
ESRGAN과 같은 이미지 AI 확대기는 스테이블 디퓨전(Stable Diffusion)으로 생성한 이미지의 품질을 향상시키기 위해 반드시 사용해야 하는 도구입니다. 이 도구는 아주 많이 사용되기 때문에 Stable Diffusion GUI에서 기본으로 제공하는 경우가 많습니다.
이 글에서는 이미지 AI 확대기(Upscaler)가 무엇인지, 작동 원리는 어떠한지, 어떻게 사용할 수 있는지 등을 알아보겠습니다. 이 글의 목차는 아래와 같습니다.
- 이미지 확대 도구가 필요한 이유
- 전통적인 확대 도구의 단점
- 인공지능 확대 도구의 작동 원리
- 스테이블 디퓨전의 AI 확대도구 사용법
- AI 확대도구 종류
- 새로운 Upscaler 설치방법
- Upscaler2
- SD Upscale 스크립트
- txt2img 페이지의 Hires Fix
이미지 확대 도구가 필요한 이유
스테이블 디퓨전 v1.4 및 v1.5의 기본 이미지 크기는 512×512픽셀입니다. 오늘날의 전반적인 상황을 생각했을 때 너무 작습니다. 예를 들어 iPhone 12의 경우, 4,032×3,024픽셀인 12MP 이미지를 생성합니다. 또한 iPhone 12의 화면은 2,532 × 1,170 픽셀까지 지원되므로, 확대기를 사용하지 않을 경우 스테이블 디퓨전으로 생성한 이미지는 화질이 떨어질 수 밖에 없습니다.
문제를 더 복잡하게 만드는 것은 스테이블 디퓨전으로 생성된 복잡한 장면이 선명하지 않은 경우가 많다는 점입니다. 즉, 전반적인 이미지의 형태는 괜찮은 것 같아도, 자세히 들여다 보면 세밀한 디테일이 표현되지 않는 경우가 많다는 것입니다.
전통적인 확대 도구의 단점
전통적으로는 최근린 내삽(nearest neighbor interpolation)과 Lanczos 내삽과 같은 도구를 사용해 이미지를 확대해 왔습니다. 하지만 이러한 도구는 이미지의 픽셀값만을 사용하여 확대를 합니다. 즉, 100x100 이미지를 200x200 으로 확대할 경우, 새로 생성되는 픽셀은 그 주변에 있는 픽셀들 값을 적당히 덧셈/곱셈하여 만들어낸다는 뜻입니다. 그러나, 이러한 방식으로는 누락된 정보를 정확하게 복원하는 것이 불가능합니다.
인공지능 확대 도구의 작동 원리
반면, 인공지능 확대 도구(AI UpScaler),는 방대한 양의 학습된 데이터를 기반으로 픽셀을 생성합니다. 딥러닝 학습과정에는 좋은 품질의 이미지를 학습시키고, 이를 인위적으로 손상시켜 실제 화질 저하를 모방시킨 뒤 학습하는 과정을 반복하게 됩니다. 이러한 과정을 통해 어떠한 이미지에서는 어떤 방식으로 복원시키는 것이 좋은지를 학습하게 되는 것입니디다.
스테이블 디퓨전 모델에는 방대한 양의 사전 지식이 내장되어 있습니다. 이 모델을 사용하면 누락된 정보를 채울 수 있습니다. 이는 사람이 다른 사람의 얼굴을 기억할 때, 눈 코 입 등 각각의 부분을 세세하게 기억할 필요가 없는 것과 비슷합니다. 사람들은 몇가지 주요한 특징만 기억하여 얼굴을 기억하는 방식을 사용합니다.
아래는 기존 확대도구(Lanczos)와 인공지능 확대 도구(R-ESRGAN)를 비교한 예시입니다. AI 확대도구에 내장된 지식을 사용하여, 이미지 크기를 단순하게 키우는 것이 아니라, 디테일까지 복구할 수 있는 것입니다.

스테이블 디퓨전의 AI 확대도구 사용법
아래는 AUTOMATIC1111 GUI에서 AI 확대도구를 사용하는 방법을 설명합니다. AUTOMATIC1111 메뉴 사용법은 여기를 읽어보시기 바랍니다.
먼저 Extra 페이지에 들어가서 Single Image를 선택합니다.
확대하고자 하는 이미지를 선택하고, 확대 비율을 선택합니다. 대부분의 AI 확대도구는 4배를 기본으로 지원합니다. 원본의 크기가 512x512 일 경우, 2배를 선택하면 1024x1024, 4배를 선택하면 2048x2048 이미지가 생성됩니다.
그 아래에 있는 Upscaler1에서는 원하는 확대도구를 선택합니다. R-ESRGAN 4x+, E-ESRAGN, ScuNet GAN 등이 있는데, 효과는 거의 비슷합니다. 저는 R-ESRGAN 4x+를 주로 사용합니다.
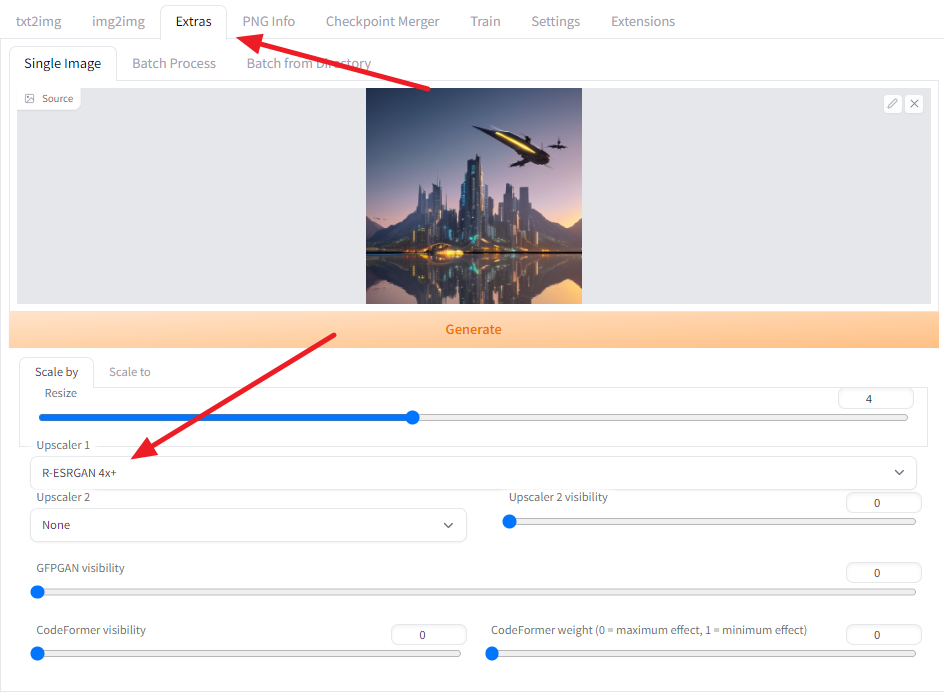
마지막으로 [Generate] 버튼을 눌러주면 확대가 시작됩니다. 작업이 완료되면 output 윈도에 나타나게 되는데, 우클릭하여 저장하면 됩니다.
참고로 이 이미지를 생성하는 데 사용한 프롬프트는 아래와 같습니다.
프롬프트: Hyper-realistic photo, futuristic city, evening sunset, procession of flying cars, reflection of city in lake, mountains in distant background.
아래는 이렇게 4배로 지정해 생성한 이미지를 원본과 비교해 본 것입니다. 원본은 400%로 확대해서 캡처했고, 확대 도구로 생성한 이미지는 100%로 보인 것입니다. 외곽선이 뚜렷해진 것 외에도 특히 창문 속 풍경이 보다 사실적으로 표현되었음을 알 수 있습니다.
 |
 |
AI 확대도구 종류
LSDR
LSDR(Latent Diffusion Super Resolution) 확대 도구는 스테이블 디퓨전 1.4와 함께 출시된 도구로서, 확대 작업 수행을 위해 훈련된 잠재 확산 모델(latent diffusion model)입니다. (잠재 확산 모델은 여기를 읽어보세요) 품질은 매우 좋지만, 확대 작업이 매우 느리다는 단점이 있어서 추천하지 않습니다.
ESRGAN 4x
ESRGAN(Enhanced Super-Resolution Generative Adversarial Networks, 초해상도 생성형 적대적 네트워크)는 2018년 Perceptual Image Restroation and Manipulation 챌린지에서 우승을 차지한 확대용 네트워크입니다. 이것은 이전의 SRGAN 모델을 개선한 것입니다.
ESRGAN은 미세한 디테일을 유지하면서도 선명하고 또렷한 이미지를 생성하는 경향이 있습니다.
R-ESRGAN 4x
R(리얼) ESRGAN은 ESRGAN을 개선한 것으로 다양한 실세계 이미지를 복원하는 데 사용할 수 있습니다. 카메라 젠즈 왜곡 및 디지털 압축 등으로 인한 다양한 왜곡을 모델링합니다.
R-ESRGAN은 ESRGAN에 비해 부드러운 이미지를 생성하는 경향이 있으며, 사실적인 사진 이미지에서 가장 뛰어난 성능을 발휘합니다.
R-ESRGAN-4x+-Anime6B
R-ESRGAN과 특성이 비슷하지만, 특히 애니메를 잘 처리한다고 합니다.
기타
기타 SwinIR 4x, ScuNET GAN, ScuNET PSNR 등도 있지만, 이에 대한 설명은 생략합니다. 대신 이 글을 들어가보시면 여러가지 확대 도구에 대한 비교를 보실 수 있습니다.
또한 여기에 드롭다운으로 사용할 수 있는 확대도구 외에 다른 도구를 사용하고 싶을 경우, Open 모델 데이터베이스에 들어가면 여러가지 Upscaler를 찾아볼 수 있습니다.
새로운 Upscaler 설치방법
새로운 Upscaler(AI 확대도구)를 설치하려면, 모델을 다운로드 받아 아래의 폴더에 넣어주면 됩니다.
stable-diffusion-webui\models\ESRGAN
다운로드가 끝나면 GUI 만 새로고침(F5)해주면 됩니다. 이제 Upscaler 드롭다운 메뉴에 들어가보면 새로 설치한 모델을 볼 수 있습니다.
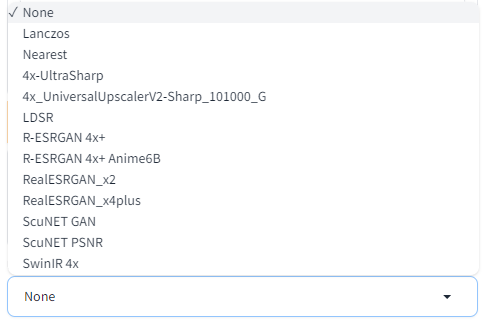
아래는 일반적으로 널리 사용되고 있는 upscaler입니다.
UpScaler 2
UpScaler 2를 UpScaler와 함께 사용하면 두가지 확대 도구의 효과를 한꺼번에 얻을 수 있습니다. 예를 들어, UpScaler 1에는 R-ESRGAN 4x를 사용하고 UpScaler 2에는 SwinIR 4x 를 사용하면 SwinIR이 약간 부드러운 이미지를 생성하는 경향이 있으므로 최종 결과물이 조금 부드러워진다고 합니다.
예를 들어 아래는 UpScaler 2에 SwinIR-4x를 선택하고, Upscaler 2 visibility를 1로 설정하여 수행한 결과입니다. 뭐... 제 막눈으로는 색이 좀더 선명해진 느낌이 들고 부드려워졌다는 느낌은 별로 없네요. 그래도 오른쪽이 더 마음에 드는 것도 사실이네요. ㅎㅎ
|
 |
참고로, 이때 확대 비율을 4로 설정해 뒀으니까, R-ESRGAN으로 4배, SwinIR로 4배 해서 총 16배 확대되는 게 아닐까 하고 생각할 수 있는데, 그렇지 않습니다. 그냥 4배로 생성되면서 다만 내부적으로 두가지 확대도구를 돌려 합쳐주는 거라고 합니다.^^
아래는 원본과 위에서 생성한 마지막 사진을 비교해 본 것입니다. 클릭하면 원본이 나오니 비교해 보세요.
 |
 |
SD Upscale 스크립트
지금까지 설명드린 방법은 이미지를 생성한 후, 다시 Extra 페이지에 들어가서 이미지를 확대하는, 2단계로 이미지를 생성해야 합니다.
SD Upscale은 이와 달리, image-to-image 를 적용한 결과물에 확대 연산을 적용하는 스크립트입니다. 다음과 같이 사용할 수 있습니다.
1. img2img 페이지로 들어갑니다.
2. 캔버스에 이미지를 업로드한다(방금전 생성한 이미지가 있을 경우, 이미지 아래에 있는 Send to Img2Img 버튼을 누르면 됩니다)
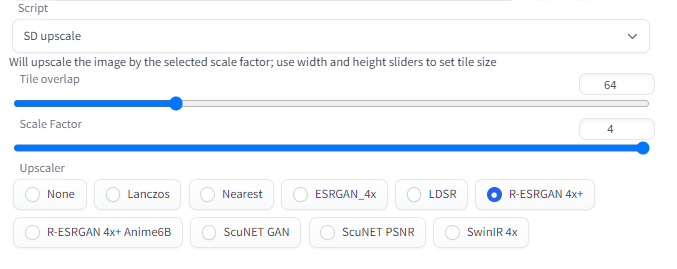
3. Script 드롭다운에서 SD Upscale을 누릅니다.
4. 다음과 같이 설정합니다.
- Scale factor : 4 (4배)
- Denoising strength : 0.1 ~ 0.3 (높은 값을 입력할 수록 이미지가 많이 변형됨)
- Sampling steps: 100
5. 적당한 프롬프트를 입력합니다. 변경할 내용이 없다면 "highly detailed"만 입력하면 됩니다.
6. [Generate] 버튼을 누른다.
이 방법을 따라해보시면서 느끼시겠지만, 이것은 기본적으로 img2img로 생성한 이미지를 확대하는 방법입니다. 아래는 위에서 사용한 방법(R-ESRGAN + SwinIR)과 여기에서 설명한 SD Upscaler 방법을 비교해본 것입니다. 제 생각에Extra 탭에 있는 확대 도구를 사용하는 것과 그다지 차이도 별로 없는데, 구지 이렇게까지 해야 하나 싶네요.
 |
 |
txt2img 페이지의 Hires Fix
이것은 txt2img로 생성하는 이미지를 바로 확대하고 싶을 때 사용하는 방법입니다. 그냥 txt2img 페이지의 Sample method 아래에 있는 Hires. fix를 누르면 아래에 확대관련 메뉴가 추가되는데, 여기에서 Upscaler(확대 도구 종류)와 Upscale by(확대 비율) 정도를 선택한 뒤, 나머지는 일반적인 txt2img 방식에 따라 이미지를 생성하면 됩니다.

하지만, 저는 이런 방식을 별로 좋아하지 않습니다. 안그래도 꼬진 컴퓨터라서 속도가 느린데, 이것까지 해두면 속도가 더 늦어지니까요.
대신 영상을 쭉 생성한 뒤 마음에 드는 게 생성되면 그것만 맨위에서 설명한 확대도구를 사용하는 게 훨씬 효율적이라고 생각합니다.
이상입니다.
===
이 글은 Andrew님의 글 첫번째을 나름대로 정리한 글입니다. 이 방법외에도 더 복잡한 방법도 있기는 한데, 기본적으로 저는 AI 확대도구를 좋아하지 않아서 이 정도면 충분할 것 같네요.
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - 인페인트 가이드
- Stable Diffusion - 모델에 대한 모든 것
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기