니다.
- 스테이블 디퓨전 - ComfyUI 사용법(1) - 기초 - 아주 간단한 기본 SDXL 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI 사용법(2) - 조건부여 - SDXL 에만 적용되는 조건부터를 추가하고, 조건부여 파라미터 변경에 따른 이미지 영향을 시험합니다.
- 스테이블 디퓨전 - ComfyUI 사용법(3) - Refiner - 완전한 SDXL 프로세스를 위해 refiner 모델을 추가합니다.
- 스테이블 디퓨전 - ComfyUI 사용법(4) - LoRA - 커스텀 노드를 설치하고 LoRA를 사용하는 워크플로를 생성합니다.
- 스테이블 디퓨전 - ComfyUI 사용법(5) - img2img - 이 글. img2img 를 사용하는 워크플로를 생성합니다.
SD 1.5의 img2img 워크플로
Github에 있는 ComfyUI_example 사이트에 들어가면, ComfyUI를 사용해서 적용할 수 있는 여러가지 워크플로의 예제를 볼 수 있습니다. 이중에서 img2img 예제에 들어가면 아래와 같은 그림 파일이 있습니다. 이 그림을 다운로드 받아 불러 들이면 img2img 를 사용할 수 있습니다.
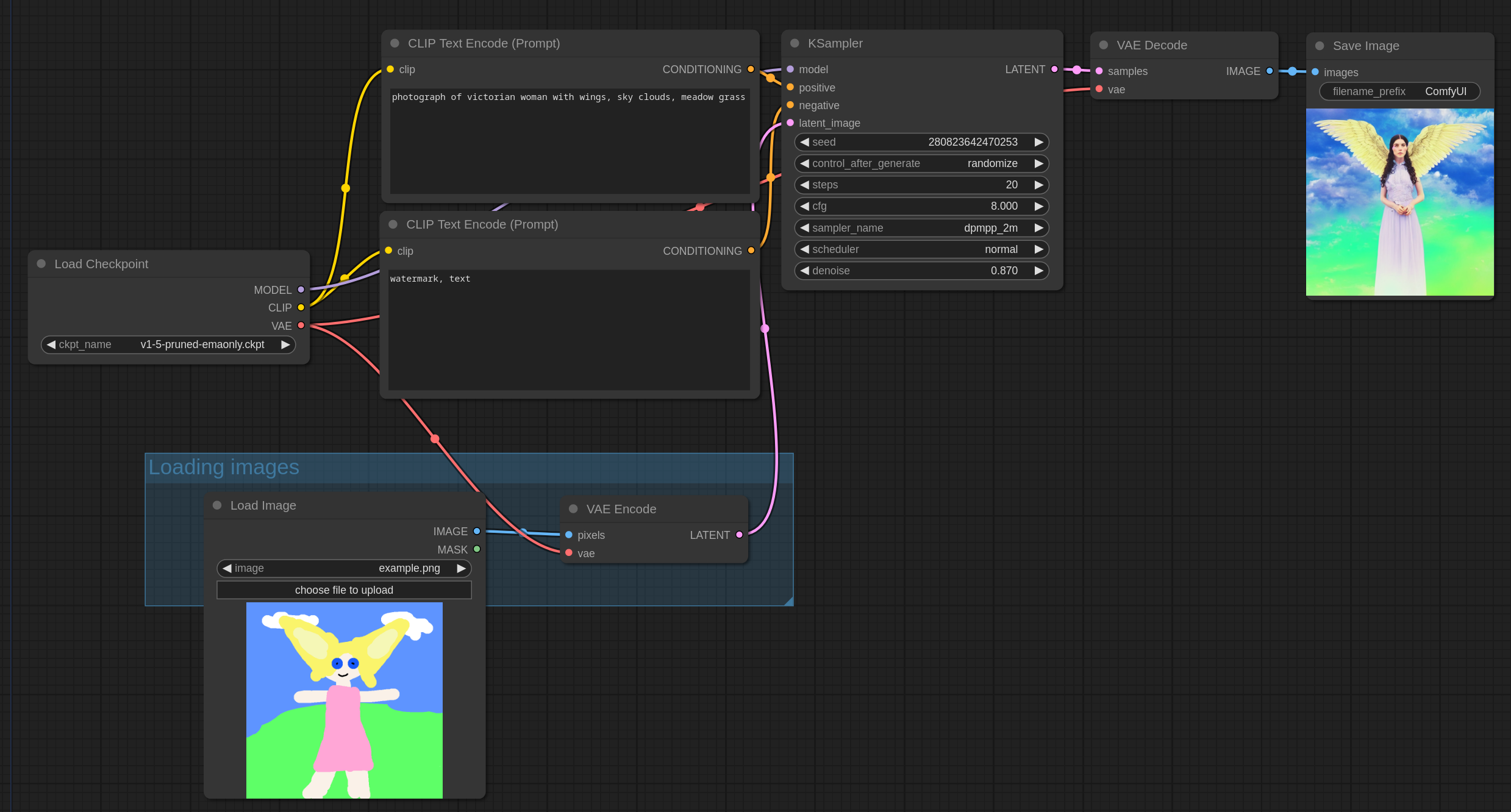
기본적인 txt2img 워크플로는 아래처럼 구성됩니다. KSampler는 체크포인트 모델과 CLIP 모델을 받아들이고, latent image 는 [Empty Latent Image]에서 받아서 사용합니다.

Img2Img의 경우에는 아래와 같이 체크포인트 모델과 CLIP쪽은 변함이 없고, 비어있는 잠재(latent) 이미지 대신 참조 이미지를 VAE로 인코딩한 잠재 이미지로 대체되었다는 점만 다릅니다. 여기에서 [Load Image]노드에 원하는 이미지를 올리면 이 이미지를 기반으로 이미지가 생성됩니다.

이 설정대도 [Queue Prompt] 버튼을 누르면 아래와 같은 이미지가 생성되죠.
 |
 |
사실 이 워크플로는 완전하지는 않습니다. 생성되는 이미지의 크기가 참조 이미지와 완전히 같기 때문입니다. 일단 이런 문제가 있다는 것은 이해하고 SDXL 에서 img2img를 적용하는 방법을 고려해 보겠습니다.
SDXL의 img2img 워크플로
SD1.5 모델과 SDXL 모델을 사용할 때 img2img 워크플로가 달라져야 합니다. 그 이유는 KSampler 를 살펴보면 알 수 있습니다. 아래 왼쪽은 일반 KSampler, 우측은 KSampler(Advanced)로서, 동일한 파라미터를 서로 연결했습니다.

스테이블 디퓨전 - ComfyUI 사용법(3) - Refiner 에서 설명한 것처럼, KSampler Advanced 에서 새로 생겨난 add_noise 등 4개의 위젯은 base 용과 refiner 용을 서로 연동시키기 위한 목적으로 사용됩니다.
그런데, KSampler 에 있는 denoise가 오른쪽에서는 사라졌습니다. 이 값(denoising strength)는 잡음 제거 강도, 즉 얼마나 많이 잡음을 제거할 것인지, 그래서 원본으로 입력했던 이미지와 생성되는 이미지가 얼마나 달라질 것인지를 결정하는 매우 중요한 값입니다. 그런데 이 값을 입력할 수 없다는 것은 아주 이상해 보입니다.
하지만 이것은 의도적이라고 할 수 있습니다. 샘플링을 시작하는 단계(start_at_step)와 샘플링을 끝내는 단계(stop_at_step)를 조절하면 denoising 값을 제어할 수 있기 때문입니다. 좀 더 자세히 말하자면, 총 샘플링 단계를 늘리고, 늘린 단계에서 앞쪽을 적당하게 건너뛰도록 조절하면 잡음 제거 강도를 제어할 수 있다는 것입니다. 예를 들어 총 단계수가 60 step이고, 30 step을 건너뛰도록 하면 denoising strength가 0.5로 설정한 것과 동일해집니다.
그런데, 앞서 refiner를 포함시킨 워크플로에서는 이미 시작 단계와 끝나는 단계를 설정해서 사용중이니, 이것까지 고려해서 전체 단계수와 시작단계, 마치는 단계를 조절해야 합니다. 전체 단계수가 25, base의 비율을 0.8로 설정하였을 경우 base는 20, refiner는 5단계를 수행하게 됩니다. 이 값을 유지하면서 잡음제거 강도값을 0.75로 설정하고 싶을 경우, 총 단계수는 40 단계(25/0.75 = 40)이 되고, 앞쪽 15 단계는 건너뛰도록 설정하면 됩니다.

이제 이것을 고려하며 ComfyUI에서 img2img를 사용하는 워크플로를 설정해 보겠습니다.
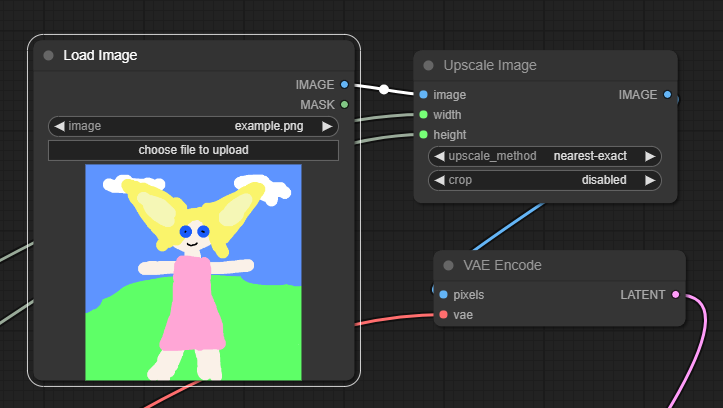
먼저 빈 캔버스 아무곳이나 우클릭해서 Add Node -> image -> Load Image 를 선택합니다. 생성할 이미지의 크기에 맞춰 입력 이미지 크기를 키울 수 있도록 Add Node -> image -> Upscale Image 를 선택합니다. 이 두 노드에서 IMAGE와 image를 링크로 연결해 줍니다. 그 다음 width 와 height 입력 슬롯은 이미지 크기를 설정하는 노드와 연결해주고, upscale_method 는 일단 nearest-exact로 선택해 둡니다.
다음으로 Upscale Image 노드의 출력 슬롯 IMAGE 를 빈 캔버스로 드래그한 뒤, VAE Encode 노드를 추가해줍니다. vae 입력 슬롯은 base 모델 로더의 VAE 출력 슬롯과, LATENT 출력 슬롯은 base KSampler 의 입력 latent 슬롯에 연결해줍니다. 이렇게 하면 기본 img2img 설정은 끝납니다. (아직 denoising 설정은 하지 않았으므로 무조건 1로 입력될 것입니다)
이제 잡음 제거 강도(denoising strength)를 설정할 차례입니다. 간단한 수학이 필요하죠. 먼저 Simple Math 노드를 하나 추가하고 이름을 img2img Denoising Strength로 설정하고 값은 0.75로 설정합니다. Simple Math 노드를 하나더 추가하고(이름은 Total Scheduled Steps 로) 값을 b/a로 둡니다. a 입력 슬롯은 Denoising Strength로 연결하고, b 는 txt2img에서 전체 스텝수에 연결해 줍니다. txt2img 전체 스텝수가 25라면 전체 스텝수는 40이 됩니다. 이 노드에서 출력 슬롯은 base/refiner KSampler (Advanced) 노드의 steps로 입력되도록 합니다.

이제 앞부분 건너뛸 단계를 계산해야 합니다. 또다시 Simple Math 노드를 추가하고 이름을 Skipped Steps로 변경합니다. a는 바로 위에서 만든 Total Scheduled Steps에 연결하고, b는 txt2img 전체 스텝수에 연결하며, 값은 a-b (40-25=15)로 설정해 줍니다. 다음으로 출력슬롯을 base KSampler의 start_at_step에 연결해 줍니다.
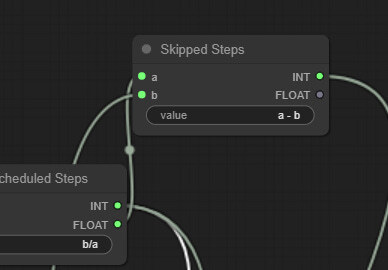
한가지가 더 필요합니다. base KSampler를 언제 끝낼지(refiner KSampler를 언제 시작할지) 계산해야 하죠. 건너뛰는 단계 15, base KSampler 20 이나 35가 되어 합니다. Simple Math 노드를 생성하고 Base Sampler End라고 이름을 수정합니다. Skipped Steps 의 INT출력을 a에 연결하고, b는 Refiner가 시작되는 단계수(Refiner Steps Calculation)에 연결해 줍니다. 출력은 Base KSampler의 end_at_steps와 refiner KSampler의 start_at_steps에 연결해 줍니다. 아래와 같이 연결되면 완성입니다.

이렇게 설정했을 때, denoising 값을 크게할 수록 이미지가 많이 변경되게 됩니다. 예를 들어 1로 설정하면 건너뛰는 스텝이 0이 되기 때문에 잡음 제거를 많이 하게 되는 것입니다. 또 한가지 알아두어야 할 것은, 처음에 잡음을 많이 제거하는 샘플러도 있고, 나중에 잡음을 많이 제거하는 형태의 샘플러 등 다양한 특성에 따라 똑같은 값(예 0.5)라도 denoising 강도가 달라짐에 유의해야 합니다.
아래는 이렇게 해서 만들어진 워크 플로입니다. (제가 만든 게 아니고 원본 글에서 가져온 겁니다)
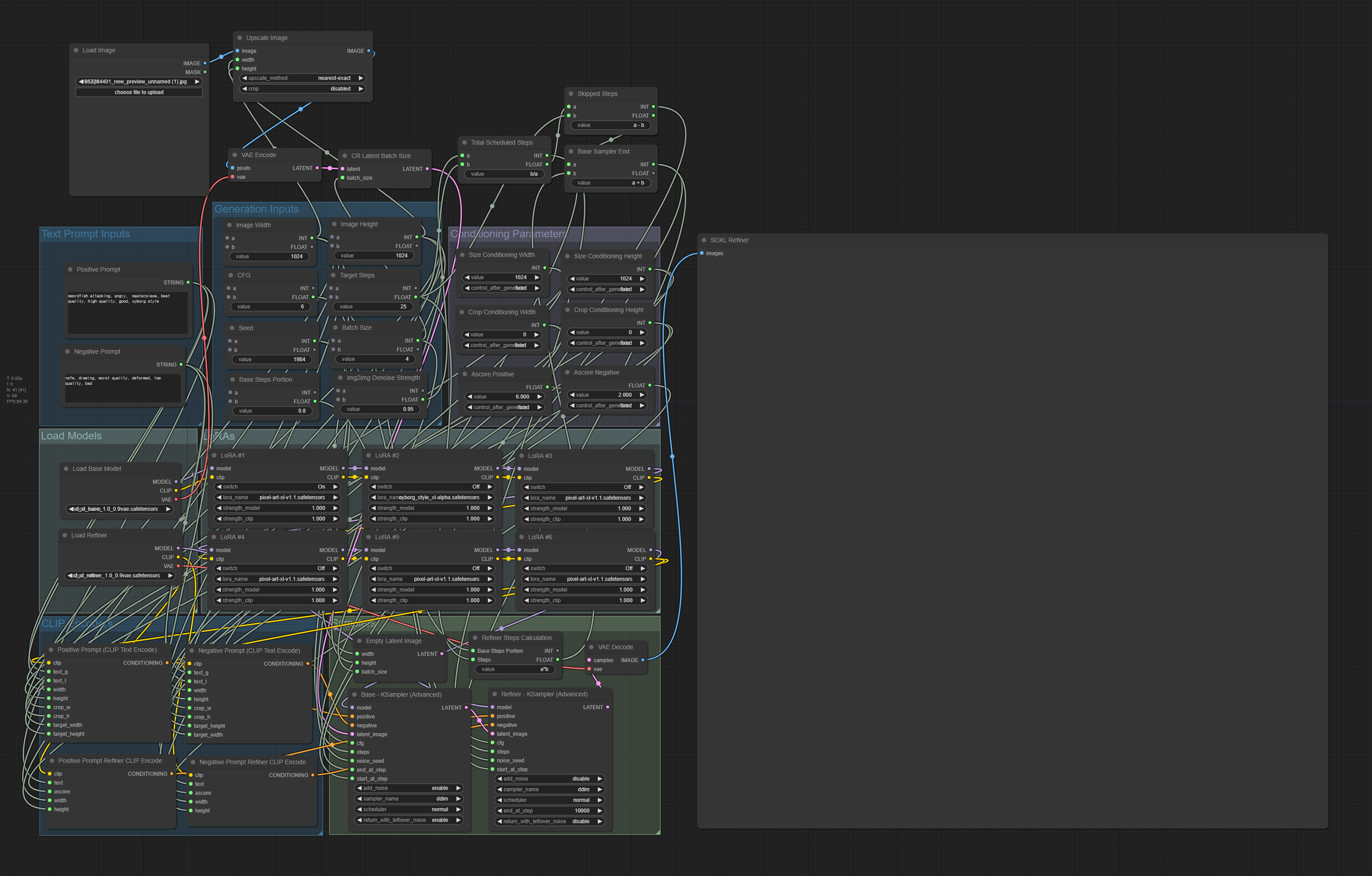
그런데 너무 복잡하네요. 이래서는 사용하는 방법을 익히는 것도 힘들겠네요. ㅠㅠ 일단 이유가 모든 프로세스를 한꺼번에 통합하려는 것때문이 아닌가 싶어요.
원문에는 CannyControlNet을 추가하는 방법도 있는데, 제가 이해가 안되어서 포기해야겠습니다. ㅠ 좀더 고민해보고, 저는 img2img 프로세스를 분리하는 방법을 고려해봐야겠습니다.
이 글은 https://followfoxai.substack.com/p/part-4-advanced-sdxl-workflows-in 를 번역하면서 일부 추가하고 수정하면서 작성하였습니다.
민, 푸른하늘
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기