AI 이미지 생성속도를 올리고 싶으신가요? TeaCache를 사용하면 품질에는 거의 영향을 미치지 않으면서도 디퓨전 모델의 속도를 올릴 수 있습니다. 구현하기도 쉽고, 무엇보다 Flux와 Hunyuan Video와 같은 최신 이미지/비디오 생성모델에 적용할 수 있다는 장점이 있습니다.
이 글에서는 TeaCache의 작동원리와 함께, Flux 및 HunyuanVideo에 적용하는 워크플로를 소개시켜드립니다.
소프트웨어
이 글에서는 스테이블 디퓨전용 GUI중에서도 제일 강력한 ComfyUI를 사용합니다. ComfyUI가 처음이시라면, 설치 및 기본 사용방법 및 초보가이드를 확인하시기 바랍니다.
TeaCache 란?
Timestep Embedding Aware Cache(TeaCache)는 디퓨전 트랜스포머(DiT, Diffusion Transformer) 모델의 샘플링 단계 속도를 올립니다. 이는 가장 새로운 디퓨전모델(예: Flux 및 HunyuanVideo)이 사용하고 있는 아키텍처입니다.
농축(distillation)과는 달리, TeaCache는 새로운 모델을 훈련시킬 필요가 없습니다. 따라서 기존에 사용하던 LoRA와 ControlNet을 모두 TeaCache와 함께 사용할 수 있습니다.
농축 모델이 빠른 이유는 품질을 상당히 희생하면서 샘플링 단계를 줄이기 때문입니다. 반대로 TeaCache는 샘플링 단계는 그대로 유지하여 품질을 보전합니다. cache parameter를 적절히 조절하면 품질 저하없이 상당한 속도 향상을 이룰 수 있습니다. 품질과 속도 사이에 유연성이 있다는 것은 매우 뛰어난 특성입니다. 기업에서는 간단한 방법만으로 추론 비용을 절반으로 줄일 수 있습니다.
TeaCache의 작동 원리
TeaCache 는 일부 신경망 블록이 샘플링동안 많은 역할을 하지 않는다는 관찰을 활용한 것입니다. 연구자들은 디퓨전 모델이 앞쪽 샘플링 단계에서 이미지의 개략적인 윤곽을 생성하고, 나중 단계에서 세부 사항을 채운다는 것을 알아차렸습니다.

디퓨전 트랜스포머 모델은 여러개의 트랜스포머 블록으로 구성됩니다. 앞쪽 트랜스포머 블록은 윤곽을 그리고, 뒷쪽 트랜스포머 블록은 세부사항을 그립니다. 윤곽은 나중 단계에서 변경되지 않으므로, delta-DiT 기법은 모든 단계에서 새로 계산을 하는 대신 앞쪽 블록의 생성물의 캐시를 사용하여 샘플링 단계의 속도를 올립니다.
TeaCache는 여기에서 한단계 더 나갑니다. 샘플링 동안 언제 캐시를 사용할지를 지능적으로 결정하는 것입니다. 현재의 입력이 생성된 캐시와 비슷할 경우에 생성물 캐시를 사용함으로써, 입력이 상당히 다를 때만 캐시를 새로 계산하는 것입니다. 사용자들은 얼마나 자주 캐시를 재 계산해야 할지를 제어할 수 있습니다.
Flux에서 TeaCache 사용하기
TeaCache 의 매개변수 delta를 사용하여 캐싱을 제어합니다. 0은 캐싱을 끄는 것입니다. 이 값을 높일 수록 캐시 재생성이 덜 발생하여 샘플링이 빨라집니다.
아래는 RTX3070에서 Flux GGUF 모델에 적용하였을 경우의 생성 시간입니다.
| delta 임계값 | 이미지 생성 시간 |
| 0.0(off) | 78초 |
| 0.2 | 63초 |
| 0.4 | 39초 |
| 0.6 | 31초 |
| 0.8 | 27초 |
| 1.0 | 24초 |
 |
 |
 |
| 0.0 | 0.2 | 0.4 |
 |
 |
 |
| 0.6 | 0.8 | 1.0 |
delta 임계값을 0.2~0.4 정도로 설정하면 이미지의 변화가 거의 없습니다. 그나마 변화는 대부분 주 객체가 아닌 배경에서 일어난다는 게 흥미롭습니다.
0.6 부터는 결함이 발생하기 시작합니다(손을 살펴보세요). 1.0으로 설정하면 이미지가 상당히 뭉게집니다.
따라서 delta를 0.4 정도로 두면 적당할 것 같습니다. 이미지 품질이 저하되지 않으면서도 속도는 거의 2배가 빨라지니까요(78초 -> 39초)
1 단계: Flux1 dev GGUF 모델 다운로드
여기에는 간단하게만 정리했습니다. 더 자세한 내용은 이 글을 참고하세요.
GGUF unet 모델
아래 사이트에서 파일을 다운로드 받아, ComfyUI\models\unet 폴더에 넣어줍니다.
여기에는 아주 많은 파일이 들어있는데, 다 받을 필요는 없습니다. 저는 f16, Q8_0, Q3_K_S 등 세가지 종류만 받았습니다.
CLIP 모델
아래 사이트에서 파일을 다운로드 받아, ComfyUI\models\clip 폴더에 넣어줍니다. 마찬가지로 다 받을 필요가 없고, 다운로드 받은 unet과 동일한 버전만 받으시면 됩니다.
vae 모델
마지막으로 vae 모델이 필요합니다. 여기에 들어가서 다운로드 받은뒤, ComfyUI_windows_portable\ComfyUI\models\vae 폴더에 넣어주시면 됩니다. 원하시면 구분하기 쉽도록 파일명을 flux-dev-gguf.safetensors 로 변경해주시면 좋습니다.
2단계: 워크플로 불러오기
아래의 JSON 파일을 ComfyUI에 불러옵니다. 좌측위의 Workflow->Open 메뉴를 사용하면 됩니다.
이 워크플로를 불러오면 대부분 오류가 발생할 것입니다. 그러한 경우, 다음과 같은 작업이 필요합니다.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
4 단계: 이미지 생성
이제 [Queue] 버튼을 누르면 이미지가 생성됩니다.

Hunyan Video 에서 TeaCache 사용하기
ComfyUI-HunyuanVideoWrapper 커스톰 노드를 사용하면, TeaCache가 Hunyuan Video를 기본적으로 지원합니다. 아래와 같이 [HunyuanVideo TeaCache] 노드를 [HunyuanVideo Sampler]노드와 연결해주기만 하면 됩니다.
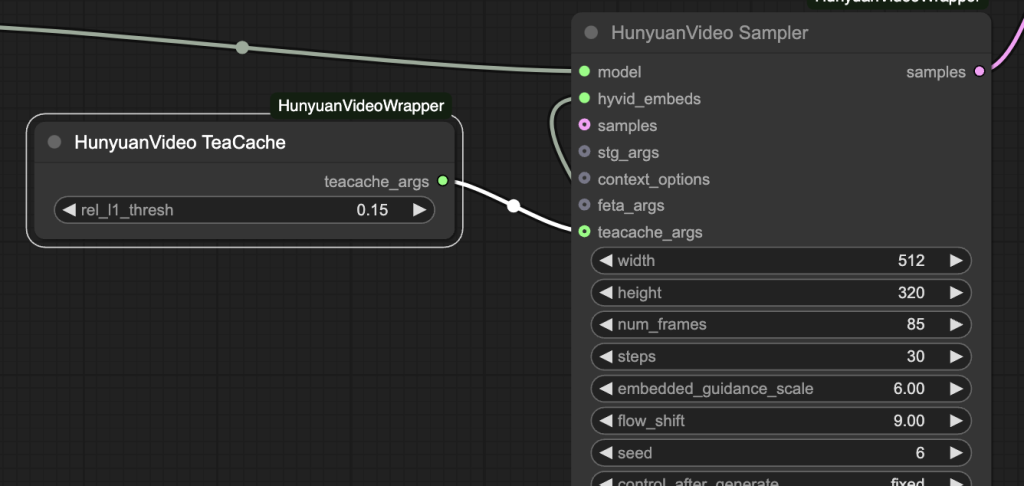
이렇게 하면 생성시간이 거의 절반으로 줄어들게 됩니다.
| 임계값 | 비디오 생성 시간(4090) | 비디오 생성시간(3070) |
| 0.0(off) | 140초 | 2시간 |
| 0.2 | 76초 | 3시간 20분 |
그런데... RTX3070에서 돌리면 2시간이 걸린다고 나오네요. 전에도 말씀드렸지만, 그냥 848x480(480p) 73 프레임을 생성하는데 RTX3070에서 13.8분이 걸리는데, ComfyUI-HunyuanVideoWrapper를 사용하면 2시간 걸린다는 거는 정말 이해가 안되네요. ㅠㅠ 그나마 TeaCache를 사용하니 시간이 줄어들기는 하네요.
1 단계: 모델 다운로드
비디오 모델
hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors 를 다운로드 받아, ComfyUI\models\diffusion_models에 넣어줍니다.
VAE 모델
hunyuan_video_vae_bf16.safetensors 을 다운로드 받아, ComfyUI\models\vae에 넣어주고, hunyuan_video_vae_bf16-kj.safetensors로 이름을 바꿔줍니다. 이 파일은 hunyuan-text-to-video 에서 사용하는 파일과 다르다는 점에 유의하셔야 합니다.
2 단계: 워크플로 불러오기
아래의 JSON 파일을 ComfyUI에 불러옵니다. 좌측위의 Workflow->Open 메뉴를 사용하면 됩니다.
이 워크플로는 대부분 그냥 그대로 사용할 수 있지만, 때때로 오류가 발생할 수 있습니다. 그러한 경우, 다음과 같은 작업이 필요할 수 있습니다.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
3 단계: 비디오 생성
이제 "Queue" 버튼을 누르면 비디오가 생성됩니다.

이상입니다.
이 글은 stable-diffusion-art.com의 글을 번역하면서 제 테스트 결과로 대체하여 작성한 글입니다.
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기