
Stable Diffusion XL (SDXL)는 사실적 인물, 영어문장, 다양한 예술 스타일을 아주 훌륭한 구도로 생성할 수 있는 최신 AI 이미지 모델입니다. SDXL은 현재 널리 사용중인 스테이블 디퓨전 v1.5 모델에 비해 훨씬 크고 성능이 뛰어난 버전이라는 의미로 SDXL 이라는 이름을 붙였습니다. (eXtra Large를 줄인 말이 아닐까 싶어요)
Podell 등이 공개한 "SDXL : 고해상도 이미지 합성을 위한 디퓨전 모델 개선(SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis"라는 논문에서 설명한 것처럼, SDXL 은 아래와 같은 여러가지 면에서 v1.5모델보다 훨씬 성능이 뛰어납니다.
- 이미지 품질 향상
- 프롬프트를 잘 이해함
- 미세 디테일을 잘 표현
- 이미지 크기가 커짐
- 영어문장을 잘 표현
- 어두운 이미지를 잘 생성
이 글에서는 다음과 같은 내용을 다룹니다.
- SDXL 모델이 무엇인가
- v1과 SDXL로 생성된 이미지 비교
- AUTOMATIC1111에서 SDXL 을 실행하는 방법
결론적으로 이야기해서 SDXL 모델로 생성한 이미지가 SD1.5 기본모델을 세부 조정한 모델들로 생성한 이미지보다 (적어도 제 눈에는) 품질이 많이 좋습니다. 특히 글씨를 쓰고자 할때에는 SD1.5로는 불가능하고요. 그래서 제 생각엔 SDXL이 SD 1.5 버전을 급격히 대체하지 않을까 싶습니다.
참고로 만약 SDXL을 설치하지 않고 그냥 사용하고 싶다면, Clipdrop 사이트를 추천드립니다. 그리고 이 글에서는 AUTOMATIC1111에서 실행하는 방법만 소개했는데, ComfyUI로 돌리는 것도 좋습니다.
아래는 이 글의 목차입니다.
- SDXL 모델이란?
- SDXL 샘플 이미지
- SDXL 1.0 모델 다운로드 받는 방법
- SDXL 1.0 모델 사용시 참고 사항
- SDXL 모델을 AUTOMATIC1111 에서 실행하기
- SDXL 사전설정 스타일 사용
SDXL 모델이란?
Stable Diffusion XL(SDXL) 은 v1.5 모델에 대한 공식적인 업그레이드로서, 오픈소스 소프트웨어로 공개되었습니다.
SDXL은 매우 용량이 큰 모델입니다. 당연히 품질이 좋습니다. SDXL 모델의 파라미터는 총 66억개로서, v1.5의 9.8억개에 비하면 7배 이상입니다.
SDXL과 v1.5의 차이
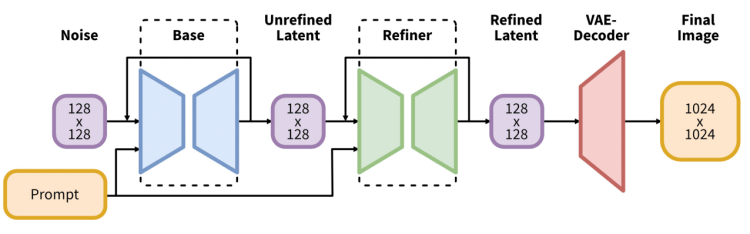
연구논문: https://www.internetmap.kr/entry/SDXL-09-Article-Translation
SDXL은 기본적으로 2개의 모델로 구성되어 있습니다. base 모델을 먼저 수행시키고 refiner 모델을 시행시키는 구조입니다. base 모델은 전체적인 구도를 설정하는 역할을 하며, refiner모델은 보다 자세한 디테일을 추가합니다(base 모델만 사용해되 왠만큼은 괜찮은 이미지가 생성됩니다).
언어 모델(language mode, 프롬프트를 이해하는 모듈)은 가장 큰 OpenClip 모델(ViT-G/14)과 OpenAI의 독점 언어모델인 CLIP ViT-L을 결합하였습니다. 괜찮은 선택이라고 생각합니다. Stable Diffusion v2의 경우 OpenClip만 사용해서 프롬프트를 사용하기 힘들어 외면을 받았거든요. 다시 OpenAI의 CLIP을 사용함으로써 프롬프트 작성이 쉬워졌으며, 아울러 v1.5에서 작동하는 프롬프트를 SDXL에서도 거의 그대로 사용할 수 있습니다.
SDXL 은 새롭게 이미지 크기 조건부여(conditioning)을 추가하여, 256x256 보다 작은 이미지도 학습시켰습니다. v1의 경우엔 512x512 이상의 이미지만 학습시킬 수 있어, 39% 이미지를 사용할 수 없었다고 합니다.
디퓨전 모델에서 가장 중요한 부분이라고 할 수 있는 U-Net은 v1에 비해 3배가 큽니다. 이 때문에(대형 언어모델과 함께) 이미지의 품질이 훨씬 좋아졌고, 프롬프트와 훨씬 가까운 이미지가 생성됩니다.
또한 생성되는 이미지의 기본 크기도 1024x1024로, v1.5의 512x512에 비해 4배 커졌습니다. (생성 시간도 4배 이상인 듯 합니다.ㅠㅠ)
SDXL 샘플 이미지
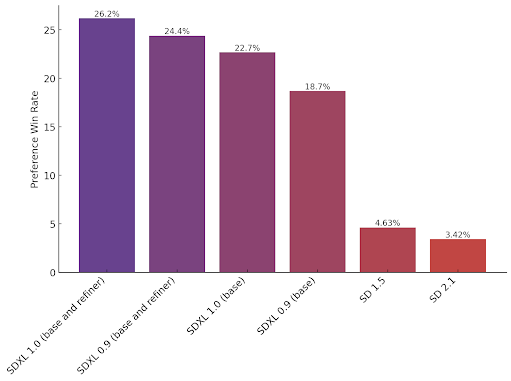
보도자료: https://stability.ai/blog/stable-diffusion-sdxl-1-announcement
Stability AI의 자체 연구에 의하면, 대부분의 사람들이 SD 1.5에 비해 SDXL 을 선호한다고 합니다. 아래에서는 동일한 프롬프트를 사용해 이미지를 비교해 보겠습니다.
사실적인 이미지
아래의 프롬프트는 사실적인 인물 사진을 생성하는 방법에서 사용한 프롬프트입니다.
프롬프트: photo of young Caucasian woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores
부정적 프롬프트: disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
이미지 사이즈: v1.5의 경우 512x512, SDXL 의 경우 1024x1024
기타 다른 설정은 동일합니다. 모델은 기본 모델(v1-5-pruned-emaonly.ckpt)을 사용했습니다.
아래는 SD 1.5 모델로 생성한 이미지입니다.

아래는 SDXL 모델로 생성한 이미지입니다. 좌측은 base모델만 사용하였고, 우측은 base+refiner 모델을 사용한 결과입니다.
 |
 |
| base 모델만 | base+refiner 모델 |
많은 경우, base 모델만 돌렸을 경우 이미지 품질이 떨어져서 refiner를 돌려야 한다고 합니다. 그런데 이 예에서는 base 모델만으로도 괜찮은 이미지가 만들어졌습니다. 디테일은 확실이 좋아졌는데 손이 이상해진건 의외네요.ㅠㅠ
그런데 이렇게 비교하는 것은 문제가 있습니다. 대부분의 경우 v1.5 기본모델을 사용하기 보다는 미세 조정한(fine tuned) 모델을 사용하기 때문입니다. 아래는 URPM 모델로 생성한 결과입니다.

아래도 동등한 설정으로(다른 시드로) 생성한 이미지입니다. 역시나 예쁘게 잘 나옵니다.

아래는 Clipdrop SDXL에서 생성한 이미지입니다. 역시나 잘 생성됩니다. 그런데... SD 1.5에서는 밝은 조명 상태 이미지가 생성되는데, SDXL 은 모두 어둑어둑한 이미지로 생성됩니다. 또한 생성되는 얼굴이 비슷비슷합니다.
 |
 |
그런데.... base 모델이기 때문에 동양인은 좀 약할 듯해서 프롬프트를 "young Caucasian woman"을 " young and beautiful Korean woman"으로 바꿔서 테스트해 봤습니다.
아래는 ChilloutMix 를 사용해 생성한 이미지고요,
 |
 |
아래는 SDXL로 생성한 이미지입니다.
 |
 |
SD 1.5 기본 모델로 생성했을 때보다는 동양 여성을 잘 표현해주는데, ChilloutMix로 생성한 이미지와 비교를 하면 약간 부족하다 싶네요. 그래도 훌륭합니다. 아무것도 추가하지 않고 기본 모델만 사용해서 생성한 이미지임을 고려하면 정말 최고라고 할 수 있겠네요.
읽을 수 있는 글씨
SD 1.5에서는 글자는 전혀 표현할 수 없었습니다. 그런데 SDXL을 사용하면 글씨가 정확하게 쓰여집니다. 아래가 설정입니다.
프롬프트: A fast food restaurant on the moon with name “Moon Burger”
부정적 프롬프트: disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w
아래는 base 모델만 사용해 생성한 이미지입니다.

아래는 refiner 까지 수행한 결과입니다.

제가 보기엔 base 모델만 사용한 이미지만으로도 충분한 정도로 보입니다. refiner를 적용하니 건물 자체는 별로 안변했고 지형은 여기저기 변한게 보이네요.
반면 SD v1.5 기본 모델로 생성해 보면, 글씨를 못쓰는 정도가 아니라, 아얘 이미지가 정상적으로 생성되지 않는 정도네요.
 |
 |
참고로, SDXL 의 경우에도 좀 더 긴 문장의 경우 잘 표현하지 못하는 경우가 많습니다. DALL-E 3와 스테이블 디퓨전 비교의 예에서 알 수 있는 것처럼, 영어 문장을 생성하는 능력은 DALL-E 3에 비하면 한참 모자랍니다.
 |
 |
| DALL-E 3 | SDXL base |
애니 스타일
애니 스타일도 비교해 보겠습니다. 설정은 아래와 같습니다.
프롬프트: anime, photorealistic, 1girl, collarbone, wavy hair, looking at viewer, upper body, necklace, floral print, ponytail, freckles, red hair, sunlight
부정적 프롬프트: disfigured, ugly, bad, immature, photo, amateur, overexposed, underexposed
아래가 결과입니다.
 |
 |
아래는 SD 1.5 기본 모델로 생성한 결과입니다.
 |
 |
아래는 Anything v5로 생성한 이미지입니다.
 |
 |
SDXL 베이스 모델로 생성한 결과가 SD 1.5 기본 모델 뿐만 아니라 세부 조정 모델인 Anything v5보다도 더 나은 결과물을 보이는 것 같네요.
풍경
아래는 "Painting of a beautiful city by Brad Rigney"로 생성한 이미지입니다.
 |
 |
아래는 v1.5 기본 모델로 생성한 결과입니다.
 |
 |
저는 그래도 SDXL 모델이 나은 것 같네요.
SDXL 1.0 모델 다운로드 받는 방법
다음은 SDXL base 모델과 refiner 모델 페이지입니다.
아래는 safetensor 모델을 직접 다운로드 받을 수 있는 링크입니다. 대부분의 경우 VAE파일은 별도로 다운로드 받으실 필요가 없습니다.
AUTOMATIC1111의 경우, 이들 모델을 다운로드 받은 후, stable-diffusion-webui\models\Stable-diffusion 폴더에 넣어주시면 됩니다.
참고로, 하위 폴더도 인식하므로, SD1.5 모델이나 SDXL 모델중 한쪽은 따라 폴더를 생성해서 넣어주시는 편이 찾기 편합니다.
SDXL 1.0 모델 사용시 참고 사항
아래는 Stability AI의 스탭이 공개한 SDXL 1.0 모델에 대한 여러가지 팁을 요약한 것입니다.
- 부정적 프롬프트: 1.5 및 2.0에서 만큼 부정적 프롬프트가 필요 없다고 합니다. 특히 신체 구조에 관한 부정적 프롬프트(extra head, extra legs 등)는 필요없다고 하네요.
- 키워드 가중치: v1 모델처럼 높은 키워드 가중치를 사용할 필요가 없다고 합니다. SDXL에서 가중치를 1.5로 주면 매우 높게 설정되며, 따라서 v1 모델의 프롬프트를 사용시 가중치를 줄여야 한답니다. 특히 SD1.5 용 프롬프트를 가져와서 사용할 경우, 1/2 정도 이하로 내려주시는 게 좋습니다.
- Safetensor: 체크포인트 버전은 위험할 수 있으므로 반드시 Safetensor 버전을 사용하랍니다.
- Refiner 강도: refiner 강도는 낮게 하는게 좋은 결과물을 얻을 수 있다고 합니다.
이미지 크기
이미지 크기: 기본 크기는 1024x1024 이며, 다른 종횡비도 지원은 하는데 품질이 사이즈에 민감하다는 점을 알고 있어야 합니다. 아래는 Stability AI의 공식 이미지 생성기인 DreamStudio 에서 사용된 이미지 크기입니다.
- 21:9 – 1536 x 640
- 16:9 – 1344 x 768
- 3:2 – 1216 x 832
- 5:4 – 1152 x 896
- 1:1 – 1024 x 1024
AUTOMATIC1111의 경우, Aspect Ratio Seletor 확장을 사용하면, 이러한 크기를 외우지 않아서 선택만 하여 지정할 수 있습니다. 이때, 해당 확장의 폴더(stable-diffusion-webui\extensions\sd-webui-ar) 속에 있는 resolution.txt에 아래 몇줄을 추가해주시면 편하게 용할 수 있습니다.
XL1:1, 1024, 1024
XL5:4, 1152, 896
XL3:2, 1216, 832
XL16:9, 1344, 768
XL21:9, 1536, 640이렇게 추가해주면, AUTOMATIC1111에 아래와 같은 형태로 나타나게 됩니다.

SDXL 모델을 AUTOMATIC1111 에서 실행하기
이제 AUTOMATIC1111 웹UI는 기본으로 SDXL 모델을 지원합니다. AUTOMATIC1111이 처음이라면 설치방법에 관한 글부터 읽어보시기 바랍니다.
SDXL 1.0 모델 설치
아래의 SDXL base 모델 및 refiner모델을 다운로드 받아, stable-diffusion-webui\models\Stable-diffusion 에 넣으면 됩니다.
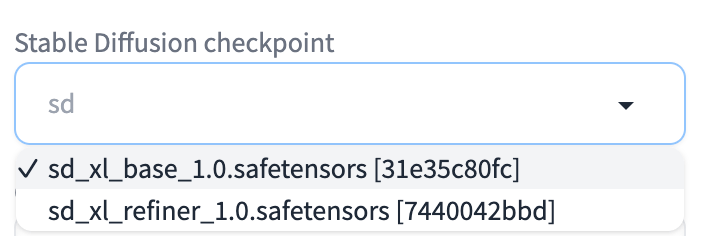
다운로드가 완료되면, 아래의 모델 선택창 오른쪽에 있는 refresh 버튼을 눌러주면 아래와 같이 모델 선택창에서 선택할 수 있습니다.
참고 : 저의 경우에는 이렇게 설치했더니 "SDXL 모델을 설치할 수 없다"는 등의 오류가 발생했습니다. 해결하고자 검색해서 여러가지 방법을 시도했지만 실패했고, 그래서 사용하던 폴더는 그대로 두고 새로 설치를 했습니다. 그랬더니 정상적으로 작동하더군요. 이렇게 새로 설치하였다면 설치후 base 모델과 refiner모델을 해당 폴더에 넣어주면 됩니다.
SDXL base 모델 text-to-image 사용법
SDXL txt2img 사용법은 1.5 버전과 동일합니다. 즉
- Stable Diffusion Checkpoint 드롭메뉴에서 SDXL 1.0 base 모델을 선택(위 그림 참고)
- 프롬프트를 입력한다.(필요시 부정적 프롬프트도 입력)
- 이미지 크기를 1024x1024로 설정 또는 한쪽을 1024로 유지, 또는 위에 있는 팁 참고
중요: v1의 VAE 를 사용해서는 안됩니다. Settings -> Stable Diffusion에서 SD VAE를 Automatic 으로 설정하고 사용하세요.
프롬프트: 1girl ,solo,high contrast, hands on the pocket, (black and white dress, looking at viewer, white and light blue theme, white and light blue background, white hair, blue eyes, full body, black footwear the light blue water on sky and white cloud and day from above, Ink painting
부정적 프롬프트: sketch, ugly, huge eyes, text, logo, monochrome, bad art
이미지 크기: 896x1152
샘플링 스텝수: 20
아래는 base 모델을 사용해 생성된 결과입니다. 그런데... base 모델만 돌려도 괜찮은 이미지가 생성되네요. 기분이 왕~~ 좋네요!!

base+refiner 모델 사용방법
AUTOMATIC1111 1.6.0부터는 refiner 모델을 기본적으로 지원합니다.
Refiner 모델을 사용할 경우, 먼저 Refiner 영역을 열고 아래와 같이 지정합니다.
- Checkpoint : SDXL refiner 1.0 모델을 선택합니다.
- Switch at : 전체 샘플링 단계중에서 언제까지 base 모델을 적용하고, 언제부터 refiner로 전환할지를 지정합니다. 예를 들어 전체 샘플링 단계가 20일때, 아래와 같이 0.8로 지정하였다면, 16단계까지는 base모델을 사용하여 잡음 제거를 하고, 17단계부터는 refiner 모델로 잡음 제거하라고 지정하는 것입니다.

이제 [Generate] 버튼을 누르면 text-to-image가 시행됩니다.
여기에서 가장 중요한 점은 전체 샘플링 단계와 Switch at 값 설정 방법입니다만, 저는 대부분 25단계에 0.8 정도로 지정하면 무방한 것 같습니다. 따로 시험은 하지 않겠습니다.
아래는 base 모델만 돌렸을 때와, base+refiner를 돌렸을 때의 비교입니다. 얼굴과 치마 표현이 달라졌다는 게 눈에 띄네요. 그런데 무엇보다 프롬프트에 있던 "ink painting"이라는 느낌이 더 잘 살아난 듯 합니다. 결국, 프롬프트 대로 잘 표현되도록 하려면 refiner 모델까지 돌려야 할 것 같네요.
|
 |
SDXL 사전설정 스타일 사용
스테이블 디퓨전 모델을 생성하는 공식 프로그램인 DreamStudio에는 여러가지 사전 설정된 스타일 목록이 있습니다. 이러한 스타일은 실제로 프롬프트 혹은 부정적 프롬프트에 해당 키워드를 넣으시면 효과가 발생합니다. AUTOMATIC1111에 StyleSelectorXL 확장을 사용하면 이러한 서전 설정 스타일을 쉽게 확인하고 추가할 수 있습니다.
StyleSelectorXL 확장 설치방법
먼저 AUTOMATIC1111 에서 Extension 페이지로 들어가서 [Install from URL] 탭을 클릭하고 URL란에 아래의 주소를 넣어줍니다.
https://github.com/ahgsql/StyleSelectorXL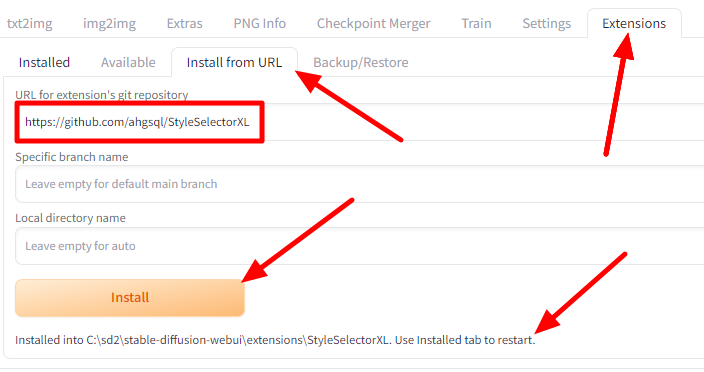
그 다음 [Install] 버튼을 클릭하고 맨아래 "Installed..." 라는 메시지를 확인합니다. 다음으로 [Installed] 탭으로 들어가서 [Apply and restart UI] 버튼을 눌러 AUTOMATIC1111을 다시 시작해 줍니다.
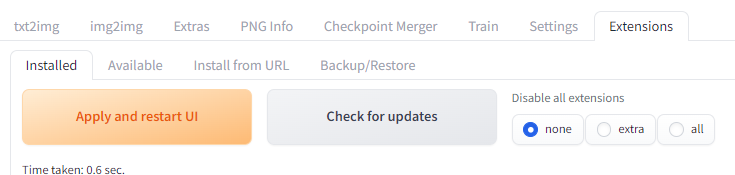
StyleSelectorXL 확장 사용방법
설치를 끝내고 txt2img 페이지에 들어가보면 아래와 같은 부분이 새로 추가되어 있을 것입니다.
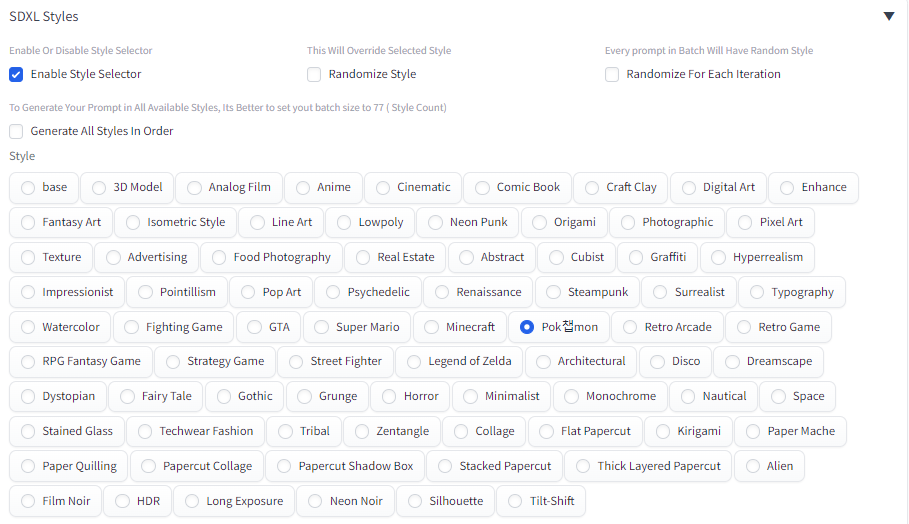
평소처럼 프롬프트와 부정적프롬프트를 작성하고 나서 원하는 스타일을 선택해 선택해주면 됩니다. 아래는 몇가지 예입니다. 프롬프트는 "a cat with a sword and light armor" 이고 씨드번호는 2210410541 입니다.
추가: SDXL 모델 스타일 106가지를 읽어보시면 106가지 종류가 나오도록 바꾸는 방법이 있습니다. 참고하세요.
 |
 |
 |
 |
 |
 |

관련 자료
민, 푸른하늘
이 글은 https://stable-diffusion-art.com/sdxl-model/ 글을 번역하면서 필요에 따라 수정한 글입니다. 아마 30%쯤은 수정했을 것 같네요. ㅎㅎ
- SDXL 개발 관련 논문
- SDXL 테스트 사이트(Clipdrop)
- AUTOMATIC1111 설치 방법
- AUTOMATIC1111에서 SDXL을 사용하는 방법
- 멋진 이미지를 생성하는 SDXL 프롬프트
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - 인페인트 가이드
- Stable Diffusion - 모델에 대한 모든 것
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 만든 이미지