Text-to-Image(txt2img)는 인공지능 모델을 사용해서 입력된 텍스트(여러개의 단어)를 이미지로 생성해주는 것을 말합니다. txt2img AI 모델은 여러가지가 존재합니다.
- Text-to-image 모델의 작동 원리
- Text-to-image 사용 방법
- 스테이블 디퓨전 txt2img 기본 설정
- txt2img 모델 학습방법
- Text-to-Image 모델의 종류
Text-to-image 모델의 작동 원리
txt2img 모델은 자연어 문장을 입력받아, 그 문장에 맞는 이미지를 생성해주는 신경망(neural network)입니다. 스테이블 디퓨전(Stable Diffusion)및 기타 인공지능 모델에서 입력 자연어 문장을 프롬프트(prompt)와 부정적 프롬프트(negative prompt)라고 합니다.
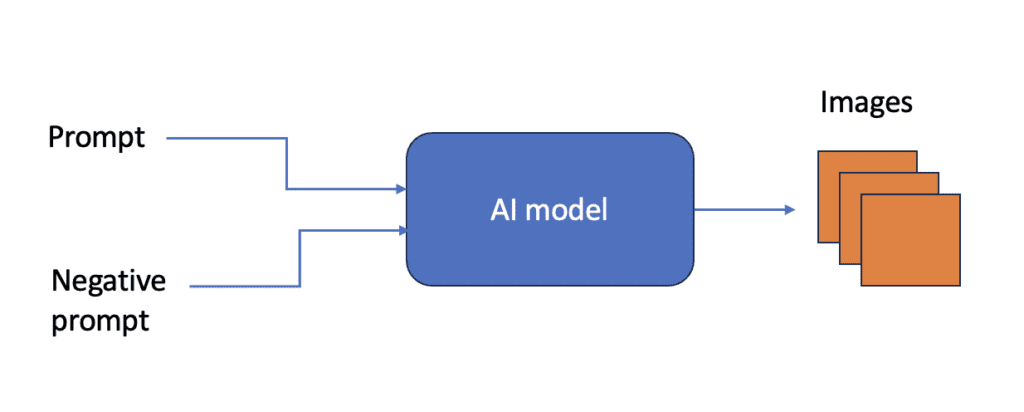
txt2img 인공지능은 확률적이기 때문에 동일한 프롬프트를 입력해도 여러가지 이미지를 생성합니다.
Text-to-image 사용방법
Text-to-Image 는 AI 이미지 생성기의 여러가지 기능중 가장 기본적인 기능입니다. AUTOMATIC1111을 사용할 경우, txt2img 페이지에 들어가면 Text-to-Image 기능을 사용할 수 있습니다. 아래는 "a cat in a hat"이라는 프롬프트를 입력하여 생성한 예입니다.

스테이블 디퓨전 txt2img 기본 설정
스테이블 디퓨전(Stable Diffusion)용 웹 GUI는, AUTOMATIC1111외에도 ComfyUI, Fooocus 등 여러가지가 있지만, 기본 모델이 동일하므로, 기본적인 설정 매개변수는 동일합니다.
- 체크포인트(checkpoint) 모델 : 스테이블 디퓨전을 개발한 Stability AI 사에서 개발한 기본 생성모델 및, 이 기본 모델을 변형한 미세 조정(Fine tuned) 모델을 말합니다. 어떤 체크포인트 모델을 사용하느냐에 따라 생성되는 이미지의 스타일이 많이 달라집니다. 예를 들어, Realisitic Vision 사용하면 사실적인 사진 스타일을 얻을 수 있습니다.
- 프롬프트(Prompt) : 이미지에 나타나게 하고 싶은 것을 서술한 문장
- 부정적 프롬프트(Negative Prompt) : 이미지에 나타나지 않도록 하고 싶은 것을 서술한 문장
- 이미지 크기 : 이미지 크기는 체크포인트 모델에 맞아야 합니다. v1 모델의 경우 512x512가 기본이며, SDXL 모델의 경우 1024x1024 가 기본입니다. 아래는 많이 사용되는 이미지 크기입니다.
| 종횡비 | v1 모델 | SDXL 모델 |
| 1:1 | 512 x 512 | 1024 x 1024 |
| 3:2 | 768 x 512 | 1216 x 832 |
| 16:9 | 910 x 512 | 1344 x 768 |
- 샘플링 방법(Sampling Method) : 디퓨전 프로세스중 이미지의 잡음을 제거하는 데 사용되는 모델. 잘 모르시면 기본 값을 사용하시면 됩니다.
- 샘플링 단계(Sampling Steps) : 잡음제거 프로세스를 적용하는 횟수. 높은 값일수록 좀더 잡음제거 절차가 정확해지고, 따라서 품질이 좋은 이미지가 생성됩니다. 최소한 20 이상으로 지정하는 것이 좋습니다.
- CFG 척도 : 무분류기 척도는 이미지가 입력된 프롬프트를 따르는 정도를 제어합니다.
- 1 - 프롬프트가 거의 무시됩니다.
- 3 - 창의적인 이미지가 생성됩니다.
- 7 - 프롬프트와 창의성간의 균형이 이루어집니다.
- 15 - 프롬프트를 따르는 정도가 높습니다.
- 30 - 프롬프트를 완전히 따릅니다.
txt2img 모델 학습방법
학습 데이터와 학습 방법은 AI 모델 아키텍처만큼이나 중요합니다. 최신 txt2img 모델은 모두 이미지-캡션 쌍으로 구성된 방대한 데이터 세트를 사용해 학습됩니다. 이미지와 캡션간의 상관관계를 학습함으로써 AI 모델은 프롬프트와 일치하는 이미지를 생성할 수 있게 됩니다.
Text-to-Image 모델의 종류
텍스트 프롬프트를 사용해 이미지를 생성하는 Text-to-Image 모델은 스테이블 디퓨전외에도 많습니다. 아래는 이들 중 중요한 txt2img 모델에 대해 알아보겠습니다.
DALL-E
Open AI에서 개발한 DALL-E는 대중의 관심을 많이 받은 최초의 txt2img 모델중 하나입니다. 현재 기준으로 볼 때 그 당시의 이미지 생성은 초보적으로 보이지만, 2021년 출시당시에는 엄청난 혁신이었습니다. 최초로 자연어 설명을 따르는 이미지를 생성할 수 있었기 때문입니다.

DALL-E는 GPT-3와 동일한 모델 아키텍처를 가지고 있습니다. GPT-3는 ChatGPT로 대표되는, Open AI의 대규모 언어모델이죠. 캡션-이미지 쌍은 토큰으로 인코딩되는데, 토큰은 캡션과 함께 해당 이미지의 캡션으로 표현됩니다. 캡션 토큰이 주어지면, GPT-3 모델은 이미지 토큰을 완성한 후, 다시 이미지로 디코딩하게 됩니다.
이름은 비슷한 계열이지만, DALL-E 2 는 DALL-E와 완전히 다른 모델입니다. DALL-E 2는 DALL-E보다 훨씬 작으며, 스테이블 디퓨전과 마잔가지로 디퓨전 기반의 모델입니다. 또한 DALL-E 2 는 이단계 모델로서, 첫번째 모델은 프롬프트에서 이미지 임베딩을 생성하고, 두번째 확산 모델이 이미지 임베딩을 조건부여(conditioning)으로 사용하여 이미지를 생성하게 됩니다.

DALL-E 3는 DALL-E 2 보대 개선된 버전으로서, 프롬프트에 잘 맞는 보다 정확한 이미지를 제공하는 점이 특징입니다. 가장 흥미로운 점은 ChatGPT와 통합한 것으로서, 자연언어를 사용해 이미지를 정제할 수 있습니다.
Imagen
Imagen 은 구글에서 개발한 txt2img 모델로서, 사실적 이미지를 생성해 주는 신경망 디퓨전 모델입니다. Imagen의 모델 아키텍처와 시험 결과는 Chitwan Saharia 등이 저술한 "심층언어 이해를 통한 사실적인 Text-to-Image 확산 모델(Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding)"이라는 논문에 공개되어 있습니다.

Imagen의 주요 설계시 주안점은 아래와 같습니다.
- 고정 언더 모델을 사용한 텍스트 인코딩
- U-Net 구조를 사용한 디퓨전 프로세스 제어
- 무분류기 안내(Classifier-free Guidance)를 사용한 조건부여(conditioning)
이 글을 읽고 스테이블 디퓨전과 비슷하다고 생각하셨다면 아주 잘 맞추신 것입니다. 이 둘은 한가지 차이점 외에는 아키텍처가 매우 유사합니다.
스테이블 디퓨전(Stable Diffusion)

스테이블 디퓨전(Stable Diffusion) txt2img 모델은 가장 유명한 오픈소스 텍스트-이미지 모델입니다. Imagen과 비교를 하면, Imagen이 이미지를 매우 뛰어난 성능을 발휘하지만, 디퓨전 프로세스를 이미지 픽셀 공간(pixel space)에서 돌리기 때문에 훨씬 고사양 컴퓨터가 필요하다는 단점이 있습니다.
스테이블 디퓨전의 가장 혁신적인 점은, 가변 자동 인코더(VAE, variational autoencoder)를 사용하여 이미지를 잠상 공간(latent space)로 인코딩한 후, 이 잠상 공간에서 디퓨전 프로세스를 수행한다는 것입니다. 잠상 공간은 픽셀 공간에 비해 용량이 작기 때문에 스테이블 디퓨전은 Imagen이나 DALL-E 2 보다 훨씬 빠르게 수행됩니다. 사실 스테이블 디퓨전이 유명하게 된것은 왠만한 개인 컴퓨터에서도 이미지를 생성할 수 있기 때문입니다.
미드저니(Midjourney)

미드저니는 이미지 생성 서비스를 제공하는 회사에서 제공하는 독점적인 txt2img 모델입니다. 이 모델의 아키텍처는 그다지 널리 공개되지 않았습니다만, 상당히 뛰어난 이미지를 생성해주는 것으로 유명합니다.
이상입니다. 이 글은 https://stable-diffusion-art.com/text-to-image/ 을 거의 번역하면서 일부분만 수정하여 작성한 글입니다.
민, 푸른하늘
===
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기