요즘 Stable Diffusion 커뮤니티의 핫한 주제는 Video-to-Video입니다. 그 가운데에는 AnimateDiff 가 있죠. 저도 몇번 생성해봤지만, 아직도 잘 모르는 게 많아, 천천히 알아보려는 중입니다. 이 글은 그중에서 세번째 시도로, https://github.com/guoyww/AnimateDiff/ 을 번역한 글입니다.
===
이 저장소는 Yuwei Guo 등의 논문, AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning 의 공식 구현입니다. AnimateDiff는 추가적인 학습이 없이도, 거의 모든 커뮤니티 모델을 애니메이션 생성기로 바꿔주는 plug&play 모듈이다.
우리는 4가지 버전의 AnimateDiff, 즉 Stable Diffusion V1.5 용 v1, v2, v3 및 SDXL용 sdxl-beta를 개발했다.
- 앞으로 해야 할 일
- 갤러리
- 준비
- [2023.12] AnimateDiff v3 와 SparseCtrl
- [2023.11] AnimateDiff SDXL-Beta
- [2023.09] AnimateDiff v2
- [2003.07] AnimateDiff v1
- Gradio Demo
앞으로 해야 할 일
- 최신 디퓨저 버전으로 업데이트
- Gradio 데모 업데이트
- 학습 스크립트 공개
- AnimateDiff v3와 SparseCtrl 공개
갤러리
갤러리에 결과물 몇가지를 올렸다. 이중 일부는 커뮤니티로부터 제공받은 것이다.
준비
참고 : 자세한 설정은 여기를 보라.
저장소 및 Conda 환경
git clone https://github.com/guoyww/AnimateDiff.git
cd AnimateDiff
conda env create -f environment.yaml
conda activate animatediff스테이블 디퓨전 v1.5 다운로드
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5 models/StableDiffusion/커뮤니티 모델 다운로드
CivitAI로부터 직접 커뮤니티 .safetensors 모델을 다운로드 받고, models/DreamBooth_LoRA에 저장하라. 추천하는 모델은 RealisticVision v5.1 과 ToonYou Beta6 이다.
AnimateDiff 모듈 다운로드
AnimateDiff 모듈을 직접 다운로드 받는다. 다운로드 링크는 아래에 있는 각각의 버전의 모델 zoo에 있다. 모듈은 models/Motion_Module 에 저장하라.
[2023.12] AnimateDiff v3 와 SparseCtrl
이 버전에서 추론시 유연성을 좀더 확보하기 위해 Domain Adapter LoRA를 통해 이미지 모델을 미세조정하였다.
또한 두가지(RGB image / Scribble) SparseCtrl 인코도를 구현하였다. SparseCtrl은 임의의 조건 맵을 받아들여 생성 프로세스를 제어할 수 있다.
- 설명 : Domain Adapter는 학습 비디오 데이터셋의 정적 프레임에 대해 학습된 LoRA 모듈이다. 이 프로세스는 모션모듈 학습 전에 수행되며, 아래 그림과 같이 모션 모듈이 모션 모델링에 집중하도록 도와준다. Domain Adapter의 LoRA 척도를 조정함으로써, 학습 비디오의 몇가지 시각적 속성(워터마크 등)은 제거될 수 있다. SparseCtrl 인코더를 활용하기 위해, 파이프라인에서 완전한 Domain Adapter를 사용할 필요가 있다.

SpartseCtrl에 대한 기술적 상세 사항은 아래의 논문을 참조하라.
AnimateDiff v3 모델 zoo
| 이름 | HuggingFace | 유형 | 저장공간 | 비고 |
| v3_adapter_sd_v15.ckpt | 링크 | Domain Adapter | 97.4 MB | |
| v3_sd15_mm.ckpt.ckpt | 링크 | Motion Module | 1.56 GB | |
| v3_sd15_sparsectrl_scribble.ckpt | 링크 | SparseCtrl Encoder | 1.86 GB | 스크리블 조건 |
| v3_sd15_sparsectrl_rgb.ckpt | 링크 | SparseCtrl Encoder | 1.85 GB | RGB 이미지 조건 |
데모
| 입력(RealisticVision) | 애니메이션 | 입력 | 애니메이 |
 |
 |
 |
 |
| 입력 스크리블 | 출력 | 입력 스크리블 | 출 |
 |
 |
 |
 |
추론
아래는 세가지 추론 스크립트이다. 해당 AnimateDiff 모듈과 커뮤니티 모델을 미리 다운로드 받아야 한다. 모션 모듈은 models/Motion_moduledp sjgrh, SparseCtrl 인코더는 models/SparseCtrl에 넣어라.
# under general T2V setting
python -m scripts.animate --config configs/prompts/v3/v3-1-T2V.yaml
# image animation (on RealisticVision)
python -m scripts.animate --config configs/prompts/v3/v3-2-animation-RealisticVision.yaml
# sketch-to-animation and storyboarding (on RealisticVision)
python -m scripts.animate --config configs/prompts/v3/v3-3-sketch-RealisticVision.yaml한계
- 약간의 깜빡임이 나타난다. 향후 버전에서 해결될 것이다.
- 커뮤니티 모델과 부합성을 유지하기 위해 일반 Txt2Vid 에 대해서 특별한 최적화를 시행하지 않아서, 이 설정하에서는 시각적 품질이 떨어진다.
- (Style Alignment) 이미지 애니메이션/내삽과 같은 사용을 위해, 동일한 커뮤니티 모델에서 생성된 이미지를 사용할 것을 추천한다.
[2023.11] AnimateDiff SDXL-Beta
SDXL용 모션 모듈(beta)을 공개하였다. Google Drive / HuggingFace / CivitAI 에서 받을 수 있다. 개인화된 모델을 사용하면 (혹은 개인화된 모델 없이도) 고해상도 비디오(예: 1024x1024 16 프레임)를 생성할 수 있다. 추론은 개인화된 모델에 따라 다르지만, 대략 13 GB VRAM과 미세조정된 hyperparameters(예 : #sampling steps) 이 필요하다.
추론에 대한 좀더 상세한 사항은 여기를 확인하라. 더 나은 품질의 더 많은 체크포인트 모델이 공개될 것이다. 아래의 예는 속도를 위해 의도적으로 사이즈를 줄인 것이다.
AnimateDiff SDXL-Beta 모델 zoo
| 이름 | HuggingFace | 유형 | 저장공간 | 비고 |
| mm_sdxl_v10_beta.ckpt | 링크 | 모션 모듈 | 950 MB |
| original SDXL | 커뮤니티 SDXL | 커뮤니티 SDXL |
 |
 |
 |
[2023.09] AnimateDiff v2
이 버전에서 모션 모듈은 고해상도 및 고 배치크기로 학습되었다. 이를 통해 샘플의 품질이 확실하게 향상되었다.
아울러 우리는 8개의 기본적인 카메라 움직임을 위한 Motion LoRA를 지원한다.
AnimateDiff v2 모델 zoo
| 이름 | HuggingFace | 유형 | 저장공간 | 비고 |
| mm_sd_v15_v2.ckpt | 링크 | 모션 모듈 | 453 MB | |
| v2_lora_ZoomIn.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_ZoomOut.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_PanLeft.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_TiltUp.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_TiltDown.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_RollingClockwise.ckpt | 링크 | 모션 LoRA | 19 MB | |
| v2_lora_RollingAntiClockwise.ckpt | 링크 | 모션 LoRA | 19 MB |
- MotionLora와 모델 zoo를 사용하면 카메라 움직임을 제어할 수 있다. MotionLoRA 모델을 다운로드 받고(모델당 74MB, Google Drive / HuggingFace / CivitAI) models/MotionLoRA 폴더에 저장하라.
아래와 같이 사용할 수 있다.
python -m scripts.animate --config configs/prompts/v2/5-RealisticVision-MotionLoRA.yaml| Zoom In | Zoom Out | Pan Left | Pan Right | ||||
 |
 |
 |
 |
 |
 |
 |
 |
| Tilt Up | Tilt Down | Rolling Anti-Clockwise | Rolling Clockwise | ||||
 |
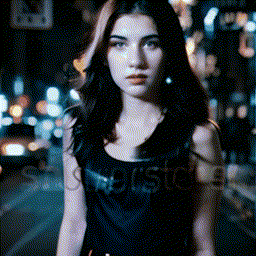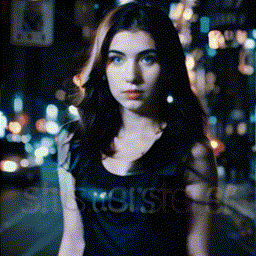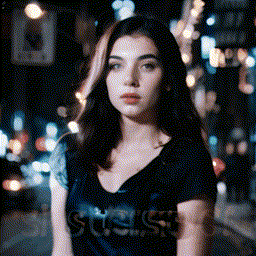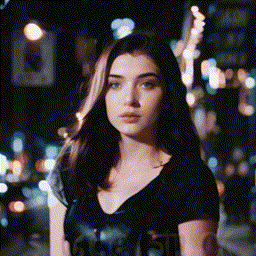 |
 |
 |
 |
 |
 |
 |
- 새로운 모션 모듈이 공개되었다. mm_sd_v15_v2.ckpt는 더 큰 해상도와 배치 사이즈로 학습되어, 상당한 품질 향상이 이루어졌다. Google Drive / HuggingFace / CivitAI 에서 확인하고, config/inference/inference-v2.yaml 과 함께 사용하라. 예를 들면 아래와 같이 사용할 수 있다.
python -m scripts.animate --config configs/prompts/v2/5-RealisticVision.yaml아래는 mm_sd_v15.ckpt(왼쪽)과 mm_sd_v15_v2.ckpt (오른쪽)을 비교해본 것이다.
 |
 |
 |
 |
 |
 |
 |
 |
[2003.07] AnimateDiff v1
AnimateDiff v1 모델 zoo
| 이름 | HuggingFace | 유형 | 저장공간 | 비고 |
| mm_sd_v14.ckpt | 링크 | Motion Module | 1.6 MB | |
| mm_sd_v15.ckpt | 링크 | Motion Module | 1.6 GB |
데모
(모델: TooonYou)
 |
 |
 |
 |
(모델: Realistic Vision v2.0)
 |
 |
 |
 |
추천
아래는 몇가지 데모 추론 스크립트이다. 해당 AnimateDiff 모듈과 커뮤니티 모델은 미리 다운로드 받아야 한다. 자세한 설정 방법은 여기를 보라.
python -m scripts.animate --config configs/prompts/1-ToonYou.yaml
python -m scripts.animate --config configs/prompts/3-RcnzCartoon.yamlGradio Demo
AnimateDiff를 사용하기 쉽도록 Gradio 데모를 제작하였다. 데모를 시작하려면 아래의 명령을 입력하라.
conda activate animatediff
python app.py기본으로, 데모는 localhostL:7860 에서 수행된다.
