이 글에서는 AnimateDiff Prompt Travel Video-to-video, 즉, AnimateDiff 와 프롬프트를 사용해서 기준 Video를 유사한 다른 비디오를 만드는 기법을 소개시켜드립니다. 이제까지 Stable Diffusion을 사용해서 비디오를 만드는 방법은 여러번 소개시켜드렸는데(다섯가지 방법, Deforum, AnimateDiff) 여러가지 한계가 있었습니다. 이 글에서 소개시켜 드리는 방법도 완벽하다고는 할 수 없지만, 상당히 부드럽고 일관성이 있는 비디오를 생성할 수 있는 기법입니다.
이 글의 목차는 아래와 같습니다.
AnimateDiff Prompt Travel의 작동 원리
AnimateDiff는 제 글에서도 여러번 소개시켜드렸는데, 어떠한 스테이블 디퓨전 모델을 사용해도 상당히 괜찮은 비디오를 생성해주는 놀라운 도구입니다. 다른 도구와는 달리 장면과 장면사이에 일관성이 유지되어서 번쩍거림이 없는 비디오를 만들어주죠. 하지만, 생성된 비디오가 아주 짧고(대부분 2-3초) 한정된 움직임만 표현하며, 그나마 움직임 제어가 거의 불가능하다는 단점이 있습니다.
AnimateDiff Prompt Travel 기법은 다음과 같은 여러가지 기법을 동원하여 비디오를 생성함으로써, 위에서 설명한 여러가지 단점을 극복할 수 있는 기법입니다.
- AnimateDiff의 국부적인 일관성 유지
- ControlNet 을 이용한 참조 비디오의 움직임 복제
- 시간대별로 프롬프트를 변경하여 여러가지 장면을 생성
AnimateDiff Prompt Travel 기법을 요약하면 아래와 같습니다.
- 비디오를 입력을 사용
- Openpose 전처리기를 사용해서 각 비디오 프레임으로부터 자세를 추출
- AnimateDiff Motion 모델과 Openpose 모델을 사용해 각 프레임의 모델을 제어
- 각 프레임에 대해 다른 프롬프트를 적용
- 최종 비디오 저장
소프트웨어 설정
이 글에서 나오는 기법을 사용하기 위해서는 스테이블 디퓨전용 웹UI중 하나인 ComfyUI를 사용합니다. ComfyUI 를 설치하는 방법 및 기초적인 사용법은 이 글을 읽어보시기 바랍니다.
또한 ComfyUI Manager 를 설치하셔야 합니다. 설치 방법은 이 글을 읽어보세요.
워크플로 불러오기
ComfyUI 는 워크플로를 완벽하게 복제할 수 있는 장점이 있습니다. 워크플로는 생성된 이미지를 사용하여 공유할 수도 있고, JSON 파일을 사용하여 공유할 수도 있는데, 저는 워크플로 이미지를 공유하는 것을 선호합니다. 아래의 그림을 다운로드 받은 후, ComfyUI 캔버스에 Drag&Drop하면 워크플로가 복원됩니다.

다만, 이 워크플로를 불러들이면 대부분 아래와 같이 에러가 발생할텐데, 이 글을 읽어보시면 해결하실 수 있습니다.

사용방법
체크포인트 모델 선택
이 글에서는 Dreamshaper 8 모델을 사용합니다. 모델이 없을 경우에는 다운로드 받아 "ComfyUI > models > checkpoints" 폴더에 넣어줍니다. AUTOMATIC1111과 모델파일을 공유하실 경우에는 이 글을 참고하세요. F5를 눌러 ComfyUI 화면을새로고침(Refresh)하면 적용이 됩니다.
그 다음 [Load Checkpoint w/Noise Select] 노드를 찾아 체크포인트 파일이 dreamshaper_8.safetensors인지 확인합니다.

물론 반드시 이 모델을 사용해야 하는 건 아니고, SD1.5 모델이라면 어떤 걸 사용해도 무방합니다.^^
VAE 모델 선택
Stability AI에서 공개한 VAE 파일을 다운로드 받아 "ComfyUI > models > vae" 폴더에 넣습니다. 마찬가지로 이 글을 보시면 AUTOMATIC1111과 공유할 수 있고, F5를 눌러 ComfyUI 화면을 새로고침(Refresh)하면 적용이 됩니다.
[Load VAE]노드를 찾아 다운로드 받은 파일을 선택합니다.

AnimateDiff 모델 선택
그 다음 AnimateDiff 모델을 다운로드 받으셔야 합니다. 아래의 폴더에 들어가서 mm_sd_v15_v2.ckpt 모델을 받은 후...
https://huggingface.co/guoyww/animatediff/tree/main
아래 폴더에 넣어주면 됩니다. ComfyUI 화면을 새로고침(Refresh)하면 적용이 됩니다.
ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\models
다음으로[AnimateDiff Loader] 노드를 찾아, 어래와 같이 mm_sd_v15_v2.ckpt 을 선택해줍니다.

Openpose ControlNet 모델 선택
sd1.5용 콘트롤넷 모델 사이트에서 openpose ControlNet 모델을 다운로드 받아 ComfyUI > models > controlnet 폴더에 넣어줍니다. ControlNet 모델도 AUTOMATIC1111과 공유할 수 있습니다. 이 글을 참고하세요. F5를 눌러 ComfyUI 화면을새로고침(Refresh)하면 적용이 됩니다.
[Load ControlNet Model(Advanced)] 노드에서 아래와 같이 control_v11p_sd15_openpose.pth를 선택합니다.

참조용 비디오 올리기
한 사람이 나오는 비디오라면 어떤 비디오도 괜찮습니다. 아래는 원본 글에 있는 비디오입니다. 이 비디오를 사용해 테스트하셔도 됩니다.
https://stable-diffusion-art.com/wp-content/uploads/2023/10/man_dance_2to3_24fps_9s.mp4
아래 그림과 같이 원하는 비디오를 [Load Video(Upload)] 노드에서 맨아래에 있는 [choose file to upload] 버튼을 눌러 선택합니다.

비디오 생성
이제 [Queue Prompt]를 클릭하면 비디오가 생성되기 시작합니다. 물론 시간이 엄청 많이 걸립니다. 맨처음에는 [Preview Image] 노드에서 잠깐 랙이 걸리는 듯 하다가, [DWPreprocessor]에서 한참 서 있는 듯하다가(저는 이상한 에러메시지(아래를 보세요)가 나와서 아예 멈춘 줄 알고 두번이나 ComfyUI를 새로 시작했었습니다) KSampler 노드가 아주 많은 시간을 소요합니다.
[AnimateDiffEvo] - WARNING - ffmpeg could not be found. Outputs that require it have been disabled
F:\comfyUI\ComfyUI_windows_portable\ComfyUI\custom_nodes\comfyui_controlnet_aux\src\controlnet_aux\dwpose\__init__.py:175: UserWarning: Currently DWPose doesn't support CUDA out-of-the-box.
warnings.warn("Currently DWPose doesn't support CUDA out-of-the-box.")
제 컴은 3070 8GB인데, 대략 30 분 정도 걸린 듯 싶네요. KSampler가 다 끝나면 아래와 같이 비디오가 생성됩니다.

아래가 생성된 영상입니다. 흠... 영상 속도가 많이 느려졌네요. 위에서 frame_rate 를 크게 바꿔야 할 것 같습니다.
 |
아래는 모델을 "Anyting V5"로 바꾸고 frame_rate를 24로 올린 결과입니다.

생성된 영상 품질 검사
이 워크플로에는 중간단계에서 생성된 프리뷰 이미지가 3군데 있습니다. 첫번째는 비디오에서 추출한 원본 프레임, 두번째는 이 프레임 이미지로 부터 추출한 openpose 콘트롤 이미지, 세번째는 생성된 이미지 프레임입니다. 이 이미지들을 살펴보면서 잘못된 부분이 있는지 확인해보면 최종 영상에서 문제가 되는 부분들을 확인할 수 있습니다.
하지만... 예를 들어 Openpose에서 자세를 잘못 추출했다면 어떻게 수정해야 하는지 잘 모르겠네요. 최종이미지도 마찬가지로 잘못된 것만 새로 생성하는 방법이 있는지 잘 모르겠습니다. 제가 만든 워크플로가 아니라 가져온 거라서 이해가 안되는 부분이 많거든요.
 |
 |
 |
생성 설정 변경
다른 비디오를 생성하려면 Primitive (Seed) 노드에서 씨드 값을 바꿔주면 다른 비디오가 생성됩니다. 물론 체크포인트 모델을 바꾸면 당영히 다른 비디오가 생성되고요.

프롬프트도 바꿔줄 수 있습니다. 이 워크 플로에서는 "High detail, girl, short pant, t-shirt, sneaker"라는 프롬프트와 "(bad quality, worst quality:1.2), hat, temple"라는 부정적 프롬프트를 사용했는데, 원하는 어떤 프롬프트도 사용할 수 있습니다.
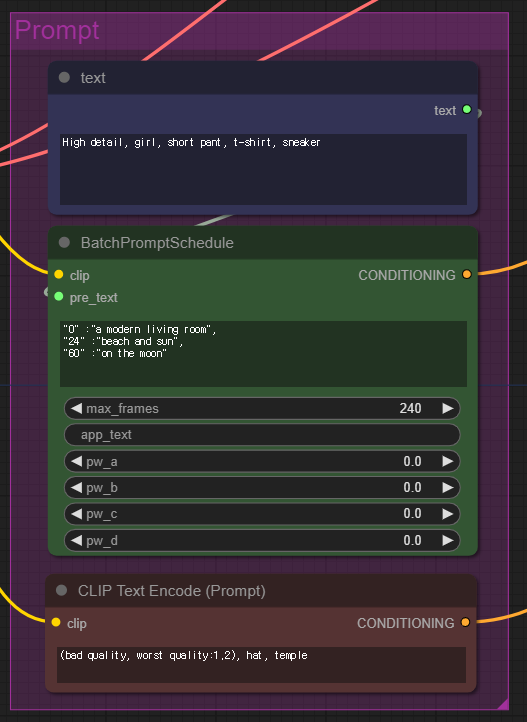
그리고 가운데 있는 [Batch Prompt Schedule]은 위의 기본 프롬프트와 함께 사용되며, 시간에 따라 프롬프트를 바꾸는 역할을 합니다. 예를 들어 0~23 프레임에서는 "High detail, girl, short pant, t-shirt, sneaker, a modern living room"이라는 프롬프트로 이미지가 생성되며 24~59 프레임에서는 " High detail, girl, short pant, t-shirt, sneaker, beach and sun"이라는 프롬프트가 적용됩니다. 이 [Batch Prompt Schedule] 노드 덕분에 배경이 바뀌는 것입니다.
[Load Video (Upload)] 노드에서는 입력 비디오를 바꾸는 것 뿐 만 아니라, 다른 설정도 바꿀 수 있습니다. "frame_load_cap" 설정은 비디오에서 추출하는 최대 프레임 수를 뜻하며, "select_every_nth"는 프레임을 얼마나 자주 추출할 지를 설정합니다. 여기에서 처럼 2로 설정하면 하나씩 건너뛰고 추출하므로 추출된 프레임 수가 절반으로 줄어들게 됩니다.

좋은 영상을 만들기 위한 팁
얼굴
원래 SD1.5에서는 얼굴의 크기가 작으면 잘 생성해 내지 못합니다. 따라서 얼굴이 작은 비디오의 경우에는 (위에서 생성한 결과물 처럼) 얼굴이 이상해지기 쉽습니다.

이럴 때 비디오의 크기를 키우면 보다 얼굴이 자연스러워집니다. 아마도 AfterDetailer를 사용하면 이 문제를 해결할 수 있을 것 같은데... 아직까지 저는 실력이 안되네요~

비디오 생성 속도를 빠르게
속도를 빠르게 하는 방법은 추출하는 프레임 수를 줄이는 방법뿐이 없습니다. 즉, [Load Video (Upload)] 노드에서 "select_every_nth"를 2~3 정도로 두면 움직임은 좀 덜 부드럽지만 생성 속도는 빨라지게 됩니다.
체크포인트 모델 선택
AnimateDiff 가 모든 체크포인트에 대해 좋은 품질을 만드는 것은 아닙니다. 어떤 체크포인트 모델은 잘 되고, 어떤 모델에서는 안되는 경우가 있으니 잘 생성이 안되면 다른 모델로 바꿔 생성해보는 게 좋을 수 있습니다.
프롬프트
AnimateDiff 가 모든 키워드를 잘 이해하는 것은 아니기 때문에, 이상하게 생성된다면 키워드를 검토해보시는 게 좋습니다. 무엇보다 이 예처럼 짧고 간단한 프롬프트로 시작하는 게 좋고, 필요에 따라 하나씩 추가해가는 게 좋습니다.
다른 콘트롤넷
이 글에서는 Openpose 콘트롤넷을 사용했는데, Openpose의 경우 사람의 자세만 추출하므로, 배경을 마음대로 바꿀 수 있는 장점이 있습니다.
반면 동일한 배경을 사용하고 싶다면, Line art와 같은 선을 추출하는 콘트롤넷 모델을 사용할 수 있습니다. 아래는 그 예입니다. (제가 생성한 것이 아니라, 원본 글에 있는 동영상입니다). 이 워크플로는 여기를 다운로드 받으시면 됩니다.

이상입니다.
민, 푸른하늘
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 초보자 가이드
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기