
인공지능 이미지 고유사이트를 돌아다니면서 만난 멋진 이미지를 따라 해보는 등 스테이블 디퓨전으로 이런 저런 이미지를 생성하다보면, 자신이 좋아하는 대상을 이미지로 표현해보고 싶은 욕구가 생기기 마련입니다. 우리집 멍뭉이, 내가 가지고 있는 피규어, 내가 이번에 산 책 등을 이미지로 표현하는 거죠.
이렇게 어떤 피사체를 이미지로 표현하기 위해서는 먼저 해당 피사체를 학습시켜 모델을 만들어야 합니다. 일반적으로 체크포인트 모델을 학습시키는 것이 가장 확실하지만, LoRA, 하이퍼네트워크, 텍스트 인버전 등을 학습시키는 방법도 존재합니다. 체크포인트는 모든 피사체의 모든 부분을 다 학습시키지만, 나머지는 인공지능 모델 중 일부만 학습시키는 방법입니다. 자세한 내용은 스테이블 디퓨전 기본 이론을 읽어보시기 바랍니다.
그런데 DreamBooth는 기존의 다른 방법과는 많이 다른 것 같습니다. 간단히 요약하면, 기존의 체크포인트 파일에 원하는 피사체 사진 4-5장 정도만 넣고 그 피사체에 유일한 식별자만 부여하면 간단하게 그 피사체에 특화된 모델을 생성할 수 있고, 이 모델을 사용할 때 유일 식별자를 사용하면, 해당 피사체가 어떠한 배경, 환경, 맥락에도 부드럽게 녹아드는 이미지를 생성할 수 있다는 겁니다.
예를 들면, 자신이 유명인과 함께 촬영한 셀카라든지, 반려견의 다양한 모습을 생성할 수도 있습니다. 일반 모델을 생성하면 그저 예쁜, 잘 어울리는 이미지만 골라서 사용하게 되는데 DreamBooth를 사용하면 누구든지 사진 촬영 부스(스티커 사진기)에서 배경을 바꿔가며 사진을 촬영하듯 이미지를 만들어 낼 수 있다는 것입니다.
그런데 저는 이런 응용보다 광고촬영에서 정말 유용하게 사용할 수 있지 않을까 싶습니다. 어떤 새로운 제품에 대한 홍보사진을 제작할 때, 다양한 환경(비올때, 눈올때, 해수욕장, 밀림, 히말라야, 복잡한 도심)에 있는 제품 사진을 마음대로 만들어 낼 수 있고, 심지어는 실사사진 뿐만 아니라, 판타지, 3D 모델링, 유명 화가 분위기 등등 원하는 어떤 모습도 연출할 수 있으니까요. 물론 이 때문에 사진사의 역할과 디자이너의 역할이 많이 줄어들 것 같습니다만...
무엇보다 일반적으로 인공지능 학습에는 수많은 사진을 입력해야 했는데 DreamBooth는 4-5장 만으로도 충분하다는 것이 매력이 아닐까 싶습니다. 간단하게 사용법만 익히면 쉽게 모델을 제작할 수 있으니 누구나 쉽게 응용할 수 있을 것 같다는 생각입니다.
다만, 현재 DreamBooth는 하나의 피사체만 넣을 수 있다는 한계가 있습니다. 예를 들어 앙코르와트에 있는 독사진은 만들어 낼 수 있어도 가족사진은 만들 수 없다는 것입니다. 머... 앞으로 한꺼번에 여러가지 피사체를 학습시키는 방법도 금방 나오지 않을까... 싶습니다만...
아래 글은 https://dreambooth.github.io/ 에 있는 DreamBooth 소개글을 번역한 것입니다. 제가 인공지능 관련 지식이 부족해서 약간 잘못된 내용이 있을 수 있습니다. 감안하시고 읽으시기 바랍니다. 이 사이트에는 해당 논문도 다운로드 받을 수 있으니, 제 능력을 초과하는지라 생략했습니다.
민, 푸른하늘
DreamBooth: 피사체 중심 생성을 위한 text-to-image 확산모델 미세조정
(Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation)
- Google Research

DreamBooth는 사진촬영 부스와 비슷하지만, 피사체를 확보만하면, 꿈이 이끄는 곳 어디든 합성할 수 있습니다...
요약
대규모 텍스트-이미지 모델은 텍스트 프롬프트에서 고품질의 다양한 이미지를 합성할 수 있어, 인공지능 분야 발전에 괄목할 만한 발전을 가져왔습니다. 그러나 이러한 모델은 주어진 참조 자료에 들어 있는 피사체의 모습을 모방하거나, 다양한 맥락에서 피사체를 새롭게 표한하여 합성하는 기능이 부족합니다. 이 연구에서는 텍스트-이미지 확산모델을 '개인화' (사용자의 요구에 맞게 맞춤화)할 수 있는 새로운 접근 방식을 제시합니다. 이 기법을 사용할 경우, 피사체 이미지 몇 장만 입력하면, 사전 학습된 텍스트-이미지 모델(Imagen, 하지만, 특정 모델에 국한되지 않음)을 미세 조정하여 특정 피사체와 고유 식별자를 결합하는 방법을 학습합니다.
피사체가 모델의 출력 영역에 포함되면, 고유 식별자를 사용하여 다양한 장면에서 그 맥락에 맞는 완전히 새로운 사실적 사진 이미지를 합성할 수 있습니다. 새로운 자동적 클래스별 prior preservation loss와 함께 모델에 내장된 시맨틱을 활용함으로써, 이 기법은 참조 이미지에는 없는 다양한 장면, 포즈, 뷰 및 조명 조건에서 피사체를 합성할 수 있습니다. 이 기법은 피사체의 주요 특징을 보존하면서도, 피사체 재맥락화, 텍스트 가이드 뷰 합성, 외관 수정, 예술적 렌더링 등, 이전에는 불가능했던 다양한 작업에 적용가능합니다.
배경
시계(아래 왼쪽의 입력 이미지)와 같은 특정 피사체가 주어졌을 때, 최첨단 텍스트-이미지 변환 모델을 사용하더라도 주요 시각적 특징을 충실하게 유지하면서 다양한 맥락에 맞게 생성하는 것은 매우 어려운 작업입니다. 시계의 모양에 대한 자세한 설명이 포함된 텍스트 프롬프트("retro style yellow alarm clock with a white clock face and a yellow number three on the right part of the clock face in the jungle")를 수십 번 반복해도 Imagen 모델[Saharia 외, 2022]은 주요 시각적 특징을 재구성하지 못합니다(세 번째 열). 또한, 텍스트 임베딩이 언어-시각을 공유하는 공간에 위치하여 이미지의 의미적 변형을 생성할 수 있는 모델(예: DALL-E2 [Ramesh et al., 2022])도 주어진 피사체의 모습을 재구성하거나 문맥을 변경시킬 수 없습니다(두 번째 열). 이와 대조적으로, 우리의 접근 방식(오른쪽)은 새로운 문맥("정글에 있는 [V] 시계")에서 높은 충실도로 시계를 합성할 수 있습니다.

접근 방법
이 방법을 사용하면 피사체(예: 특정 개)의 이미지 몇 장(실험 결과 일반적으로 3~5장이면 충분함)과 해당 클래스 이름(예: '개')을 입력 받아, 피사체를 나타내는 고유 식별자를 인코딩하는 미세 조정된('개인화된') 텍스트-이미지 변환 모델을 생성할 수 있습니다. 그 후, 이 고유 식별자를 문장에 삽입하여 추론하면,서로 다른 문맥에서 피사체를 합성할 수 있습니다.
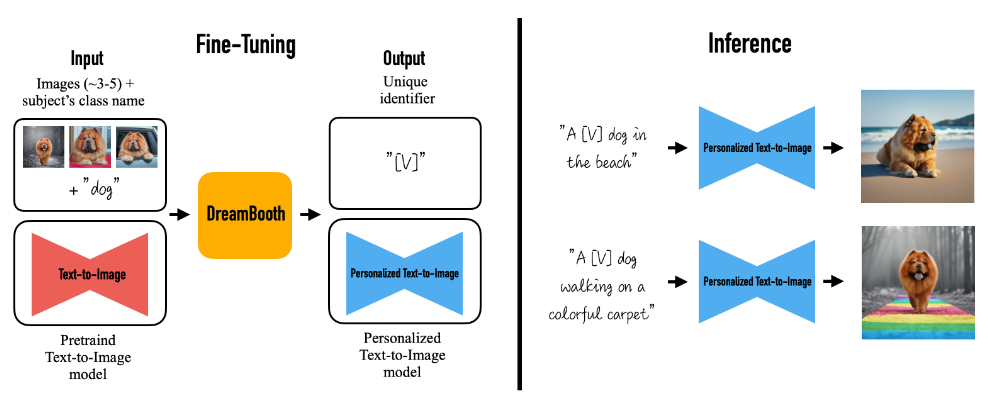
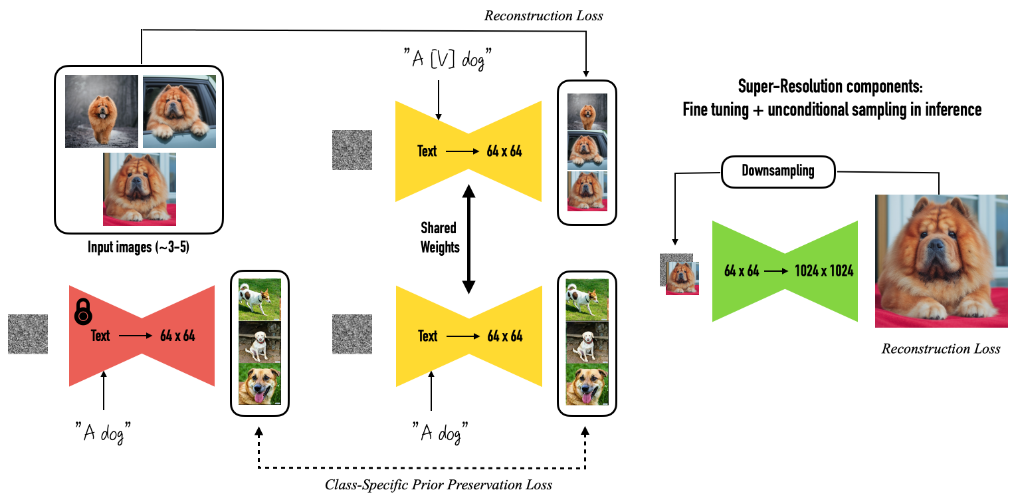
DreamBooth는 주어진 3~5개의 피사체 이미지를 사용하여, 두 단계로 텍스트-이미지 디퓨전 모델을 미세 조정합니다: (a) 고유 식별자와 피사체 클래스 이름이 포함된 텍스트 프롬프트(예: "A photo of [T] dog")와, 이에 대응되는 입력 이미지를 사용해 저해상도 텍스트-이미지 모델을 미세 조정하는 동시에, 클래스별 prior preservation loss를 적용하여 모델에 포함되어 있는 해당 클래스에 대한 기존의 시맨틱을 활용하여, 텍스트 프롬프트에 클래스 명에 삽입함으로써(예: "A photo of a dog"), 해당 피사체 클래스에 속하는 다양한 인스턴스를 생성하도록 합니다. (b) 입력 이미지 세트에서 가져온 저해상도 및 고해상도 이미지 쌍을 사용하여 초고해상도 구성 요소를 미세 조정하여 피사체의 미세한 디테일까지 높은 충실도를 유지할 수 있도록 합니다.
결과
아래 그림은 선글라스, 가방 등의 피사체 인스턴스의 재맥락화 결과입니다. DreamBooth 기법을 적용하여 모델을 미세조정함으로써, 다양한 환경하에서 피사체 디테일이 잘 보존되고 배경과 피사체 간의 상호 작용이 뛰어난 다양한 이미지를 생성할 수 있었습니다. 각 이미지 아래에는 조건 부여 프롬프트가 표시되어 있습니다.





예술적 렌더링
피사체 멍뭉이를 유명 화가의 스타일로 표현했습니다. 한가지 지적하고 싶은 것은 반 고흐와 워홀 렌더링의 결과에서 볼 수 있는 것처럼, 생성된 포즈 중 상당수가 학습 데이터에서는 존재하지 않는 포즈라는 점입니다. 또한 일부 렌더링은 구도가 참신하고 화가의 스타일을 충실히 모방한 것처럼 보이며, 심지어 일종의 창의성(이전 지식을 바탕으로 한 외삽)을 암시하기도 합니다.

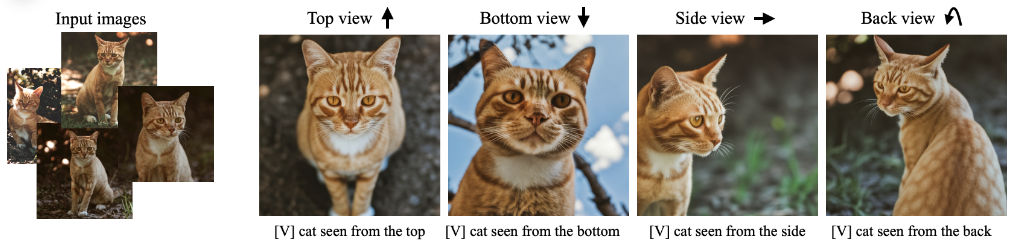
텍스트 기반 뷰 합성
DreamBooth를 사용하면, 피사체 고양이에 대한 지정된 시점(좌에서 우, high angle, low angle, side view, back view 등)의 이미지를 합성할 수 있습니다. 생성된 포지는 입력된 포즈와 다르며, 포즈가 달라지면 그에 맞춰 배경도 사실적으로 변경됩니다. 이 경우에도 피사체 고양이의 이마에 있는 복잡한 문양이 그대로 보존됨을 강조하고 싶습니다.
속성 변경
아래 이미지 중 윗쪽은 "a [color] [V] car"와 같은 프롬프트를 사용해 색상을 변경한 결과이며, 아래쪽은 "a cross of a [V] dog and [대상 종]"과 같은 프롬프트를 사용하여 특정한 멍뭉이와 다른 동물을 섞어본 결과입니다. DreamBooth는 필요한 속성을 변경하면서도, 피사체의 정체성 또는 본질을 부여하는 고유한 시각적 특징을 보존할 수 있다는 점을 강조하고 싶습니다.

액세서리 착용
아래 이미지는 멍뭉이에게 액세서리를 입히는 예입니다. 파사체의 정체성을 유시하면서도 "a [V] dog wearing a police/chef/witch outfit" 과 같은 프롬프트를 사용하여, 멍뭉이에게 다양한 복장 혹은 액세서리를 추가할 수 있었습니다. 이 과정에서 피사체 멍뭉이와 복장/액세서리기간의 사실적인 상호작용 및 아주 다양한 가능성을 관찰할 수 있었습니다.

사회적 영향
이 프로젝트의 목적은 사용자에게 다양한 맥락에서 개인적인 피사체(동물, 사물)를 합성할 수 있는 효과적인 도구를 제공하는 것입니다. 일반적인 텍스트-이미지 합성 모델은 텍스트 프롬프트로 이미지를 합성할 때 특정한 속성에 편향될 수 있지만, DreamBooth는 사용자가 원하는 피사체를 더 잘 재구성할 수 있습니다. 반대로 악의적인 사용자는 이러한 이미지를 사용하여 시청자를 오도할 수 있습니다. 이는 다른 생성형 모델이나 콘텐츠 조작 기법에도 존재하는 문제입니다. 향후 생성형 모델링, 특히 개인화된 생성형 모델에 대한 연구는, 이러한 우려에 대해 지속적으로 조사하고 재검증해야 할 것입니다.
====
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기
- Stable Diffusion - 인페인트 가이드
- Stable Diffusion - 모델에 대한 모든 것
- Stable Diffusion - LoRA 모델 사용법
- Stable Diffusion - ControlNet 사용법(1)
- Stable Diffusion - ControlNet 사용법(2)
- Stable Diffusion - 하이퍼네트워크 사용법
- Stable Diffusion - AI 확대도구 사용법
- Stable Diffusion - 구역분할 프롬프트 사용법
- Stable Diffusion으로 멋진 이미지 만들기