IP-adapter(Image Prompt adapter)는 미드저니나 DallE 3와 같이, 이미지를 프롬프트로 사용할 수 있는 스테이블 디퓨전 애드온입니다. IP-adapter를 사용하면 참조 이미지로부터 스타일, 구도, 얼굴을 복사할 수 있습니다.
이 글에서는 IP-adapter의 여러가지 모델(Plus, Face ID, Face ID v2, Face ID portrait 등)과 이들 IP Adapter를 AUTOMATIC1111과 ComfyUI에서 사용하는 방법을 알아봅니다. 아래는 목차입니다.
IP-adapter 모델
현재 IP-adapter모델의 수가 매우 빠르게 늘어나고 있습니다. 아마도 IP-adapter가 여러가지 면에서 매우 유용하기 때문일 겁니다. ControlNet을 사용하면 전체적인 구도나 형태 등을 복사할 수는 있지만, 스타일이나 얼굴을 복사하는 측면에서는 IP-adapter 가 매우 뛰어난 능력을 보입니다. 아마도 그 때문이겠죠. 아무튼 너무 숫자가 빠르게 늘어나서 계속 신경쓰지 않으면 따라잡기가 힘들 수 있습니다.
여기에서는 현재까지 공개된 모든 IP-adpater에 대해 개략적으로 설명합니다. 원래의 IP-adapter 저장소는 아래와 같습니다.
- IP-Adapter GitHub page (codes)
- IP-Adapter models (Hugging Face)
- IP-Adapter Face ID models (Hugging Face)
이미지 인코더는 참조이미지를 처리하여 IP-adapter에 넣는 역할을 합니다. IP-adapter에는 아래와 같이 두 가지 이미지 인코더가 사용됩니다.
- OpenClip ViT H 14 (aka SD 1.5 version, 632M paramaters)
- OpenClip ViT BigG 14 (aka SDXL version, 1845M parameters)
하지만, 일부 SDXL용 IP-adapter도 H 버전으로 학습받아서 이렇게 구분하기는 약간 힘듭니다. 이 글에서는 명확하게 하기 위해 ViT H 와 ViT BigG 버전이라고 부르겠습니다. (ViT는 Vision Transformer를 뜻합니다. 영어 Wiki에 따르면 " 비전 트랜스포머(ViT)는 컴퓨터 비전을 위해 설계된 트랜스포머이다. ViT는 (텍스트를 토큰으로 분해하는 대신) 이미지를 일련의 조각으로 나누고, 각 조각을 벡터로 직렬화하며, 단일 행렬 곱셈을 통해 더 작은 차원으로 매핑합니다..."라고 하네요.)
원래의 IP-Adapter
- 이미지 인코더 : ViT H
- 모델: IP-adapter SD 1.5
원래의 IP-adapter는 CLIP 이미지 인코더를 사용하여 참조 이미지로부터 특징들을 추출합니다. 이때, IP adapter는 이미지에 대해 별도의 교차 인지 레이어를 학습시킨다는 점이 뛰어난 점입니다. 이를 통해 이미지 생성 처리과정을 좀 더 효율적으로 제어할 수 있습니다.
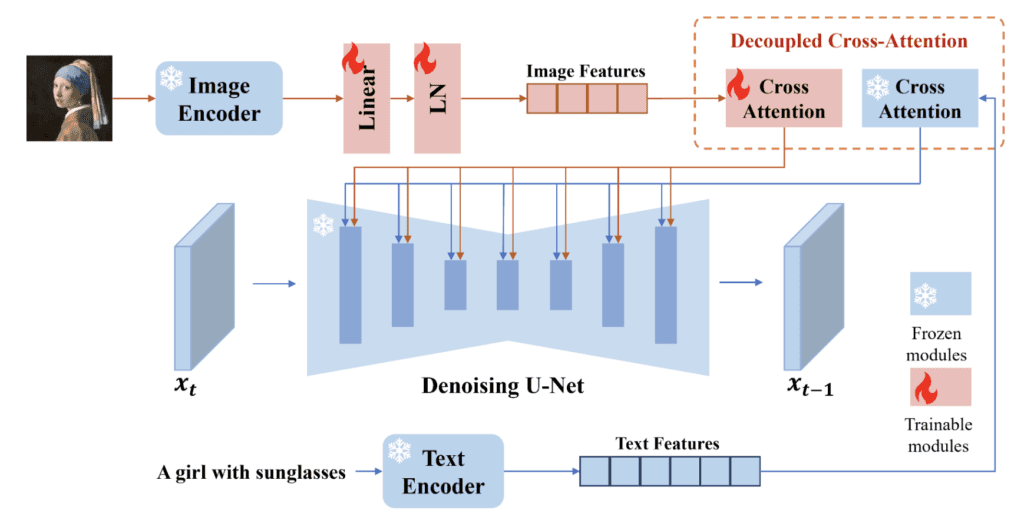
아래는 IP-adapter의 입력과 출력을 비교한 것입니다. 출력은 참조이미지의 내용을 따르기는 하지만, 완벽하게 아니라 어느 정도 유연하게 따르는 것을 볼 수 있습니다. 아래는 Realistic Vision 모델을 사용하였고, 프롬프트는 비워두고 실행시킨 결과입니다. (원 이미지 출처 Freepik :작가 benzoix) 그런데 보시는 것처럼 얼굴이 아주 약간만 닮은 듯한 느낌입니다. 사실 백인 여자가 훨씬 잘되는 편입니다.
 |
 |
IP adapter Plus
- Image Encoder : ViT H
- Model: IP-Adapter Plus
IP adapter Pluse는 Flamingo의 퍼셉터 리샘플러와 유사한 패치 임베딩 방식을 사용하여 이미지를 인코딩합니다. IP adapter Plus 모델을 원래의 참조 이미지를 좀더 잘 따릅니다. 다만, 얼굴과 같은 세밀한 디테일은 올바르게 복사되지 안는 경향이 있습니다. 여기도 얼굴 분위기는 그다지 닮은 것 같지는 않네요.
 |
 |
IP-adapter Plus Face
- 이미지 인코더: ViT H
- 모델 : IP-Adapter Plus Face
IP-adapter Plus Face모델은 IP-Adapter Plus와 동일한 아키텍처를 가지고 있습니다. 다만, 이 모델의 가중치는 참조이미지가 얼굴만 크롭된 이미지를 사용할 때에 대해 미세조정되어 있습니다.
따라서 이 모델을 사용할 때에는 아래와 같이 얼굴 확대사진을 사용하는 게 좋습니다. 흠... 얼굴이 닮기는 닮은 것 같은데... 아리송한 느낌??
 |
 |
IP-Adapter Plus Face를 사용하면 프롬프트를 사용하여 이미지를 지정하기가 훨씬 쉽습니다. 외국인 모델을 사용하면 확실히 분위기를 잘 살려줍니다.
 |
 |
IP-Adapter SDXL
IP-Adapter SDXL 은 두가지 버전이 있습니다. 하나는 ViT BigG로 학습된 것이고, 다른 하나는 ViT H로 학습받은 것입니다.
이 글에서는 DreamShaper SDXL 모델을 사용하여 IP-Adapter SDXL 버전을 시험해 보겠습니다.
== ViT BigG 버전
- 이미지 인코더: ViT BigG
- 모델 : IP-Adapter SDXL
이는 원래의 IP-Adapter의 SDXL 버전입니다. 이는 대용량 이미지 인코더 ViT BigG를 사용합니다. 흠... 그런데 얼굴이 닮은 건가요?
 |
 |
== ViT H 버전
- 이미지 인코더 : ViT H
- 모델 : IP-Adapter SDXL ViT H 여러번 테스트해봤는데, 역시나 백인 얼굴이 더 잘 복사되는 것 같네요. 동양여자는 어딘가 혼혈인 듯한 느낌이 들어요.
 |
 |
 |
 |
IP-Adapter Plus SDXL
- 이미지 인코더 : ViT H
- 모델 : IP-Adapter Plus SDXL ViT H
 |
 |
 |
 |
IP-Adapter Plus Face SDXL
- 이미지 인코더 : ViT H
- 모델 : IP-Adapter Plus Face SDXL ViT H
IP-Adapter Plus Face SDXL 모델은 IP Adapter Plus SDXL 모델과 동일한 아키텍처이나, 제어 이미지에 얼굴 확대사진을 사용합니다. 이 모델을 사용하면 얼굴을 보다 잘 복사합니다.
 |
 |
 |
 |
IP-Adapter Face ID
- 이미지 인코더 : InsightFace
- 모델 : IP-Adapter Face ID
- LORA: Face ID SD 1.5
IP-Adapter Face ID는 InsightFace 를 사용해서 참조 이미지로부터 Face ID 임베딩을 추출합니다.
Face ID 모델의 경우, 관련 LoRA 파일을 함께 사용하는 게 좋다고 합니다.
모델 : Realistic Vision v60
프롬프트: A girl in office, white professional shirt <lora:ip-adapter-faceid_sd15_lora:0.6>
 |
 |
오... 그런데, 김배우님은 아주 잘 나오네요.
IP-Adapter Face ID SDXL
- 이미지 인코더 : InsightFace
- 모델 : IP-Adapter Face ID SDXL
- LoRA : Face ID SDXL
IP-Adapter Face ID는 InsightFace 를 사용하여 참조 이미지로 부터 Face ID 임베딩을 추출합니다.
InsightFace 모델은 별도의 SDXL 버전이 없으며, SD 1.5용을 사용합니다. 또, 이 모델도 별도의 LoRA와 함께 사용하는 게 좋습니다.
모델: JuggernautXL
 |
 |
기타 IP Adapter
원본 글에는 기타 Face ID 계열의 여러가지 IP-Adapter 가 소개되어 있습니다. 하지만 구지 소개할 필요가 없을 듯하네요. 다만 필요하시면 해당 모델만 다운로드 받아두시면 됩니다.
AUTOMATIC1111에서 IP-Adapter 사용하기
소프트웨어
AUTOMATIC1111은 스테이블 디퓨전용 GUI중에서 가장 유명한 무료 소프트웨어입니다. 설치방법은 여기를, 기본적인 사용법과 메뉴에 대해서는 여기를 보시기 바랍니다.
ControlNet 확장 설치
AUTOMATIC1111 에서 IP-Adapter를 사용하려면 먼저 ControlNet 확장을 설치해야 합니다. 설치방법은 여기를 읽어보시면 됩니다.
또는, 아래의 URL을 사용해서 직접 설치하는 방법도 있습니다.
https://github.com/Mikubill/sd-webui-controlnetIP-Adapter 다운로드
AUTOMATIC1111 콘트롤넷에서 IP-Adapter를 사용하려면 IP-Adapter 모델을 다운로드 받아야 합니다. 다운로드 링크는 위쪽에 있으니 참고하세요. 다운 받은 파일은 stable-diffusion-webui\model\ControlNet에 넣어주시면 됩니다. 이미지 인코더는 따로 받으실 필요 없습니다.
IP-Adapter 설정
어떤 모델을 사용해도 사용법은 동일하므로, 여기에서는 SD 1.5 용 IP-Adapter Plus를 사용하는 방법을 예로 들겠습니다.
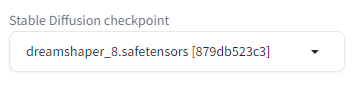
1단계: 체크포인트 모델 선택
SD 1.5 용 IP-Adapter를 사용하므로, 체크포인트 파일도 SD 1.5 모델을 선택해야 합니다. 이 글에서는 Dreamshaper 8 모델을 사용합니다.
txt2img 페이지에서 Stable Diffusion checkpoint 드롭다운 메뉴에서 dreamshaper_8.safetensors를 선택합니다.
2단계: 프롬프트와 LoRA를 선택합니다.
프롬프트: A woman in office, white professional shirt
부정적 프롬프트: disfigure, deformed, ugly
아래의 표를 보면, FaceID 종류의 모델을 사용할 때에는 별도로 LoRA를 사용하는 게 좋습니다. 아래의 표에서 링크를 클릭하시고, 일반 LoRA처럼 stable-diffusion-webui\models\LoRA에 넣어준 뒤, 해당 LoRA를 선택하시면 됩니다.
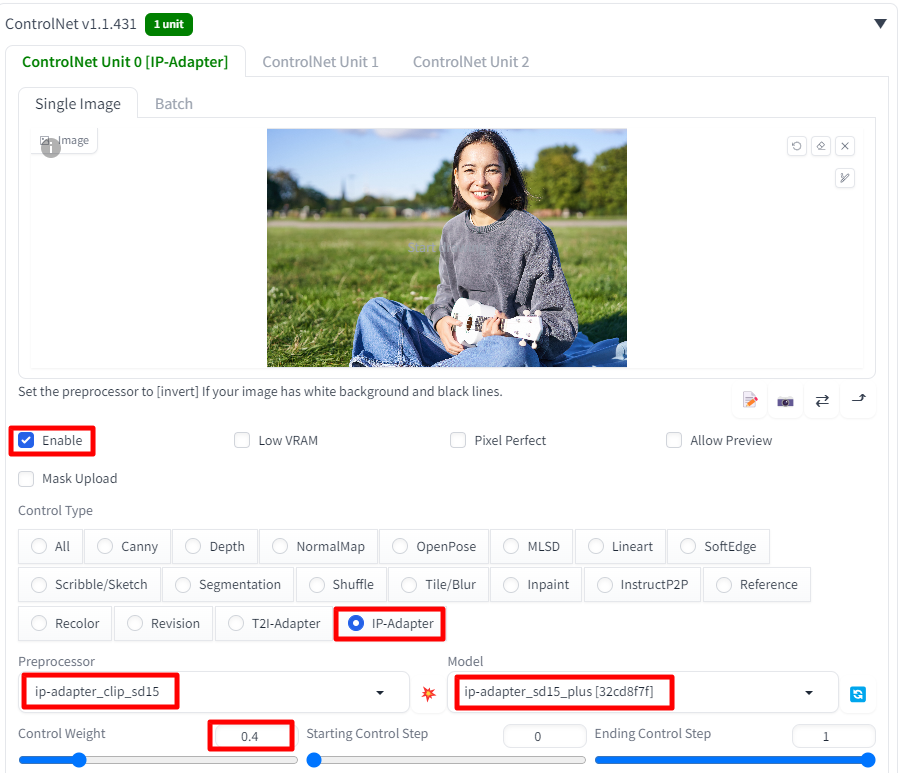
3단계: ControlNet을 설정합니다.
아래쪽으로 ControlNet영역을 펼치고 전처리기와 모델을 선택합니다. 이 것을 선택할 때에는 아래 표를 참고하시면 됩니다.
| 버전 | 전처리기(Preprocessor) | IP-Adapter | LoRA |
| SD 1.5 | ip-adapter_clip_sd15 | ip-adapter_sd15 | |
| SD 1.5 Plus | ip-adapter_clip_sd15 | ip-adapter_sd15_plus | |
| SD 1.5 Plus Face | ip-adapter_clip_sd15 | ip-adapter-plus-face_sd15 | |
| SD 1.5 Face ID | ip-adapter_face_id | ip-adapter-faceid_sd15 | |
| SD 1.5 Face ID Plus | ip-adapter_face_id_plus | ip-adapter-faceid-plus_sd15 | ip-adapter-faceid-plus_sd15_lora |
| SD 1.5 Face ID Plus V2 | ip-adapter_face_id_plus | ip-adapter-faceid-plusv2_sd15 | ip-adapter-faceid-plusv2_sd15_lora |
| SDXL | ip-adapter_clip_sdxl | ip-adapter_sdxl | |
| SDXL ViT H | ip-adapter_clip_sdxl_plus_vith | ip-adapter-sdxl_vit-h | |
| SDXL Plus ViT H | ip-adapter_clip_sdxl_plus_vith | ip-adapter-plus_sdxl_vit-h | |
| SDXL Face ID | ip-adapter_face_id | ip-adapter-faceid_sdxl |
ip-adapter-faceid_sdxl_lora |
| SDXL Face ID Plus v2 | ip-adapter_face_id_plus | ip-adapter-faceid-plusv2_sdxl |
ip-adapter-faceid-plusv2_sdxl_lora |
이 글에서는 SD 1.5 Plus를 사용하므로 아래와 같이 설정합니다.
- Image 캔버스에 참조 이미지를 선택합니다.
- Enable : Yes
- Control Type : IP-Adapter
- 전처리기(preprocessor) : ip-adapter_clip_sd15
- 모델(model) : ip-adpater_sd15_plus를 선택합니다.
- Control Weight : 0.4
여기에서 Control Weight는 ControlNet의 내용을 얼마나 반영할 것인지를 정하는 매개변수입니다. 프롬프트에서는 사무실에 있는 모습을 생성하라고 했는데, 잘 안나와서 1.0을 0.4로 낮췄습니다.
아래는 이렇게 생성한 영상입니다.
 |
 |
 |
 |
다중 IP-Adapter
ControlNet 영역에는 아래와 같이 3개의 영역이 있습니다. 이 세 영역에 모두 동일한 인물의 이미지를 넣어주면 해당 얼굴을 좀 더 확실하게 반영할 수 있습니다. 다만, 이때, Control Weight 는 각각 0.3으로 설정해서 1이 넘지 않도록 해줍니다.

저는 아래의 박은빈님 사진을 사용하겠습니다. 사진은 클 수록 좋고, IP-Adapter의 특성상 1:1 사진이 좋습니다. 이번엔 얼굴을 좀더 잘 복제하기 위해 ip-adapter-plus-face 모델을 사용했습니다.
 |
 |
 |
프롬프트: Selfie photo of a woman, smiling, disney, mickey headwear
 |
 |
얼굴이 많이 귀엽긴 한데, 박은빈님을 닮은 건지 의심스럽습니다. 외국인으로 한번해보죠.
 |
 |
 |
아래가 결과입니다. 여기도 어찌 좀 어린 얼굴이 만들어졌네요. ㅎㅎ
 |
 |
ComfyUI에서 IP-Adapter 사용하기
소프트웨어
여기에서는 ComfyUI 에서 IP-Adapter를 사용해 이미지를 생성합니다. ComfyUI 설치 및 기본 사용방법과 ComfyUI 초보자 가이드를 읽어보세요.
여러가지 IP-adapter를 사용하려면 IP Adapter Plus 커스톰 노드를 먼저 설치하셔야 합니다. 커스톰노스 설치방법은 여기를 읽어보세요.
ComfyUI용 InsightFace 설치
FaceID 모델을 사용할 경우, 별도로 InsightFace를 설치해야 합니다.
그전에 최근 ComfyUI가 Python 버전을 업데이트했는데, 그 버전부터 확인해야 합니다. 파일 탐색기를 열어 ComfyUI_windows_potable 폴더로 들어간 후, 주소에 cmd를 입력하고 Enter 키를 누릅니다.
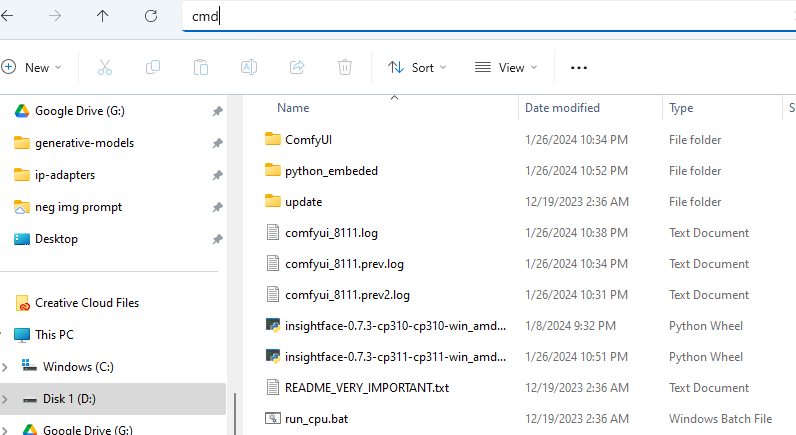
그러면 터미널 창이 열리는데, 여기에 아래의 명령을 입력하고 엔터를 누릅니다.
.\python_embeded\python.exe --version그러면 Python 3.10.x 또는 Python 3.11.x라고 나타날 것입니다. 이에 따라 아래 설치파일을 다운로드 받습니다.
이들 파일을 ComfyUI_windows_portable 폴더에 넣어줍니다.
다음으로 터미널로 돌아가 아래 명령을 수행해 줍니다.
Python 3.10.x 의 경우
.\python_embeded\python.exe -m pip install .\insightface-0.7.3-cp310-cp310-win_amd64.whlPython 3.11.x의 경우
.\python_embeded\python.exe -m pip install .\insightface-0.7.3-cp311-cp311-win_amd64.whl이러면 Insight Face 가 설치됩니다.
모델과 LoRA 다운로드
| Version | CLIP Vision | IP-Adapter 모델 | LoRA | IPAdapter Unified Loader 설정 | 워크플로 |
| SD 1.5 | ViT_H | ip-adapter_sd15 | STANDARD | 링크 | |
| SD 1.5 Plus | ViT_H | ip-adapter_sd15_plus | PLUS | 링크 | |
| SD 1.5 Light | ViT_H | ip-adapter_sd15_light.bin | LIGHT | 링크 | |
| SD 1.5 VIT-G | Vit_BigG | ip-adapter_sd15_vit-G | VIT-G | 링크 | |
| SD 1.5 Plus Face | ViT_H | ip-adapter-plus-face_sd15 | PLUS FACE | 링크 | |
| SD 1.5 Full Face | ViT_H | ip-adapter-full-face_sd15 | FULL FACE | 링크 | |
| SD 1.5 Face ID | Not used | ip-adapter-faceid_sd15 | FACEID | 링크 | |
| SD 1.5 Face ID Plus | ViT_H | ip-adapter-faceid-plus_sd15 | ip-adapter-faceid-plus_sd15_lora | FACEID PLUS | 링크 |
| SD 1.5 Face ID Plus V2 | ViT_H | ip-adapter-faceid-plusv2_sd15 | ip-adapter-faceid-plusv2_sd15_lora | FACEID PLUS V2 | 링크 |
| SD 1.5 Face ID portriat | ViT_H | ip-adapter-faceid-portrait_sd15 | FACEID PORTRAIT | 링크 | |
| SDXL | ViT_BigG | ip-adapter_sdxl | VIT-G | 링크 | |
| SDXL ViT H | ViT_H | ip-adapter-sdxl_vit-h | STANDARD | 링크 | |
| SDXL Plus ViT H | ViT_H | ip-adapter-plus_sdxl_vit-h | PLUS | 링크 | |
| SDXL Plus Face | ViT_H | ip-adapter-plus-face_sdxl_vit-h | PLUS FACE | 링크 | |
| SDXL Face ID | Not used | ip-adapter-faceid_sdxl |
ip-adapter-faceid_sdxl_lora |
FACEID | 링크 |
| SDXL Face ID Plus v2 | ViT_H | ip-adapter-faceid-plusv2_sdxl |
ip-adapter-faceid-plusv2_sdxl_lora | FACEID PLUS V2 | 링크 |
| SDXL Face ID portrait | VIT-H | ip-adapter-faceid-portrait_sdxl | FACEID PORTRAIT | 링크 | |
| SDXL Face ID portrait Unnorm |
VIT-H | ip-adapter-faceid-portrait_sdxl_unnorm | FACEID PORTRAIT UNNORM |
링크 |
사용하고자 하는 버전에 따라 IP-Adapter 모델과 LoRA 를 다운로드 받습니다.
IP-Adapter 모델은 ComfyUI\models\ipadapter 에 넣어줍니다. LoRA 파일은 ComfyUI\models\LoRA 폴더에 넣어주면 됩니다.
또한 아래의 두가지 이미지 인코더가 필요합니다.
- OpenClip VIT BigG(SDXL 용: CLIP-ViT-bigG-14-laion2B-39B-b160k.safetensors 로 이름을 변경해 줍니다)
- OpenClip VIT H(SD 1.5용: CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors 로 이름을 변경해 줍니다)
다운로드 받은 파일은 ComfyUI\models\clip_vision에 넣어줍니다.
IPAdapter Unified Loader 설정
ComfyUI에서는 [IPAdapter Unified Loader] 와 [IPAdapter Unified Loader FaceID]노드를 사용하여 CLIP Vision 및 IP Adapter 모델을 자동으로 설정합니다. 아래 왼쪽은 [IPAdapter Unified Loader] 노드, 오른쪽은 [IPAdapter Unified Loader FaceID]노드 설정할 수 있는 값입니다. 위의 표에서는 [IPAdapter Unified Loader] 는 하늘 색으로 표시해 두었습니다.
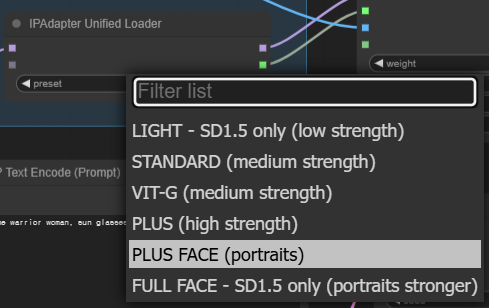 |
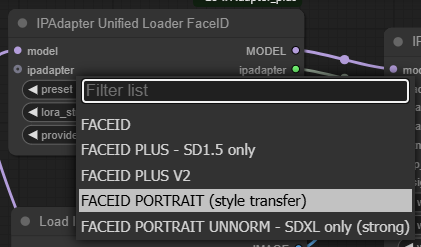 |
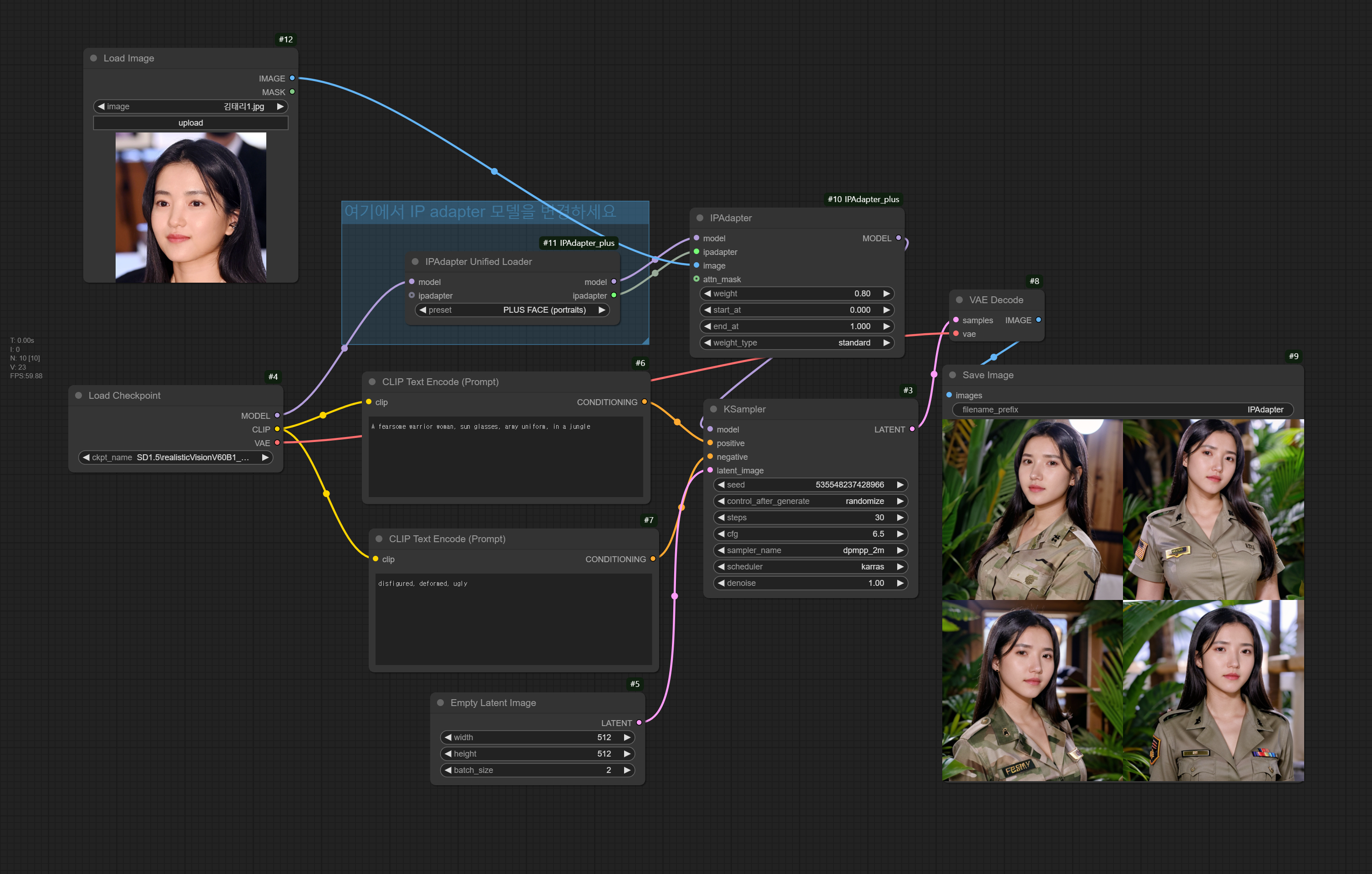
IP-Adapter SD1.5용 워크플로
아래는 IP-Adapter SD 1.5, SD 1.5 Plus, SD 1.5 Plus Face 를 위한 워크플로입니다. 사용하기 전에 위에 있는 표에 따라 적절한 IP-Adapter 모델을 선택해주면 됩니다. 그런데.... 김태리님 얼굴이 좀 길어졌나 싶고, 선글라스는 어디로 사라졌는지 모르겠네요.
IP-Adapter SDXL 용 워크플로
아래는 IP-Adapter SDXL, SDXL ViT, SDXL Plus ViT 용 워크플로입니다. 사용하기 전에 위에 있는 표에 따라 적절한 IP-Adapter 모델과 CLIP Vision 모델을 선택해주면 됩니다.

IP-Adapter Face ID SD 1.5 용 워크플로
아래는 IP-Adapter Face ID SD 1.5 용 워크플로입니다. 사용하기 전에 위에 있는 표에 따라 적절한 IP-Adapter 모델과 CLIP Vision 모델을 선택해주면 됩니다. FaceID를 사용하니 김태리님의 얼굴이 살아나네요.

IP-Adapter Face ID SDXL 용 워크플로
아래는 IP-Adapter Face ID SDXL 용 워크플로입니다. 사용하기 전에 위에 있는 표에 따라 적절한 IP-Adapter 모델과 CLIP Vision 모델을 선택해주면 됩니다.

요약 및 정리
IP-Adapter 는 특히 얼굴과 분위기, 구도 등을 복제하는 데 사용합니다. 하지만, 분위기나 구도 등은 비슷하기는 한데... 하는 정도고, 제일 많이 드러나는 게 얼굴을 복제하는 능력으로 다른 여러가지 방법에 비해 매우 간단하면서도 효율적이라는 장점이 있습니다. 특히 스테이블 디퓨전으로 비슷한 얼굴을 생성하는 방법에 나오는 여러가지 방법중에 IP-Adapter 를 사용하는 게 가장 좋지 않나 싶습니다.
하지만, 원래 스테이블 디퓨전 모델이 그렇듯이 외국인 얼굴을 위주로 학습되었기 때문에 동양인 얼굴은 잘 살려내지 못하는 경향이 있습니다. 중간에 몇번 말씀드렸지만, 동양인 얼굴을 입력하면 꼭 혼혈느낌으로 생성되는 것 같습니다. 일단 이런 경향을 줄이려면 다중 IP-Adapter 같은 방법을 사용해야 할 것 같다는 느낌입니다. 좀 더 테스트해봐야겠지만요.
그리고, IP-Adapter 모델이 10개 이상이고, 사용하는 체크포인트 모델에 따라서도 나오는 결과가 달라질 수 있기 때문에 특정인을 그대로 모사를 하려면 상당히 많은 테스트를 거쳐야 할 것으로 생각됩니다. 그냥 비슷한 정도라면 괜찮겠지만, 예를 들면 가족 얼굴을 생성하려면 적절한 IP-Adapter 모델과 적절한 checkpoint 찾느라 고생할 것 같은 느낌이네요.
이상입니다. 이 글은 https://stable-diffusion-art.com/ip-adapter/ 을 번역하면서 필요에 따라 예제를 바꾸고, 제 생각을 담아서 작성했습니다.
민, 푸른하늘
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기