ComfyUI는 다재다능한 오픈소스 이미지 생성형 AI인 스테이블 디퓨전을 위한 GUI중 하나입니다. 원래는 AUTOMATIC1111이 훨씬 더 많이 사용되었지만, 여러가지 워크플로를 쉽게 생성하고 변경할 수 있어서 사용자가 급격하게 늘어나는 중입니다.
다만, ComfyUI는 스테이블 디퓨전의 기술적인 내용과 많은 관련이 있어서 사용하기가 쉽지 않습니다. 요즘 들어 ComfyUI 에 관한 글이 더 많아졌는데, 사용법이 잘 정리된 문서가 없어서 고민하던 중이었는데, 이 투토리얼은 아주 기초적인 내용부터 고급 사용법까지 아우르는 여러가지 내용을 담고 있습니다. 처음부터 따라해보면 ComfyUI를 좀 더 확실하게 이해하실 수 있게 될 것입니다.
이 투토리얼은 Open.ai 의 ComfyUI Academy 에 올려진 11개의 유튜브 내용을 나름 편집해 정리한 것입니다. 따라서 이 글을 읽으신다면 해당 유튜브를 보면서 읽는 것을 추천드립니다.
이 튜토리얼은 모두 세편으로 이루어져 있습니다.
- ComfyUI 튜토리얼-1 : 유튜브 1~4편
- ComfyUI 튜토리얼-2 : 유튜브 5~8편
- ComfyUI 튜토리얼-3 : 유튜브 9~11편
아래는 이 글의 목차입니다.
- ComfyUI 아카데미 소개
- 레슨 1: ComfyUI 사용하기 기본(Using ComfyUI, EASY basics)
- 레슨 2: 멋진 ComfyUI txt2img 비법
- 레슨 3: 잠재 이미지 확대(Latent Upscaling)
- 레슨 4: Image to Image 생성
ComfyUI 아카데미 소개
Openart.ai는 이미지 생성형 AI와 관련해 제가 좋아하는 사이트중 하나입니다. 그런데 얼마전 사이트가 전면적으로 개편되면서, ComfyUI 를 기본으로 사용하는 것처럼 보입니다. 아직 세세하게 살펴본 건 아니지만요.
그중에서 ComfyUI Academy라고, ComfyUI 사용법을 알려주는 코너가 생겼습니다. 현재 총 11개의 유튜브가 올려져 있는데, 기본적인 내용이 많기는 해도 중간중간 쓸만한 정보들이 포함되어 있어서 소개드리려고 합니다.
다만, 유튜브 내용을 모두 정리하는 것은 별로 필요가 없을 듯하고, 제가 잊어버리지 않도록 정리하는 차원이니, 관련 내용을 원하시면 직접 사이트를 방문하시는 게 좋을 것 같습니다.
레슨 1: ComfyUI 사용하기 기본(Using ComfyUI, EASY basics)
유튜브는 여기를 보세요.
아래는 아름다운 산이 있는 풍경을 생성하는 가장 기본적 워크플로입니다.
모델 : dreamshaper_8
프롬프트 : beautiful landscape, digital art, mountains

ComfyUI_Manager 설치
ComfyUI를 사용할 때 반드시 설치하여야 할 커스톰 노드가 있습니다. ComfyUI_Manager입니다. 설치하는 방법은 여기를 읽어보시면 됩니다. 설치가 되면, 아래와 같이 [Manager]라는 버튼이 추가됩니다.

[Manager] 버튼을 누르면 아래와 같이 많은 명령이 나타납니다.

이중에서 가운데 위에 있는 [Install Custom Nodes]를 누르고 아래의 커스톰 노드를 설치해줍니다. 이들 노드는 아주 널리 사용되므로 설치해 주시는 게 좋습니다.
- ComfyUI Impact Pack
- ComfyUI Inspire Pack
- Efficiency Nodes for ComfyUI version 2.0+
- UltimateSDUpscale
- ComfyUI_Comfyroll_CustomNodes
ComfyUI Mananger에 대한 좀더 자세한 내용은 ComfyUI를 위한 유용한 정보를 읽어보시기 바랍니다.
워크플로 생성시 참고사항
아래는 워크플로를 생성할 때 몇가지 참고할 사항입니다.
- ComfyUI화면을 잘 보면 흐릿하게 파란색 사각형이 있는데, 여기가 워크플로를 불러올 때 화면에 나타나는 부분입니다. 따라서 가급적 그 내부에 노드를 생성하는 게 좋습니다. 아주 큰 워크플로라면 핵심되는 부분이라도 파란색 사각형에 넣어주세요.
- 복잡한 워크플로일 경우, 노드의 이름을 바꿔서 그 노드가 무엇을 하는지 기록해 두는 게 좋습니다. 노드를 우클릭하고 Title을 선택하면 이름을 변경할 수 있습니다. 이때, 원래 노드 이름은 그대로 두고, 뒤쪽에 원하는 내용을 넣어주는 게 좋습니다.
- 또한 캔버스에서 우클릭을 하고 [Add Group]을 한 후, 비슷한 역할을 하는 것들을 한꺼번에 그룹으로 묶어주면 기억하기 좋고, 이동할 때도 한꺼번에 이동시킬 수 있습니다. 아울러 그룹을 우클릭하고 [Bypass Group Nodes]를 누르면 해당 그룹속에 속한 모든 노드가 보라색으로 변하면서 마치 없는 것처럼 건너뛰게 됩니다. 이를 취소할 때는 [Set Group Nodes to Always]를 선택해주면 됩니다.
 |
 |
- 노드를 입력할 때 가장 쉬운 방법은 화면을 우클릭하면 나오는 창에서 원하는 노드 이름을 입력하는 것입니다. 예를 들어 아래는 KSampler 노드를 찾는 방법입니다.

- 또한 입력 및 출력 슬롯을 클릭해서 드래그한 뒤 놓으면 그 노드에 연결할 수 있는 노드 목록이 나타나니 쉽게 노드를 입력할 수 있습니다.

Reroute 노드
위와 같이 입출력 슬롯을 Drage하면 맨위에 항상 Reroute라는 노드가 나타나는데, 이것을 잘 활용하면 워크플로를 깔끔하게 정리할 수 있어 좋습니다. 아래와 같이 여기저기 길게 연결해야 할 경우, Reroute를 활용하면 훨씬 워크플로를 이해하기 쉽게 만들 수 있습니다.

특히, 아래와 같이 여러가지 작업을 바꿔가며 수행할 경우, Reroute 노드를 사용하면 한번만 연결해주면 되므로 편리합니다.
Reroute 노드의 경우, 원래 위와 같은 이름이 표시되지 않지만, 우클릭을 한다음 [Show Type]을 선택하면 위와 같이 Reroute 노드에 포함된 내용이 표시됩니다. 그런데 이렇게 나온 이름 말고 다른 이름으로 바꾸고 싶다면, Reroute 노드의 오른쪽 슬롯(분홍색 점)을 우클릭하여 [Rename]을 선택하시면 됩니다.
입력슬롯과 입력위젯 바꾸기
거의 모든 노드는 여러개의 슬롯(아래 빨간색 박스)과 입력위젯(파란색 박스)로 구성됩니다.

이들 입력위젯와 입력슬롯은 언제든지 바꿀 수 있습니다. 해당 노드를 우클릭하면 긴 메뉴가 나오는데, Convert... 로 시작되는 항목을 클릭하면 됩니다.

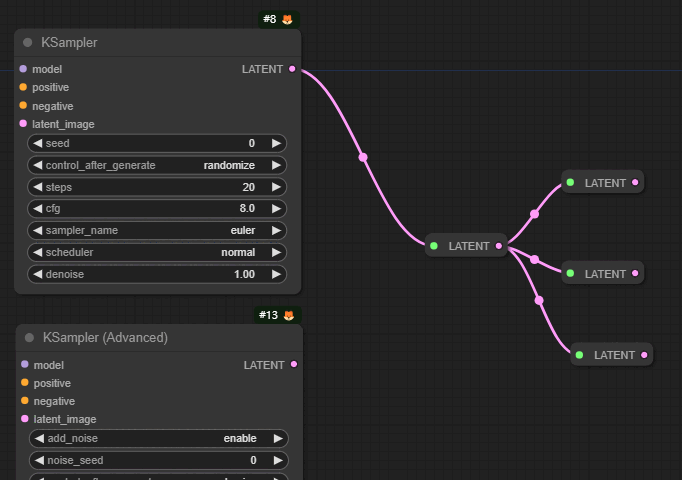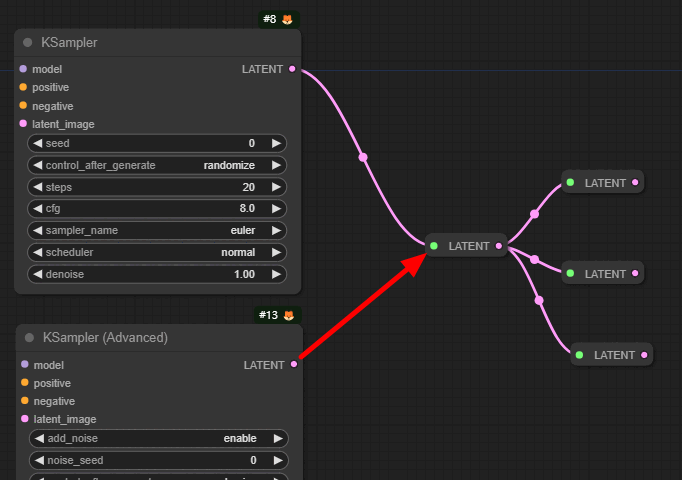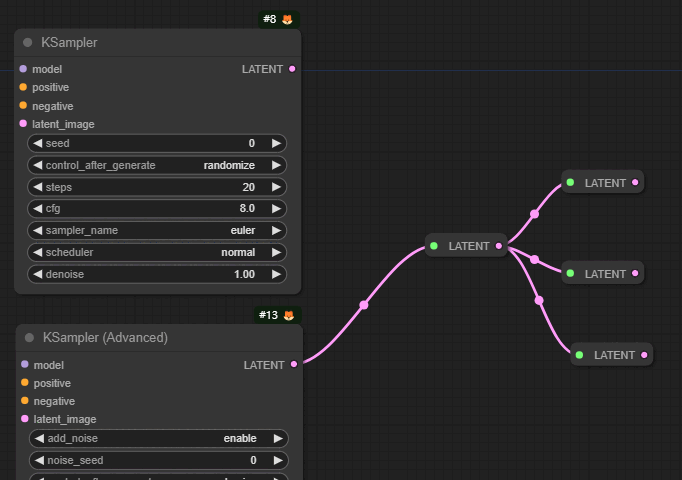
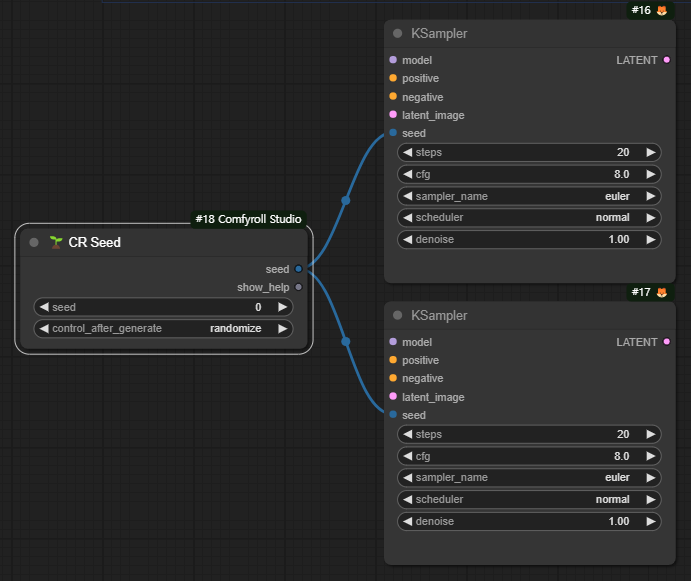
특히, 아래와 같이 같은 값을 여러개의 노드에서 사용할 때 유용합니다. 아래는 두개의 KSampler 노드가 동일한 씨드값을 사용하도록 구성한 예입니다.
레슨 2: 멋진 ComfyUI txt2img 비법
유튜브는 여기를 보세요.
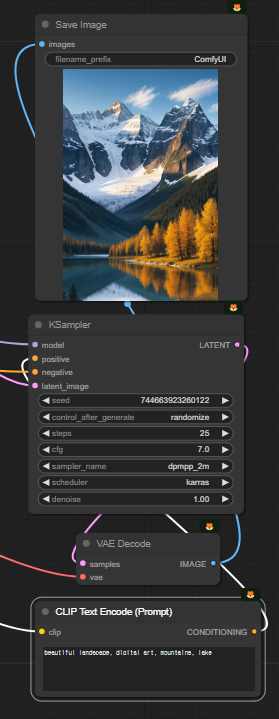
아래는 아름다운 산이 있는 풍경을 생성하는 가장 기본적 워크플로입니다. 위에 있는 워크플로에서 맨 오른쪽의 [Preview Image] 노드를 [Save Image]노드로 바꿨고, 아래쪽에 [VAE Decode]노드에서 별도의 VAE를 가져오도록 [Load VAE] 노드를 추가하였습니다.
참고로 이 워크플로는 그냥 다운로드 받아서 ComfyUI 화면에 Drag&Drop하면 사용할 수 있습니다.
모델 : dreamshaper_8
프롬프트 : beautiful landscape, digital art, mountains
샘플링 단계: 25
샘플러 : DPM++ 2M (dpmpp 2m)
스케줄러 : karras

메뉴에서 [Queue Prompt] 버튼 바로 아래에 있는 "Extra options"를 누르면 아래와 같이 펼쳐지는데, 몇번 수행할지(Batch count)를 지정할 수 있습니다. 또 Auto Queue를 누르면 정지시키기 전까지 계속 반복해서 이미지를 생성합니다. 중간에 프롬프트나 매개변수를 변경시켜보면서 어떤 효과가 있는지 비교하면서 계속 고쳐나갈 때 유용합니다.
비슷한 이미지 동시 생성
위의 워크플로는 멋진 산 이미지를 한장 생성하는데, 여러장의 사진을 동시에 생성하도록 수정해 보겠습니다. 우선 아래와 같이 [Save Image], [KSampler], [VAE Decode], [CLIP Text Encode(Prompt]노드를 나란히 세운뒤,Control을 누른상태에서 마우스로 이 네 개의 노드가 들어가도록 사각형 범위를 지정하면 노드들이 한꺼번에 선택됩니다. 선택하면 노드 주변에 흰색 박스가 나타나죠.
 |
 |
그 다음 Cntrl+C를 눌러서 복사를 하고, Cntl+Shift+V를 누르면 이 네 개의 노드, 그리고 이 노드와 연결된 링크가 한꺼번에 복붙됩니다. 그 다음 Shift를 누른상태에서 노드의 제목을 드래그하면 4개의 노드를 한꺼번에 이동시킬 수 있습니다. 아래는 이렇게 2번 반복한 결과입니다. 보시는 것처럼, 노드 간의 링크도 함께 복사가 됩니다.

그다음 아래쪽의 긍정적 프롬프트를 아래와 같이 바꿔줍니다.
- beautiful landscape, digital art, mountains, lake
- beautiful landscape, at night, digital art, mountains, lake
- beautiful landscape, at sunset, digital art, mountains, laek
이제 [Queue Prompt]를 누르면 세장의 멋진 산과 호수가 있는 풍경이 생성됩니다. 하나는 낮, 하나는 밤, 하나는 석양 풍경으로요.

아래는 이 워크플로를 사용해 생성한 결과 이미지입니다.
 |
 |
 |
ControlNet을 사용한 개선
위의 세 이미지는 그냥 다른 이미지 입니다. 다른 풍경이죠. 이제 동일한 풍경인데 빛 환경만 바뀌도록 이미지를 생성할 수 있도록 워크플로를 변경시켜 보겠습니다.

이 워크플로는 첫번째 사진을 생성한 후, 이 사진을 참조하여 콘트롤넷 Depth 맵을 만들고, 두번째 세번째 이미지에 적용하는 방법입니다.
해당 내용은 아래와 같습니다. 먼저 처음 생성된 이미지에서 이미지를 가져다가 [ControlNet Preprocessor] 노드에서 "depth_midas" 전처리기를 수행해 Depth map을 생성합니다([Preview Image] 노드에 이 Depth map이 나타납니다).
다음으로 이 Depthmap과, 이 Depth map을 처리해주는 콘트롤넷 모델 control_v11... .pht를 사용해 [Apply ControlNet]노드를 적용합니다. 이제 프롬프트 뿐만 아니라, 첫번째 이미지의 Depth map도 조건부여(conditioning)으로 사용되는 것입니다. 이로 인해 두번째/세번째 프로세스에서 생성되는 결과가 첫번째 이미지와 거의 비슷하게 됩니다.

아래는 이렇게 해서 생성한 결과입니다(중간 이미지의 프롬프트에는 "milkyway"를 하나 더 추가했습니다). 보시는 것처럼 거의 동일한 풍경이라는 것을 알 수 있습니다.
 |
 |
 |
최종 워크플로
아래는 기본적으로 동일한 기능을 하는 워크플로입니다. 거의 위치만 바꿨다고 보시면 되는데, 다만, 프롬프트를 공통 프롬프트와 개별적으로 적용하는 프롬프트를 별도로 분리해서 입력하고 이를 연결(Concatenate)한 워크플로입니다.

프롬프트는 아래와 같습니다. 첫번째는 beautiful woman, 두 번째는 beautiful asian woman, 마지막은 beautiful black African woman 으로 바꿨습니다.
프롬프트: beautiful woman wearing jeans and a white shirt, standing in a park, digital paiting, masterpiece highly detailed
 |
 |
 |
보시는 것처럼 거의 동일한 배경, 거의 동일한 자세 및 복장으로 인종만 다르게 생성되었습니다.
레슨 3 : 잠재이미지 확대(Latent Upscaling)
유튜브는 여기를 보세요~
잠재 이미지(Latent image)이란 간단히 말해서 "일반 이미지를 좀더 작은 크기로 다른 방법으로 표현한 이미지"라고 할 수 있습니다. 사실 스테이블 디퓨전은 저장공간을 줄이고 계산 속도를 빨리한 이미지 생성모델로, 그 기반이 잠재 이미지라고 할 수 있습니다. 보다 자세한 내용은 Stable Diffusion에 관한 기본적인 이론을 읽어보시기 바랍니다.
아래는 파란 양복을 입은 남성을 생성하는 기본적인 워크플로입니다.
모델 : dreamshape_8
프롬프트: portrait of a beautiful man, blue suite, park in background, ((masterpiece, best quality))

아래는 이 워크플로로 생성된 이미지입니다. 좌측 이미지는 문제가 없지만, 우측 이미지를 잘 보시면 좌우 눈 크기가 다릅니다. 이처럼 인물이 작게 생성되면 (작을 수록) 얼굴이 정상적으로 생성되지 않는 경우가 많습니다. 원래 작은 얼굴을 생성하도록 학습되지 않았기 때문입니다.
 |
 |
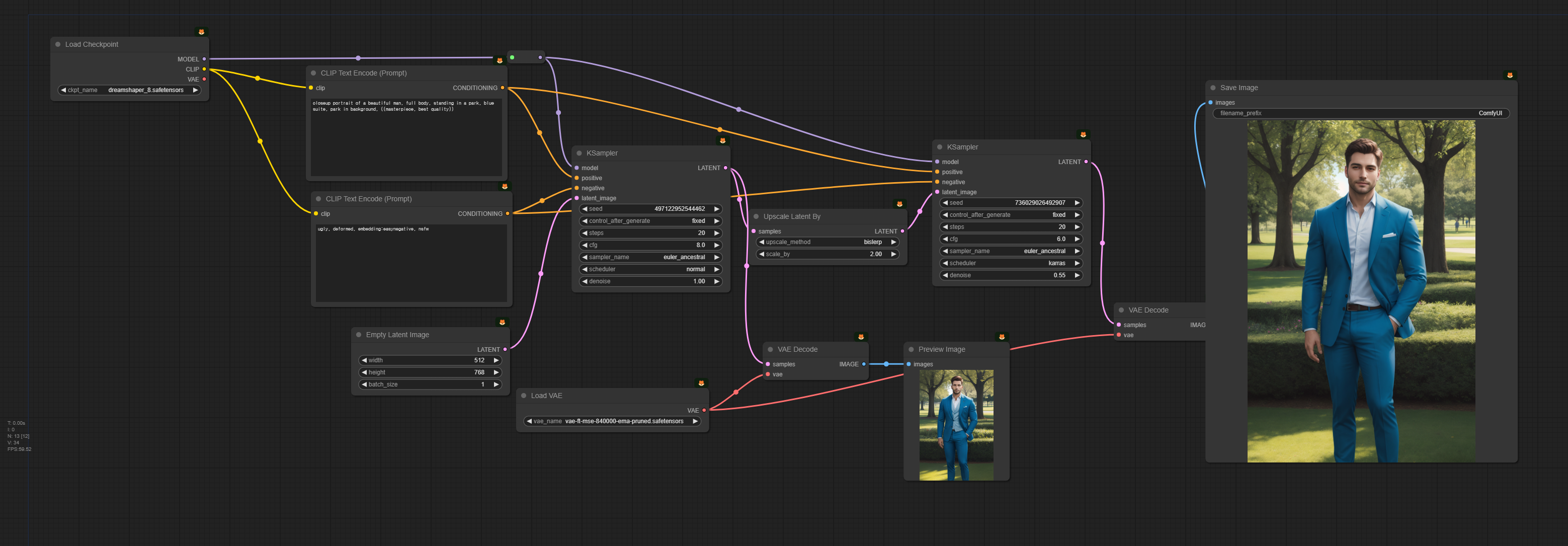
이러한 경우, 이미지를 확대(Upscale)하여 해결할 수 있습니다. 아래는 잠재 이미지를 확대하는 프로세스를 추가한 워크플로입니다.
이 워크플로를 작동시키면 아시겠지만, [KSampler] 노드만 단독으로 돌렸을 때보다, 속도가 4배정도 느려집니다. 이미지가 그만큼 크기 때문이죠. 이런 경우, 메뉴에서 "View Queue"를 선택해 아래와 같이 실행되는 상태를 보면서 [Preveiw] 이미지가 마음에 안들면 중간에 실행중인 프로세스를 중단시키면 시간을 절약할 수 있습니다.

이 워크플로가 위쪽 워크플로와 달라진 부분은 아래와 같습니다. 원래는 [KSampler] 노드 뒤에 바로 [VAE Decode] 노드를 붙여서 이미지를 생성했는데, [Upscale Latent By] 노드를 넣어 잠재 이미지를 2배로 확대한 후, 다시 [KSampler] 노드를 수행하는 방식으로 바꾼 것입니다.

[Upscale Latent By] 노드는 단순히 이미지를 원하는 배율(scale_by)로 확대시켜주는 역할을 합니다. "upscale_method"를 확대하면서 생기는 빈 공간을 채우는 방식을 말하지만, 사실 바로 다음에 [KSampler] 노드로 다시 샘플링을 하므로 별 의미는 없습니다.
뒤쪽 [KSampler]는 기본적으로 동일한 모델, 동일한 프롬프트를 사용하여 이미지를 생성합니다. 하지만 원한다면 모델이나 프롬프트를 다르게 바꿔서 변화를 추구할 수도 있습니다.
한가지 중요한 사항으로서 맨 아래에 있는 "denoise"는 왼쪽(1.0)과는 달리 작은 값으로 설정되어 있다는 점입니다. 이 매개변수는 "잡음 제거 강도(denoising strength)"로서 0으로 설정할 경우 잡음이 추가되지 않아 입력된 이미지를 그대로 사용하며, 1일 경우에는 잡음이 최대치로 추가되어, 잠재 이미지가 완전한 무작위 텐서(random tensor), 즉 입력 이미지가 완전히 무시되므로 0과 1 사이에서 적절히 설정해야 합니다. 이 경우, 입력된 이미지는 작은 이미지를 뻥튀긴 상태이므로, 0으로 두고 생성하면 이미지가 아래와 같이 흐릿하게 생성되거나 네모난 모양이 나타나게 됩니다.

아래는 이렇게 Upscale 프로세스를 추가해서 생성한 이미지(오른쪽)를 원본과 비교한 결과입니다. 얼굴이 훨씬 사실감 있게 표현되었음을 알 수 있습니다.
 |
 |
이렇게 Upscale을 적용하면 전과 후 이미지가 완전히 동일하지 않습니다. 위의 사진에서는 얼굴이 달라졌을 뿐 아니라, 양복 오른쪽 단추구멍 주변도 달라졌으며, 왼쪽의 하늘색 조끼가 사라졌음을 알 수 있습니다. 즉, 단순 확대가 아니라, 두번째 [KSampler]노드를 통과하면서 이미지가 재 구성되고 이때 여러가지 세세한 부분이 수정됩니다.
특히, 위의 [Upscale Latent By] 노드와 [KSampler] 노드를 추가한 이미지 확대 프로세스는 [UltimateSDUpscale] 노드를 사용해 훨씬 더 큰 크기로 확대하기 전에 사전 작업으로 사용하면 좋다고 합니다. [UltimateSDUpscale] 노드는 대부분 잡음제거 강도를 낮게 설정해서 원본과 비슷하게 생성하는 경우가 많은데, 원본에 오류가 있을 경우에는 이 오류가 그대로 남기 때문이라네요. [UltimateSDUpscale] 노드 사용법은 나중에 다시 설명하겠습니다.
레슨 4 : Image to Image 생성
유튜브는 여기를 보세요~
기본 img2img
아래는 기본 Img2img 워크플로입니다.

img2img 워크플로가 txt2img 워크플로와 다른 점은, txt2img에서는 [Empty Latent Image] 노드로부터 그냥 무작위 이미지를 소스로 사용하지만, img2img에서는 [Load Imag]로부터 이미지를 입력받은 후, 이를 [VAE Encode] 노드에서 잠재이미지를 변환해 이를 소스로 사용한다는 점만 다릅니다.
이를 통해, txt2img에서는 어떤 이미지가 생성될지 전혀 모르지만, img2img에서는 전체적인 구도와 색을 지정할 수 있다는 장점이 있습니다. (참고로 이 워크플로에서는 주인장이 대충 그린 이미지를 사용했지만, 품질이 좋은 이미지를 입력으로 사용해도 물론 아무 문제 없습니다. img2img 를 거치면 원본 이미지와 색과 구도가 비슷하지만 완전히 다른 이미지가 생성될 뿐입니다.)
아래는 이 워크플로에 사용되는 이미지입니다. 물론 다른 이미지를 사용하거나 직접 그려서 입력하셔도 됩니다.

아래는 프롬프트입니다. 잘 살펴보면, 하얀 날개, 빨간색 망토 스타일의 옷 (toga), 그리고 배경에 도시를 지정해서 위의 그림과 얼추 비슷함을 알 수 있습니다. 이처럼 img2img에서는 AI가 프롬프트와 입력된 이미지를 해석해서 가능한한 맞추기 때문에 프롬프트와 입력 이미지를 잘 맞출 수록 좋은 결과가 만들어집니다.
프롬프트: beautiuful female angel with long blond hair, with feathery white wings, wearing a red toga, city in the background ((masterpiece, best quality))
img2img에서 한가지 주의할 점은 KSampler 노드에서 잡음 제거 강도(denoise)를 높게, 하지만, 1은 아니게 설정해야 한다는 것입니다. 잡음 제거 강도를 높게 할 수록 원본 이미지는 무시하게 되지만, 1로 설정하면 입력된 이미지를 완전히 무시하기 때문에 그냥 txt2img와 동일하게 되기 때문입니다.

아래는 이 워크플로를 사용해 생성한 결과입니다. 보시는 것처럼, 모두 다르기는 하지만 구도는 비슷함을 알 수 있습니다. 특히 천사의 자세의 경우에는 아주 제 멋대로인데, 이는 위의 조건부여에 자세에 관한 내용이 하나도 없기 때문입니다(물론 원한다면 콘트롤넷을 추가할 수도 있고, 입력 이미지를 더 자세하게 그려넣는 방법도 있습니다).
 |
 |
 |
 |
아래는 동일한 워크플로에서 프롬프트만 바꿔서 생성한 결과입니다.
프롬프트 : beautiful female cyborg with feathery wings and red armor, city in the background ((masterpiece, best quality))
 |
 |
이렇게 생성한 이미지중에서 위의 오른쪽 이미지가 마음에 드는데, 배 근육등 마음에 안드는 점이 있다면, 이 이미지를 입력이미지로 대체해서 새로 생성할 수 있습니다. 아래는 이렇게 생성한 결과입니다. 그런데 생성된 결과가 원본보다 못하네요. ㅎㅎ
 |
 |
 |
 |
고급 img2img
아래는 여기에서 사용하는 워크플로입니다.

이 워크플로에서는 아래의 이미지를 입력으로 사용했습니다.

그런데 이 이미지를 입력으로 사용해서 생성하면 아래와 같이 멋지기는 하지만, 위쪽은 적황색, 아래쪽은 파란색이 지배적인 이미지만 만들어집니다.
 |
 |
 |
위의 워크플로는 이를 보완하여 좀더 다채로운 색이 나타나도록 하기 위해 아래와 같이 입력된 이미지와, [Empty Latent Image]로 생성한 무작위 이미지를 [Latent Blend]노드로 합친 다음 이를 입력 이미지로 사용하였습니다(맨왼쪽과 맨 오른쪽은 겉보기엔 큰 차이가 없지만, 오른쪽엔 무작위 잡음이 섞여 있습니다)

아래는 이 워크플로로 생성한 결과입니다. 보시는 것처럼 전체적으로 위쪽은 적황색, 아래쪽은 파란색이 지배적이기는 하지만, 색감이 훨씬 풍부해졌음을 알 수 있습니다.
 |
 |
이제 그래디언트 이미지를 바꿔주기만 하면 다양한 이미지를 얻을 수 있습니다. 아래의 그래디언트 이미지를 사용하면...

아래와 같은 이미지가 생성됩니다. 캬~~ 분위기 좋네요~~ㅎ
 |
 |
이 워크플로처럼 사용한다면, 전체적인 색감을 훨씬 더 쉽게 제어할 수 있어서 유용할 것 같네요.
이상입니다. 이 글은 OpenArtFlow 의 ComfyUI Academy에 있는 유튜브 1~4편을 사용하여 제 마음대로 편집하여 작성하였습니다.
민, 푸른하늘
====
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기