스테이블 디퓨전이 어떻게 작동되는지에 대해서도 조금 알게되었고, Stable Diffusion의 대표 UI라고 할 수 있는 AUTOMATIC1111을 설치하였으며, 기본적인 사용법은 시험해 봤고, LoRA와 ControlNet도 돌려본 상태라면, 이제 Stable Diffusion을 사용해서 왠만한 정도의 사진이나 그림을 뽑아낼 수 있을 것입니다.
이 글은 이러한 기본을 뛰어 넘어 한 단계의의 기술인 하이퍼네트워크(Hypernetwork) 모델에 대한 글입니다. 이 글에서는 하이퍼네트워크가 무엇인지, 어떻게 사용하는지에 대해 설명합니다.
하이퍼네트워크란?
하이퍼네트워크는 Novel AI에서 처음 개발한, 미세 조정 기법입니다. Novel AI는 Stable Diffusion이 처음 공개된 때부터 개발에 참여해왔던 얼리 어댑터라고 할 수 있죠. 하이퍼 네트워크는 Stable Diffusion 부착하여 스타일을 변경시키는 데 사용할 수 있는 작은 신경망입니다.
하이퍼네트워크는 Stable Diffusion 모델중 매우 중요한 부분인, 잡음 예측기 UNet의 교차 인지(cross-attention) 모듈에 삽니다. LoRA 모델도 교차인지 모듈을 수정하지만, 둘이 작동하는 방식은 다릅니다.
하이퍼네트워크는 일반적으로 간단한 신경망으로서, 드롭아웃(dropout)과 활성화(activation)이 있는 완전히 연결된 선형 네트워크입니다. 신경망 입문 과정에서 소개하는 것처럼, 두 개의 네트워크를 삽입하여 키(key)와 쿼리(query) 벡터를 변환함으로써 교차 인지 모듈을 가로채는 것입니다. 아래 그림은 원래의 교차인지 모듈과 하이퍼네트워크가 끼어든 교차인지 모듈 아키텍처입니다.
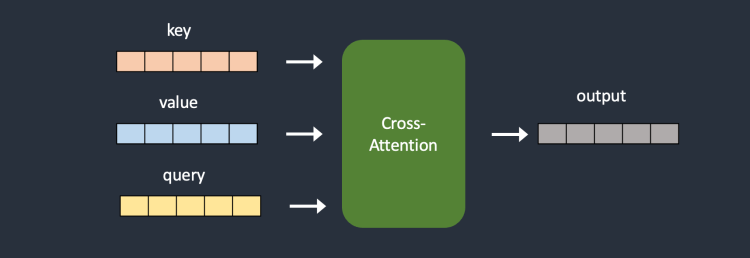

학 중에는 스테이블 디퓨전 모델이 잠겨 있지만 하이퍼네트워크는 변경시킬 수 있습니다. 하이퍼네트워크가 크기가 작기 때문에 훈련 속도가 빠르며 리소스가 그다지 많이 소요되지 않습니다. 따라서 일반 컴퓨터에서도 학습을 수행할 수 있습니다. 이처럼 파일 크기가 작고 훈련 속도가 빠르다는 점이 하이퍼네트워크의 가장 중요한 장점입니다.
참고로, 스테이블 디퓨전의 하이퍼네트워크는 머신 러닝에서 일반적으로 알려진 하이퍼네트워크와 동일하지 않습니다. 일반 하이퍼네트워크는 다른 네트워크에 가중치를 생성하는 네트워크입니다.
다른 모델과의 차이점
체크포인트 모델
체크포인트 모델은 이미지 생성에 필요한 모든 정보가 포함되어 있는 모델입니다. 따라서 대부분 파일의 크기가 매우 큰 편으로 대략 2~7GB 정도입니다. 하이퍼네트워크는 일반적으로 200MB 미만입니다.
체크포인트 모델에는 모든 정보가 담겨있어, 단독으로 이미지를 생성할 수 있지만, 하이퍼네트워크는 단독으로 사용할 수 없고, 체크포인트 모델과 함께 사용해야 합니다.
체크포인트 모델은 하이퍼네트워크보다 더 강력하며, 하이퍼네트워크보다 스타일을 훨씬 더 잘 저장할 수 있습니다. 체크포인트 모델을 학습시키면 전체 모델이 미세 조정되는데 비해, 하이퍼네트워크를 학습시키면 하이퍼네트워크만 미세 조정됩니다.
LoRA 모델
여기서 비교하는 모든 모델중, LoRA 모델이 하이퍼네트워크와 가장 유사합니다. 둘 다 크기가 작고 교차 인지(cross-attention) 모듈만 수정합니다. 다만, 모듈을 수정하는 방식은 차이가 있습니다. LoRA 모델은 가중치를 변경하여 교차 인지 모듈을 수정하는 반면, 하이퍼네트워크는 네트워크를 추가로 삽입하여 교차 인지 모듈을 수정합니다.
사용자는 일반적으로 LoRA 모델이 더 나은 결과를 생성한다고 생각합니다. 파일 크기는 일반적으로 200MB 미만으로 비슷하며 체크포인트 모델보다 훨씬 작습니다.
LoRA는 데이터 저장 방식입니다. 학습 프로세스는 별도로 정의되지 않고, 드림부스를 사용할 수도, 다른 학습을 사용할 수도 있습니다. 이에 비해 하이퍼네트워크는 정해진 학습 방법이 정의됩니다.
임베딩(Embeddings)
임베딩은 텍스트 인버전(textual inversion)이라는 미세 조정 방법의 결과입니다. 텍스트 인버전은 하이퍼네트워크와 마찬가지로 모델을 변경시지 않습니다. 단순히 특정 스타일을 달성하기 위해 새로운 키워드를 정의할 뿐입니다.
텍스트 인터전과 하이퍼네트워크는 스테이블 디퓨전 모델에서 작동하는 위치가 다릅니다. 텍스트 반전은 텍스트 인코더(text encoder)에 새로운 임베딩을 생성합니다. 이에 비해 하이퍼네트워크는 잡음 예측기(noise predictor)의 교차 인지 모듈에 작은 네트워크를 삽입합니다.
하이퍼네트워크를 다운 받는 곳
가장 좋은 곳은 civitai.com입니다. 아래 그림과 같이 깔대기 모양의 필터(filter)아이큰을 클릭한 후, Hypernetwork을 클릭하면 하이퍼네트워크 모델만 볼 수 있습니다.

하이퍼네트워크 사용방법
아래 방법은 스테이블 디퓨전의 대표 UI인 AUTOMATIC1111 에서 hypernetwork를 사용하는 방법입니다.
1. 하이퍼네트워크 설치
하이퍼네트워크를 다운로드 받은 후, 아래의 폴더에 넣어주면 됩니다.
stable-diffusion-webui/models/hypernetworks
2. 프롬프트에 넣기
하이퍼네트워크를 사용할 때에도 LoRA를 사용할 때와 비슷한 방식으로 아래와 같이 프롬프트에 지정하면 됩니다.
<hypernet:filename:multiplier>
여기서 filename은 하이퍼네트워크 파일의 파일명입니다(확장자 제외). multiplier는 하이퍼네트워크에 대한 가중치입니다. 1이 기본 값이고, 작아질 수록 영향이 줄어듭니다. 0으로 지정하면 해당 모델을 사용하지 않게됩니다.
이런 내용을 직접 입력할 필요없이 UI에서 직접 지정할 수 있습니다. 먼저 [GENERATE] 버튼 바로 아래에 있는 팔광 화투패 모양의 아이콘(모델 버튼)을 누르고...

hypernetwork이라고 쓰여진 탭을 선택한 뒤, 원하는 모델을 지정하면 위에 써둔 형태로 프롬프트에 지정됩니다.

3. 사용상 유의점
하이퍼네트워크를 사용하여 하는 스타일을 얻을 확률을 높이려면, 하이퍼네트워크를 학습할 때 사용한 모델과 함께 사용해야 합니다. 또한, 일부 하이퍼네트워크는 특정 프롬프트를 입력해야 작동하거나, 특정한 객체에 대해서만 작동하므로, 모델 페이지에서 프롬프트 예시를 확인하여 어떻게 사용했는지를 확인해 보는 게 좋습니다.
전문가 팁을 알려드리자면, 이미지가 너무 채도가 높아 보인다면(색이 튀는 것 같다고 느껴지면) 배율을 낮춰보는 게 좋습니다. 스테이블 디퓨전은 때때로 채도를 높이는 게 완벽한 방법이라고 해석하는 경우가 있으니, 배율을 낮추면 균형을 되찾는 데 도움이 될 수 있습니다.
하이퍼네트워크 예제
Water Elemental
워터 엘리멘탈은 무엇이든 물로 바꿀 수 있는 매우 독특한 하이퍼네트워크입니다! 트리거 키워드는 water elemental 입니다. 즉, 프롬프트를 입력할 때 바꾸고자 하는 대상 앞에 "water elemental"이라는 문구를 사용하면 효과가 발휘됩니다. 이 하이퍼네트워크는 스테이블 디퓨전 v1.5와 함께 사용할 수 있습니다. (정확히는 1.4 혹은 1.5를 기반으로 한 모델이라면 어떤 모델과 함께라도 사용할 수 있다고 합니다.) 가중치를 조정하면 물 효과를 조정할 수 있습니다.아래의 페이지에 들어가면 가중치는 0.55~1.0 정도가 좋다고 하는데, 0.7 정도가 잘 작동된다고 합니다. 그리고 샘플러는 DPM++ SDE Karras, 샘플링 단계는 15, CFG는 7.0으로 설정하라고 합니다.
그리고... 반드시 배경을 설명하라고 합니다. "an old water elemental man"과 같이 배경 없이 사용하면 배경이 아주 재미없게 만들어진다고 하네요.
Water Elemental 페이지 : https://civitai.com/models/1399/water-elemental

아래는 사용한 프롬프트와 결과물입니다. 모델은 ChilloutMix를 사용했습니다. 그런데 배경 관련 프롬프트를 약간씩 바꿔봐도 busy street는 아무런 효과가 없네요. 아마도 wings, framing hair 키워드가 너무 강력해서 그런 게 아닐까 싶습니다.
an beautiful water elemental asian woman, wings, flaimg hair, in busy street <hypernet:waterElemental_10:0.7>
 |
 |
 |
아래는 거리에서 춤추는 비보이입니다. 관중은 별로 마음에 안드네요. ㅠㅠ
water elemental B-boys, dancing in busy street, enthusiastic crowd <hypernet:waterElemental_10:0.7>
 |
 |
InCase 스타일
InCase 스타일은 Anything v3 모델과 함께 사용해서, Anything v3 모델에 포함된 애니메 스타일을 좀더 성숙한 여인 스타일로 만들어집니다.
InCase 하이퍼네트워크 모델 페이지 : https://civitai.com/models/5124/incase-style-hypernetwork
Anything v3 모델 페이지 : https://huggingface.co/Linaqruf/anything-v3.0
Anything v4.5 모델 페이지 : https://huggingface.co/andite/anything-v4.0/blob/main/anything-v4.5.ckpt
모델 페이지에는 Anything v3와 함께 사용하라고 했지만, 저는 이미 anyghint v4.5 가 있는 상태라서 구지 새로 깔 필요는 못느껴서 그냥 Anything v4.5 체크포인트 파일을 사용해서 테스트 해봤습니다. 아래는 프롬프트와 결과입니다. 원래의 글에 있는 얼굴과는 약간 다르긴 하지만 그래도 원하는 느낌은 그대로 나오네요.
프롬프트: detailed face, a beautiful woman, explorer in forest, white top, short brown pants, hat, sky background, realism, small breast <hypernet:incaseStyle_incaseAnythingV3:1>
부정적 프롬프트: moon, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur, distorted face, blurry, draft, grainy, large breast
 |
 |
 |
SXZ Smol
애니메이션 캐릭터를 앙징맞은 형태 표현하는 하이퍼네트워크입니다. 이 하이퍼네트워크도 Anythig v3를 기반으로 학습시켰다고 해서 한번 시험해 봤습니다. 아래에 있는 이미지중 위는 <hypernet:sxzSmol_sxzSmol:1>를 뺀 상태이고, 아래는 넣은 상태입니다. 위 아래 모두 원래의 배트맨과 아이언맨 캐릭터가 완벽하게 살아있는 것은 없고, 여기저기 짜붙이기한 느낌이네요.
프롬프트 : masterpiece, batman and ironman fighting each other on a dark background with lightnings behind him, thick black outline <hypernet:sxzSmol_sxzSmol:1>
부정적 프롬프트 : (bad_prompt_version2:0.7), low quality, close up, old, lowres, text, error, (cropped:1.2), worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, black and white, monochrome, censored, (out of frame:1.3)
 |
 |
 |
 |
===
이상입니다. 이 글은 Andrew 님의 글을 제 마음대로 바꿔쓴 글입니다. 아마도 20%정도 고친 정도이지 않을까 싶네요.
그런데, 이미지를 생성하는 입장에서는 텍스트 인버전이나, LoRA나, 하이퍼네트워크나 별로 차이가 안느껴집니다. 새로운 원하는 스타일을 만드는 여러가지 방법일 뿐인 듯 싶거든요. 좀더 공부하다보면 어떤 것은 어떤 걸 사용하는 게 가장 효율적인지 알 수 있게 되겠죠.
민, 푸른하늘
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - 인페인트 가이드
- Stable Diffusion - 모델에 대한 모든 것
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기