Wan 2.1 Video는 일련의 개방형 인공지능 비디오 생성 모델입니다. 이 모델은 다양한 비디오 생성을 지원합니다. 텍스트-이미지 및 이미지-비디오를 지원할 뿐 아니라, 특히 480p(720x480) 또는 720p(1280x720) 해상도의 비디오를 생성할 수 있습니다.
소프트웨어
이 글에서는 스테이블 디퓨전용 GUI중에서도 제일 강력하며, 현재 거의 대세로 자리잡고 있는 ComfyUI를 사용합니다. ComfyUI가 처음이시라면, 설치 및 기본 사용방법 및 초보가이드를 확인하시기 바랍니다.
Wan 2.1 샘플 비디오
아래의 남자가 나타나는 비디오는 이미지-비디오 방식으로 생성한 것이며, 고양이 쿵푸 비디오는 텍스트-비디오 방식으로 생성한 것입니다. 당연히 720p 비디오는 480p 비디오보다 품질이 좋습니다. 그런데 480p 비디오를 잘 보시면 여기저기 원하지 않는 점이 나타나는 등 약간의 결함이 나타나기도 합니다.
720p 비디오


480p 비디오


Wan 2.1 모델이란
Wan AI사에서 공개한 Wan 2.1은 이미지 또는 텍스트로부터 비디오를 생성할 수 있는 여러가지 비디오 모델 집합입니다.
- 텍스트- 비디오 14B 모델 : 480p 및 720p 지원
- 이미지-비디오 14B 720p 모델: 720p 지원
- 이미지-비디오 14B 480p 모델: 480p 지원
- 텍스트-비디오 1.3B 모델: 480p 지원
가장 흥미로운 것은 720p 이미지-비디오 모델입니다. 이 모델을 사용할 경우, FLUX AI와 같은 고품질 텍스트-비디오 모델로부터 생성한 이미지를 고품질 비디오로 생성할 수 있습니다. 또한 1.3B 모델은 파라미터의 수가 1/10 정도이기 때문에 3070에서도 빠르게 수행시킬 수 있는 장점이 있습니다.
참고로, 이 글에서 사용하고 있는 모델은 모두 fp8 버전이라서 별도로 GGUF 모델을 구하지 않아도 3070에서 작동이 됩니다.
모델 아키텍처
현재 관련 논문이 공개되지 않았습니다. 곧 나온다고 하니 지켜봐야겠습니다.
핵심 기능
Wan 2.1은 텍스트-비디오, 이미지-비디오, 비디오 편집, 텍스트-이미지, 비디오-오디오 등 다양한 기능을 제공합니다. 이에 대한 자세한 내용은 알리바바, Wan 2.1 공개를 읽어보시기 바랍니다.
이미지-비디오(Image-to-Video) 따라하기
이 워크플로는 2.3초 길이의 720p (1280*720) MP4 비디오를 생성하는 워크플로입니다. 이를 사용하려면 텍스트 프롬프트와 이미지를 입력해야 합니다. 4090 에서 실행시켰을 경우, 약 23분 정도 소요된다고 합니다. RTX 3070에서 실행시키니 2시간 정도 걸리네요.

1 단계: 모델 다운로드
아래의 모델을 다운로드 받아 ComfyUI > models > diffusion_models 폴더에 넣어줍니다.
아래의 텍스트 인코더 모델을 다운로드 받아 ComfyUI > models > text_encoders 폴더에 넣어줍니다.
아래의 CLIP vision 모델을 다운로드 받아 ComfyUI > models > clip_vision 폴더에 넣어줍니다.
아래의 Wan VAE 모델을 다운로드 받아 ComfyUI > models > vae 폴더에 넣어줍니다.
2 단계: 워크플로 불러오기
아래의 Json 파일을 다운로드 받아 ComfyUI로 불러옵니다.
이 워크플로를 불러오면 대부분 오류가 발생할 것입니다. 그러한 경우, 다음과 같은 작업이 필요합니다.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
3 단계: 이미지 설정
아래와 같이 비디오 첫 프레임으로 사용할 이미지를 선택합니다.
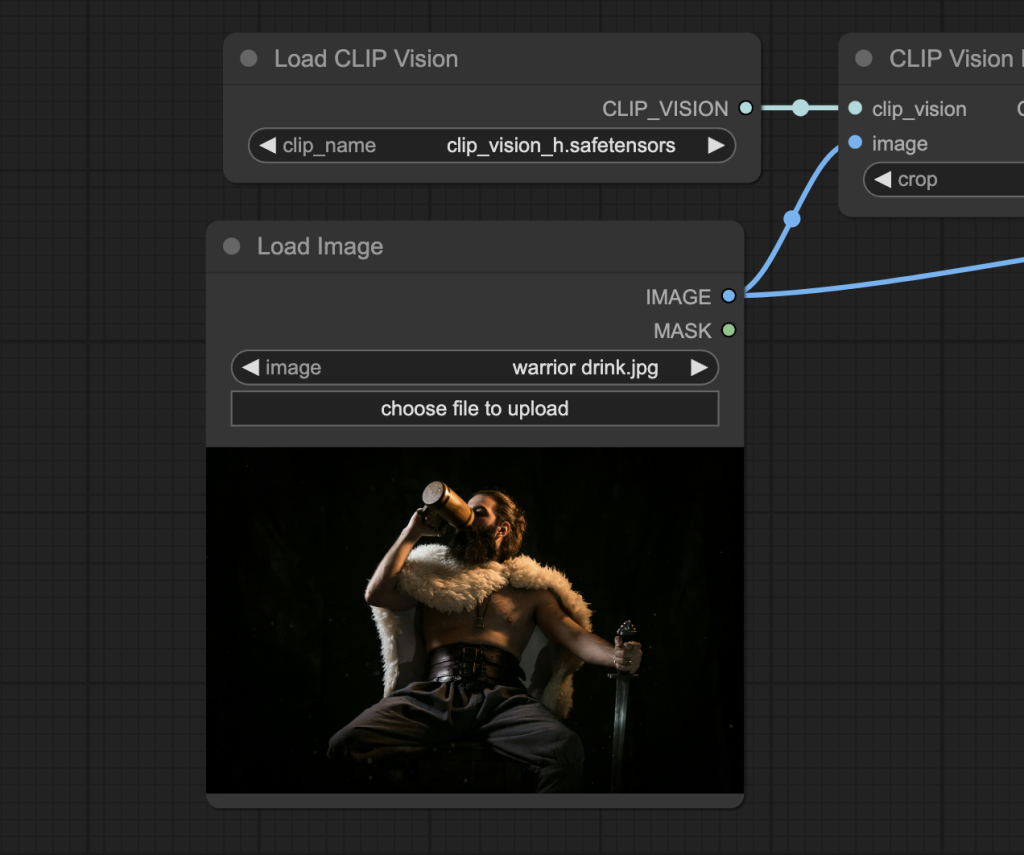
아래의 이미지를 다운로드 받아서 사용하셔도 됩니다.
{kind=link}
4 단계: 프롬프트 검토
프롬프트에는 입력한 이미지와 맞는 내용을 추가하여야 합니다. 다음 사항을 참고하세요.
- 그냥 입력 이미지 설명만 입력하면 안되고, 그다음에 어떤 행동을 할지를 입력하는 것이 좋습니다.
- 행동에 관한 단어를 추가하면 좋습니다. 예: 웃음(laugh), 달리기(run), 싸우기(fight) 등
- 부정적 프롬프트는 그냥 두셔도 됩니다.

5 단계: 비디오 생성
이제 [Queue] 버튼을 누르면 비디오가 생성됩니다. 아래는 생성되는 비디오의 예입니다.

참고: 480p 이미지-비디오 워크플로
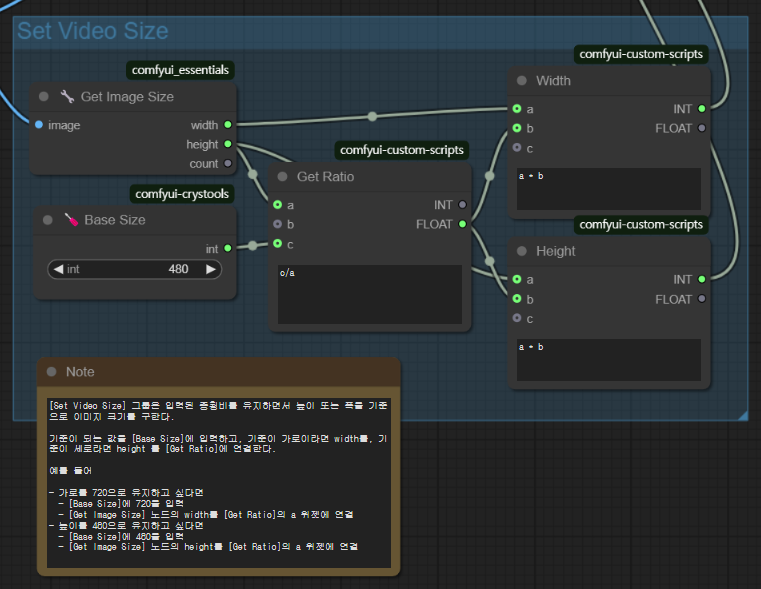
위의 워크플로를 사용하여 480p(720*480) 비디오를 생성할 수 있습니다. 아래 그림과 같이 [Set Video Size] 그룹에서 height높이를 480으로 설정한 후 [Generate]을 누르면 비디오가 생성됩니다. 이 워크플로를 RTX 3070에서 돌리면 샘플링 시간만 20분 정도가 소요되네요. 그래도 이 정도면 쓸만한 것 같네요.
텍스트-비디오(Text-to-Video) 따라하기
이 워크플로는 텍스트 설명을 2.3초 길이의 480p (720*480) MP4 비디오를 생성하는 워크플로입니다. RTX 3070으로 대략 15분 정도 소요되네요.
1 단계: 모델 다운로드
아래의 모델을 다운로드 받아 ComfyUI > models > diffusion_models 폴더에 넣어줍니다.
텍스트 인코더 모델, CLIP vision 모델, Wan VAE 모델은 위에서 다운로드 받은 모델과 동일합니다.
2 단계: 워크플로 불러오기
아래의 Json 파일을 다운로드 받아 ComfyUI로 불러옵니다.
이 워크플로를 불러오면 대부분 오류가 발생할 것입니다. 그러한 경우, 다음과 같은 작업이 필요합니다.
- 처음 사용할 때 - ComfyUI Manager 를 설치해야 합니다.
- ComfyUI를 오랜만에 사용할 때 - ComfyUI를 최신버전으로 업데이트해야 합니다.
- 노드가 없다고 (빨간색) 경고가 뜰 때 - 빠진 커스톰 노드를 가져오기해야 합니다.
- 불러오기 혹은 수행중 에러 발생시 - 커스톰 노드를 업데이트해야 합니다.
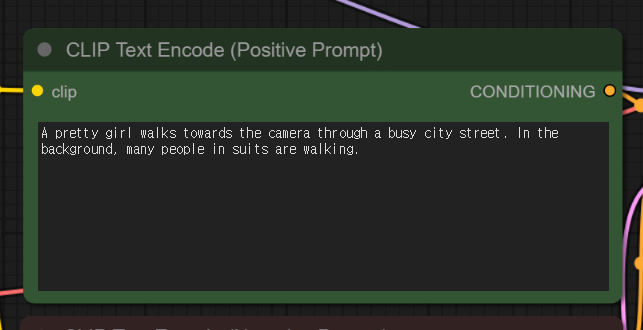
3 단계: 프롬프트 검토
프롬프트에 원하는 텍스트 설명을 입력합니다.
4 단계: 비디오 생성
이제 [Queue] 버튼을 누르면 비디오가 생성됩니다. 아래는 생성되는 비디오의 예입니다.

Fast 480 텍스트-비디오 워크플로
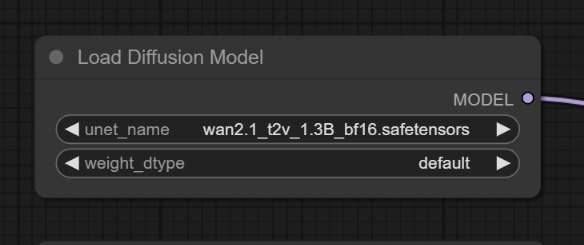
이 워크플로에서는 크기가 작은 디퓨전 모델을 사용합니다. wan2.1_t2v_1.3B_bf16.safetensors 을 다운로드 받아 ComfyUI\models\diffusion_models 폴더에 넣어주고, 아래와 같이 [Load Diffusion Model]에서 지정한 뒤 실행시키면 됩니다.
아래는 이렇게 해서 생성한 비디오입니다.

그리고 아래는 81 프레임(약 5초)로 늘려서 생성한 비디오입니다. 2 GB 정도 크기의 모델임에도 정말 괜찮게 나오네요.

이상입니다.
이 글은 stable-diffusion-art.com의 글을 번역하면서 제 테스트 결과로 대체하여 작성한 글입니다.
- ComfyUI로 설치 및 사용법 기초
- ComfyUI 투토리얼
- ComfyUI를 위한 유용한 정보
- ComfyUI와 SDXL 사용법(1) - 기초
- ComfyUI에서 ControlNet 사용법
- 편리한 ComfyUI 워크플로 모음
- LCM-LoRA - 초고속 스테이블 디퓨전
- Stable Video Diffusion(비디오 스테이블 디퓨전)
- Stable Diffusion 인공지능 이미지 생초보 가이드
- Stable Diffusion 대표 UI - AUTOMATIC1111 설치방법
- Automatic1111 GUI: 초보자 가이드(메뉴 해설)
- Stable Diffusion에 대한 기본적인 이론
- ChatGPT로 스테이블 디퓨전 프롬프트 만들기